 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReduce Meaningless Words for Joint Chinese Word Segmentation and Part-of-speech Tagging
May 25, 2013


Conventional statistics-based methods for joint Chinese word segmentation and part-of-speech tagging (S&T) have generalization ability to recognize new words that do not appear in the training data. An undesirable side effect is that a number of meaningless words will be incorrectly created. We propose an effective and efficient framework for S&T that introduces features to significantly reduce meaningless words generation. A general lexicon, Wikepedia and a large-scale raw corpus of 200 billion characters are used to generate word-based features for the wordhood. The word-lattice based framework consists of a character-based model and a word-based model in order to employ our word-based features. Experiments on Penn Chinese treebank 5 show that this method has a 62.9% reduction of meaningless word generation in comparison with the baseline. As a result, the F1 measure for segmentation is increased to 0.984.
Binary Tree based Chinese Word Segmentation
May 17, 2013
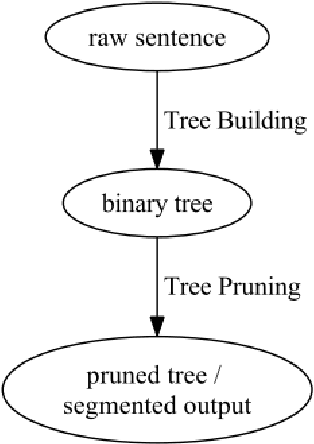
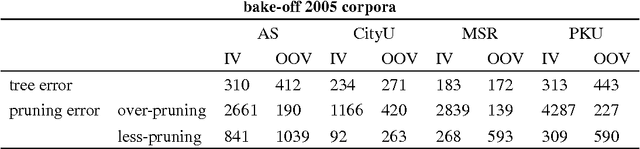
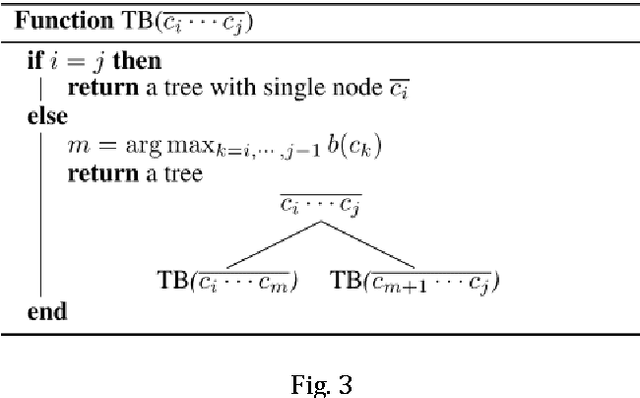
Chinese word segmentation is a fundamental task for Chinese language processing. The granularity mismatch problem is the main cause of the errors. This paper showed that the binary tree representation can store outputs with different granularity. A binary tree based framework is also designed to overcome the granularity mismatch problem. There are two steps in this framework, namely tree building and tree pruning. The tree pruning step is specially designed to focus on the granularity problem. Previous work for Chinese word segmentation such as the sequence tagging can be easily employed in this framework. This framework can also provide quantitative error analysis methods. The experiments showed that after using a more sophisticated tree pruning function for a state-of-the-art conditional random field based baseline, the error reduction can be up to 20%.