 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Prediction for Limited-angle Tomography via Deep Learning with Convolutional Neural Network
Jul 29, 2016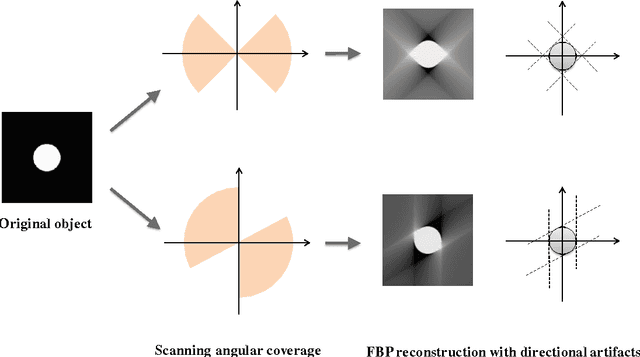

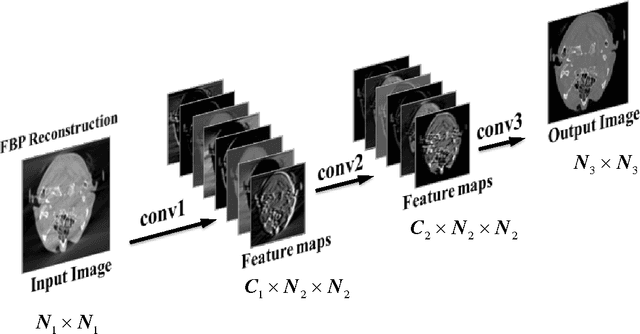
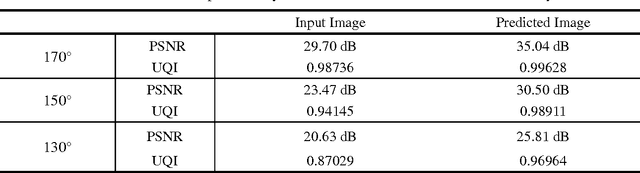
Limited angle problem is a challenging issue in x-ray computed tomography (CT) field. Iterative reconstruction methods that utilize the additional prior can suppress artifacts and improve image quality, but unfortunately require increased computation time. An interesting way is to restrain the artifacts in the images reconstructed from the practical filtered back projection (FBP) method. Frikel and Quinto have proved that the streak artifacts in FBP results could be characterized. It indicates that the artifacts created by FBP method have specific and similar characteristics in a stationary limited-angle scanning configuration. Based on this understanding, this work aims at developing a method to extract and suppress specific artifacts of FBP reconstructions for limited-angle tomography. A data-driven learning-based method is proposed based on a deep convolutional neural network. An end-to-end mapping between the FBP and artifact-free images is learned and the implicit features involving artifacts will be extracted and suppressed via nonlinear mapping. The qualitative and quantitative evaluations of experimental results indicate that the proposed method show a stable and prospective performance on artifacts reduction and detail recovery for limited angle tomography. The presented strategy provides a simple and efficient approach for improving image quality of the reconstruction results from limited projection data.