 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAD: A Dataset and Benchmark for Real-Life Anomaly Detection with Robotic Observations
Oct 01, 2024



Recent advancements in industrial anomaly detection have been hindered by the lack of realistic datasets that accurately represent real-world conditions. Existing algorithms are often developed and evaluated using idealized datasets, which deviate significantly from real-life scenarios characterized by environmental noise and data corruption such as fluctuating lighting conditions, variable object poses, and unstable camera positions. To address this gap, we introduce the Realistic Anomaly Detection (RAD) dataset, the first multi-view RGB-based anomaly detection dataset specifically collected using a real robot arm, providing unique and realistic data scenarios. RAD comprises 4765 images across 13 categories and 4 defect types, collected from more than 50 viewpoints, providing a comprehensive and realistic benchmark. This multi-viewpoint setup mirrors real-world conditions where anomalies may not be detectable from every perspective. Moreover, by sampling varying numbers of views, the algorithm's performance can be comprehensively evaluated across different viewpoints. This approach enhances the thoroughness of performance assessment and helps improve the algorithm's robustness. Besides, to support 3D multi-view reconstruction algorithms, we propose a data augmentation method to improve the accuracy of pose estimation and facilitate the reconstruction of 3D point clouds. We systematically evaluate state-of-the-art RGB-based and point cloud-based models using RAD, identifying limitations and future research directions. The code and dataset could found at https://github.com/kaichen-z/RAD
Distributed Clustering based on Distributional Kernel
Sep 14, 2024



This paper introduces a new framework for clustering in a distributed network called Distributed Clustering based on Distributional Kernel (K) or KDC that produces the final clusters based on the similarity with respect to the distributions of initial clusters, as measured by K. It is the only framework that satisfies all three of the following properties. First, KDC guarantees that the combined clustering outcome from all sites is equivalent to the clustering outcome of its centralized counterpart from the combined dataset from all sites. Second, the maximum runtime cost of any site in distributed mode is smaller than the runtime cost in centralized mode. Third, it is designed to discover clusters of arbitrary shapes, sizes and densities. To the best of our knowledge, this is the first distributed clustering framework that employs a distributional kernel. The distribution-based clustering leads directly to significantly better clustering outcomes than existing methods of distributed clustering. In addition, we introduce a new clustering algorithm called Kernel Bounded Cluster Cores, which is the best clustering algorithm applied to KDC among existing clustering algorithms. We also show that KDC is a generic framework that enables a quadratic time clustering algorithm to deal with large datasets that would otherwise be impossible.
Anomaly Detection Based on Isolation Mechanisms: A Survey
Mar 16, 2024Anomaly detection is a longstanding and active research area that has many applications in domains such as finance, security, and manufacturing. However, the efficiency and performance of anomaly detection algorithms are challenged by the large-scale, high-dimensional, and heterogeneous data that are prevalent in the era of big data. Isolation-based unsupervised anomaly detection is a novel and effective approach for identifying anomalies in data. It relies on the idea that anomalies are few and different from normal instances, and thus can be easily isolated by random partitioning. Isolation-based methods have several advantages over existing methods, such as low computational complexity, low memory usage, high scalability, robustness to noise and irrelevant features, and no need for prior knowledge or heavy parameter tuning. In this survey, we review the state-of-the-art isolation-based anomaly detection methods, including their data partitioning strategies, anomaly score functions, and algorithmic details. We also discuss some extensions and applications of isolation-based methods in different scenarios, such as detecting anomalies in streaming data, time series, trajectory, and image datasets. Finally, we identify some open challenges and future directions for isolation-based anomaly detection research.
Distribution-Based Trajectory Clustering
Oct 08, 2023Trajectory clustering enables the discovery of common patterns in trajectory data. Current methods of trajectory clustering rely on a distance measure between two points in order to measure the dissimilarity between two trajectories. The distance measures employed have two challenges: high computational cost and low fidelity. Independent of the distance measure employed, existing clustering algorithms have another challenge: either effectiveness issues or high time complexity. In this paper, we propose to use a recent Isolation Distributional Kernel (IDK) as the main tool to meet all three challenges. The new IDK-based clustering algorithm, called TIDKC, makes full use of the distributional kernel for trajectory similarity measuring and clustering. TIDKC identifies non-linearly separable clusters with irregular shapes and varied densities in linear time. It does not rely on random initialisation and is robust to outliers. An extensive evaluation on 7 large real-world trajectory datasets confirms that IDK is more effective in capturing complex structures in trajectories than traditional and deep learning-based distance measures. Furthermore, the proposed TIDKC has superior clustering performance and efficiency to existing trajectory clustering algorithms.
Subgraph Centralization: A Necessary Step for Graph Anomaly Detection
Jan 17, 2023



Graph anomaly detection has attracted a lot of interest recently. Despite their successes, existing detectors have at least two of the three weaknesses: (a) high computational cost which limits them to small-scale networks only; (b) existing treatment of subgraphs produces suboptimal detection accuracy; and (c) unable to provide an explanation as to why a node is anomalous, once it is identified. We identify that the root cause of these weaknesses is a lack of a proper treatment for subgraphs. A treatment called Subgraph Centralization for graph anomaly detection is proposed to address all the above weaknesses. Its importance is shown in two ways. First, we present a simple yet effective new framework called Graph-Centric Anomaly Detection (GCAD). The key advantages of GCAD over existing detectors including deep-learning detectors are: (i) better anomaly detection accuracy; (ii) linear time complexity with respect to the number of nodes; and (iii) it is a generic framework that admits an existing point anomaly detector to be used to detect node anomalies in a network. Second, we show that Subgraph Centralization can be incorporated into two existing detectors to overcome the above-mentioned weaknesses.
A principled distributional approach to trajectory similarity measurement
Jan 01, 2023Existing measures and representations for trajectories have two longstanding fundamental shortcomings, i.e., they are computationally expensive and they can not guarantee the `uniqueness' property of a distance function: dist(X,Y) = 0 if and only if X=Y, where $X$ and $Y$ are two trajectories. This paper proposes a simple yet powerful way to represent trajectories and measure the similarity between two trajectories using a distributional kernel to address these shortcomings. It is a principled approach based on kernel mean embedding which has a strong theoretical underpinning. It has three distinctive features in comparison with existing approaches. (1) A distributional kernel is used for the very first time for trajectory representation and similarity measurement. (2) It does not rely on point-to-point distances which are used in most existing distances for trajectories. (3) It requires no learning, unlike existing learning and deep learning approaches. We show the generality of this new approach in three applications: (a) trajectory anomaly detection, (b) anomalous sub-trajectory detection, and (c) trajectory pattern mining. We identify that the distributional kernel has (i) a unique data-dependent property and the above uniqueness property which are the key factors that lead to its superior task-specific performance; and (ii) runtime orders of magnitude faster than existing distance measures.
Detecting Change Intervals with Isolation Distributional Kernel
Dec 30, 2022



Detecting abrupt changes in data distribution is one of the most significant tasks in streaming data analysis. Although many unsupervised Change-Point Detection (CPD) methods have been proposed recently to identify those changes, they still suffer from missing subtle changes, poor scalability, or/and sensitive to noise points. To meet these challenges, we are the first to generalise the CPD problem as a special case of the Change-Interval Detection (CID) problem. Then we propose a CID method, named iCID, based on a recent Isolation Distributional Kernel (IDK). iCID identifies the change interval if there is a high dissimilarity score between two non-homogeneous temporal adjacent intervals. The data-dependent property and finite feature map of IDK enabled iCID to efficiently identify various types of change points in data streams with the tolerance of noise points. Moreover, the proposed online and offline versions of iCID have the ability to optimise key parameter settings. The effectiveness and efficiency of iCID have been systematically verified on both synthetic and real-world datasets.
Breaking the curse of dimensionality with Isolation Kernel
Sep 29, 2021
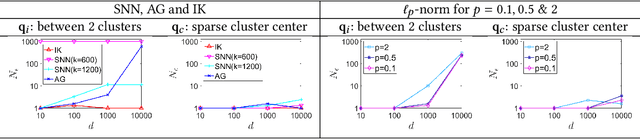
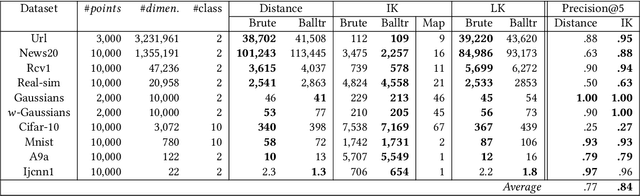
The curse of dimensionality has been studied in different aspects. However, breaking the curse has been elusive. We show for the first time that it is possible to break the curse using the recently introduced Isolation Kernel. We show that only Isolation Kernel performs consistently well in indexed search, spectral & density peaks clustering, SVM classification and t-SNE visualization in both low and high dimensions, compared with distance, Gaussian and linear kernels. This is also supported by our theoretical analyses that Isolation Kernel is the only kernel that has the provable ability to break the curse, compared with existing metric-based Lipschitz continuous kernels.
The Impact of Isolation Kernel on Agglomerative Hierarchical Clustering Algorithms
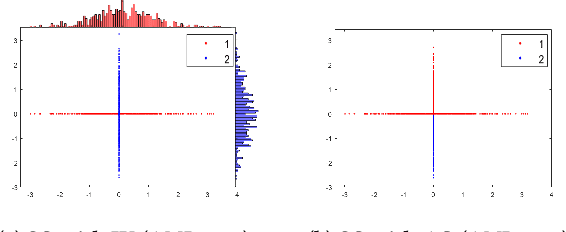
Oct 12, 2020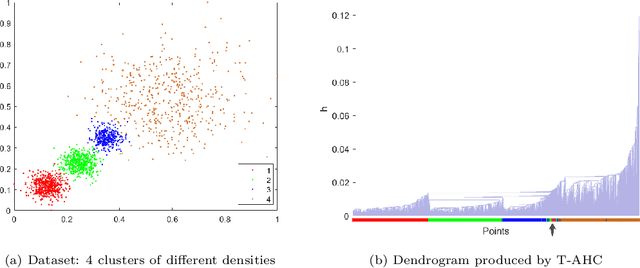
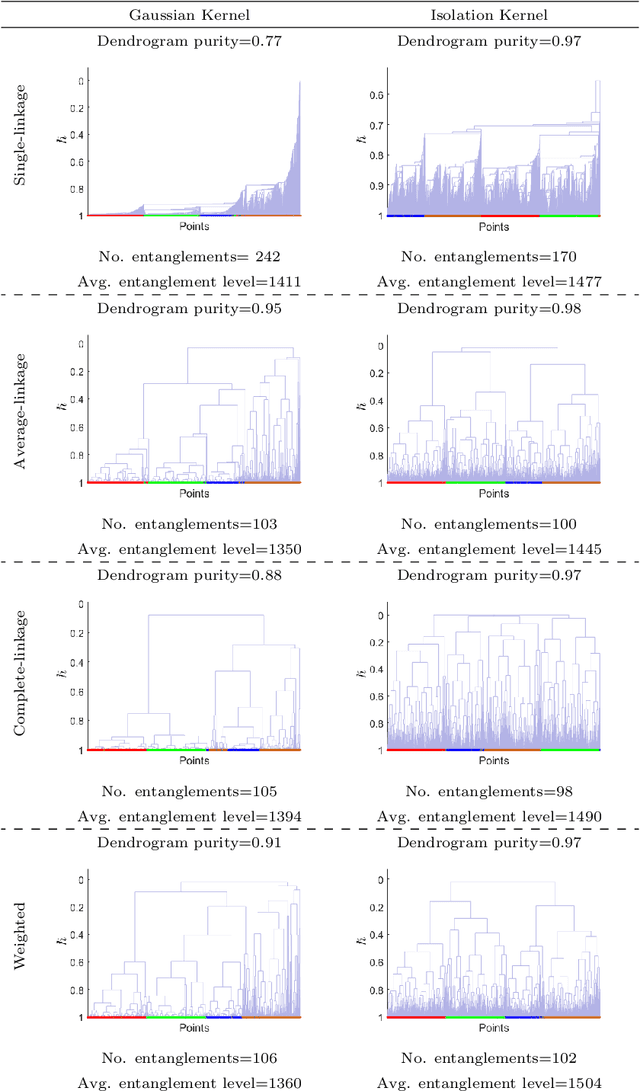
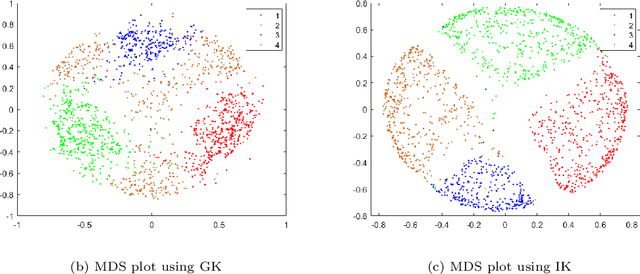
Agglomerative hierarchical clustering (AHC) is one of the popular clustering approaches. Existing AHC methods, which are based on a distance measure, have one key issue: it has difficulty in identifying adjacent clusters with varied densities, regardless of the cluster extraction methods applied on the resultant dendrogram. In this paper, we identify the root cause of this issue and show that the use of a data-dependent kernel (instead of distance or existing kernel) provides an effective means to address it. We analyse the condition under which existing AHC methods fail to extract clusters effectively; and the reason why the data-dependent kernel is an effective remedy. This leads to a new approach to kernerlise existing hierarchical clustering algorithms such as existing traditional AHC algorithms, HDBSCAN, GDL and PHA. In each of these algorithms, our empirical evaluation shows that a recently introduced Isolation Kernel produces a higher quality or purer dendrogram than distance, Gaussian Kernel and adaptive Gaussian Kernel.
Isolation Distributional Kernel: A New Tool for Point & Group Anomaly Detection
Sep 24, 2020
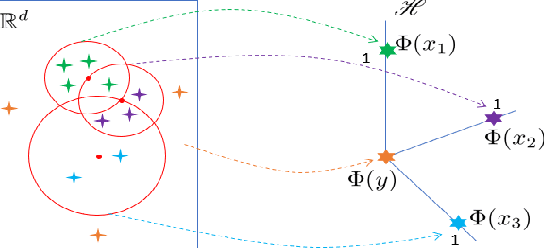
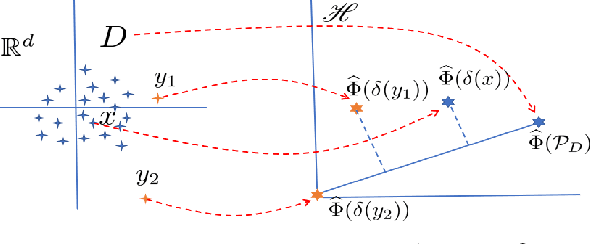
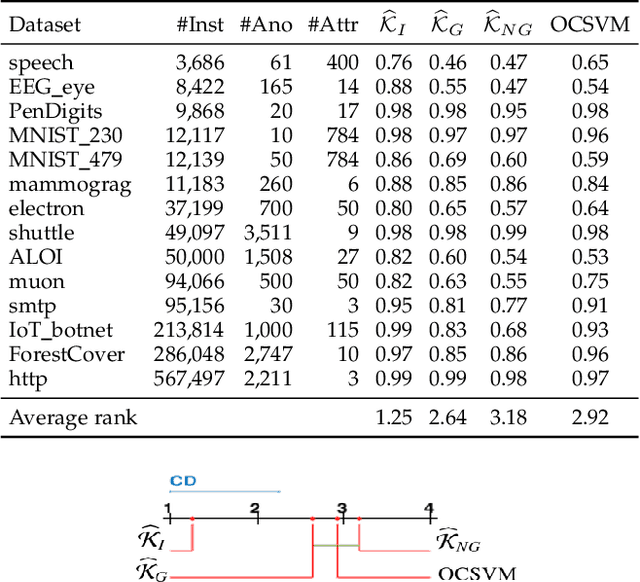
We introduce Isolation Distributional Kernel as a new way to measure the similarity between two distributions. Existing approaches based on kernel mean embedding, which convert a point kernel to a distributional kernel, have two key issues: the point kernel employed has a feature map with intractable dimensionality; and it is {\em data independent}. This paper shows that Isolation Distributional Kernel (IDK), which is based on a {\em data dependent} point kernel, addresses both key issues. We demonstrate IDK's efficacy and efficiency as a new tool for kernel based anomaly detection for both point and group anomalies. Without explicit learning, using IDK alone outperforms existing kernel based point anomaly detector OCSVM and other kernel mean embedding methods that rely on Gaussian kernel. For group anomaly detection,we introduce an IDK based detector called IDK$^2$. It reformulates the problem of group anomaly detection in input space into the problem of point anomaly detection in Hilbert space, without the need for learning. IDK$^2$ runs orders of magnitude faster than group anomaly detector OCSMM.We reveal for the first time that an effective kernel based anomaly detector based on kernel mean embedding must employ a characteristic kernel which is data dependent.