 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Adaptive Weight Noise
Jul 19, 2015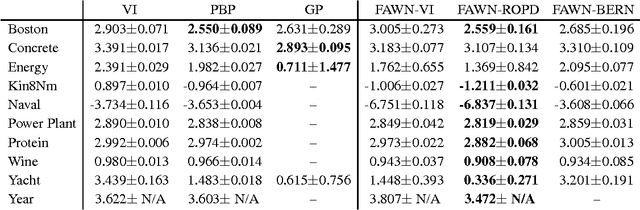
Marginalising out uncertain quantities within the internal representations or parameters of neural networks is of central importance for a wide range of learning techniques, such as empirical, variational or full Bayesian methods. We set out to generalise fast dropout (Wang & Manning, 2013) to cover a wider variety of noise processes in neural networks. This leads to an efficient calculation of the marginal likelihood and predictive distribution which evades sampling and the consequential increase in training time due to highly variant gradient estimates. This allows us to approximate variational Bayes for the parameters of feed-forward neural networks. Inspired by the minimum description length principle, we also propose and experimentally verify the direct optimisation of the regularised predictive distribution. The methods yield results competitive with previous neural network based approaches and Gaussian processes on a wide range of regression tasks.
Learning Stochastic Recurrent Networks
Mar 05, 2015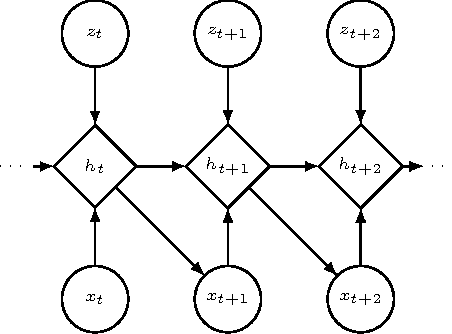

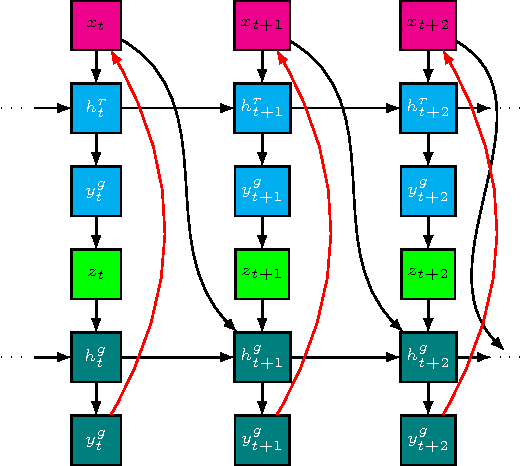
Leveraging advances in variational inference, we propose to enhance recurrent neural networks with latent variables, resulting in Stochastic Recurrent Networks (STORNs). The model i) can be trained with stochastic gradient methods, ii) allows structured and multi-modal conditionals at each time step, iii) features a reliable estimator of the marginal likelihood and iv) is a generalisation of deterministic recurrent neural networks. We evaluate the method on four polyphonic musical data sets and motion capture data.
Regularizing Recurrent Networks - On Injected Noise and Norm-based Methods
Oct 21, 2014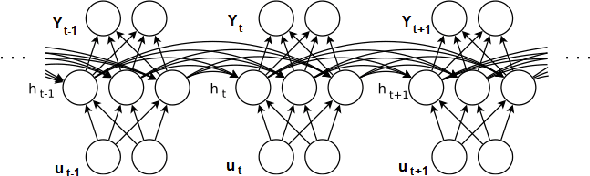
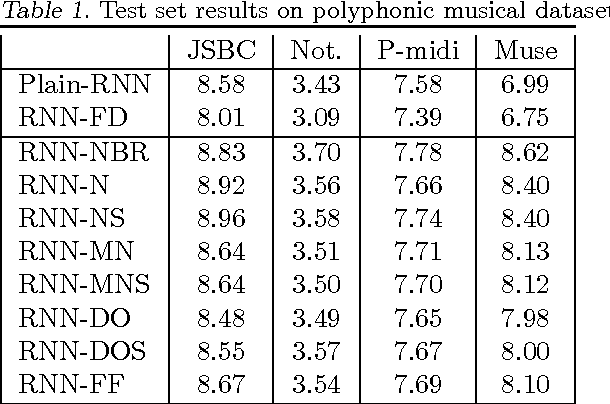
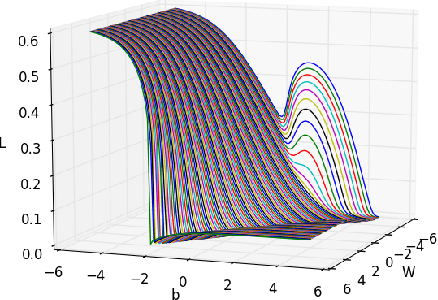
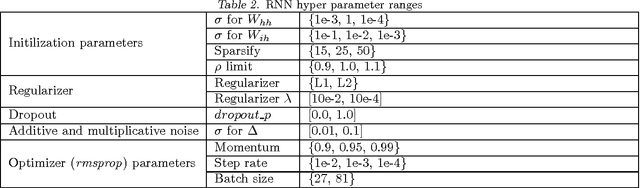
Advancements in parallel processing have lead to a surge in multilayer perceptrons' (MLP) applications and deep learning in the past decades. Recurrent Neural Networks (RNNs) give additional representational power to feedforward MLPs by providing a way to treat sequential data. However, RNNs are hard to train using conventional error backpropagation methods because of the difficulty in relating inputs over many time-steps. Regularization approaches from MLP sphere, like dropout and noisy weight training, have been insufficiently applied and tested on simple RNNs. Moreover, solutions have been proposed to improve convergence in RNNs but not enough to improve the long term dependency remembering capabilities thereof. In this study, we aim to empirically evaluate the remembering and generalization ability of RNNs on polyphonic musical datasets. The models are trained with injected noise, random dropout, norm-based regularizers and their respective performances compared to well-initialized plain RNNs and advanced regularization methods like fast-dropout. We conclude with evidence that training with noise does not improve performance as conjectured by a few works in RNN optimization before ours.
Variational inference of latent state sequences using Recurrent Networks
Sep 30, 2014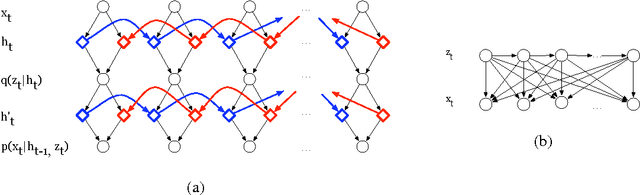

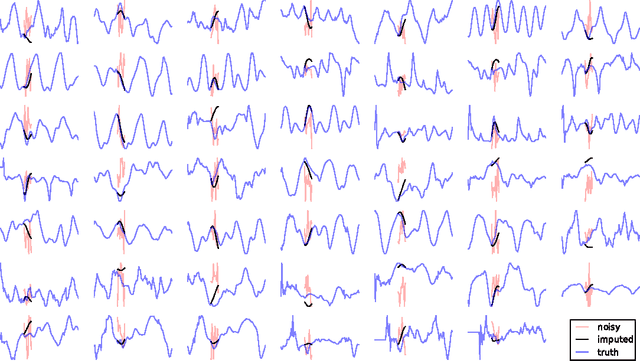
Recent advances in the estimation of deep directed graphical models and recurrent networks let us contribute to the removal of a blind spot in the area of probabilistc modelling of time series. The proposed methods i) can infer distributed latent state-space trajectories with nonlinear transitions, ii) scale to large data sets thanks to the use of a stochastic objective and fast, approximate inference, iii) enable the design of rich emission models which iv) will naturally lead to structured outputs. Two different paths of introducing latent state sequences are pursued, leading to the variational recurrent auto encoder (VRAE) and the variational one step predictor (VOSP). The use of independent Wiener processes as priors on the latent state sequence is a viable compromise between efficient computation of the Kullback-Leibler divergence from the variational approximation of the posterior and maintaining a reasonable belief in the dynamics. We verify our methods empirically, obtaining results close or superior to the state of the art. We also show qualitative results for denoising and missing value imputation.
On Fast Dropout and its Applicability to Recurrent Networks
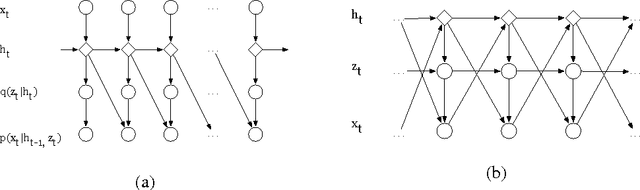
Mar 05, 2014
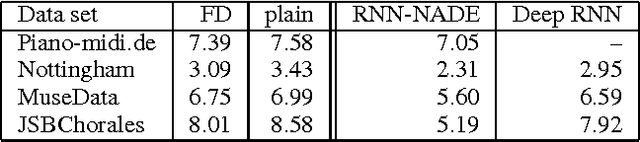
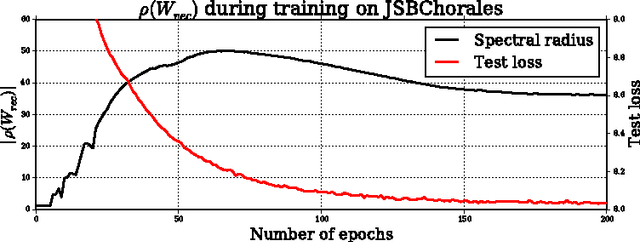

Recurrent Neural Networks (RNNs) are rich models for the processing of sequential data. Recent work on advancing the state of the art has been focused on the optimization or modelling of RNNs, mostly motivated by adressing the problems of the vanishing and exploding gradients. The control of overfitting has seen considerably less attention. This paper contributes to that by analyzing fast dropout, a recent regularization method for generalized linear models and neural networks from a back-propagation inspired perspective. We show that fast dropout implements a quadratic form of an adaptive, per-parameter regularizer, which rewards large weights in the light of underfitting, penalizes them for overconfident predictions and vanishes at minima of an unregularized training loss. The derivatives of that regularizer are exclusively based on the training error signal. One consequence of this is the absense of a global weight attractor, which is particularly appealing for RNNs, since the dynamics are not biased towards a certain regime. We positively test the hypothesis that this improves the performance of RNNs on four musical data sets.
Learning Sequence Neighbourhood Metrics
Aug 22, 2013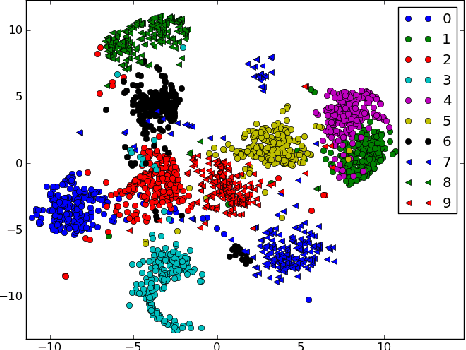
Recurrent neural networks (RNNs) in combination with a pooling operator and the neighbourhood components analysis (NCA) objective function are able to detect the characterizing dynamics of sequences and embed them into a fixed-length vector space of arbitrary dimensionality. Subsequently, the resulting features are meaningful and can be used for visualization or nearest neighbour classification in linear time. This kind of metric learning for sequential data enables the use of algorithms tailored towards fixed length vector spaces such as R^n.
Convolutional Neural Networks learn compact local image descriptors
Jun 02, 2013
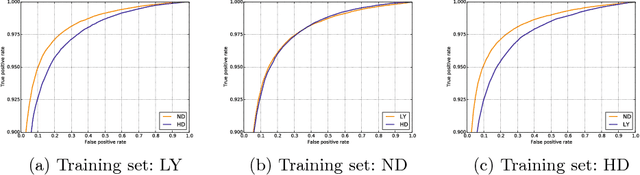
A standard deep convolutional neural network paired with a suitable loss function learns compact local image descriptors that perform comparably to state-of-the art approaches.
Unsupervised Feature Learning for low-level Local Image Descriptors
Apr 25, 2013
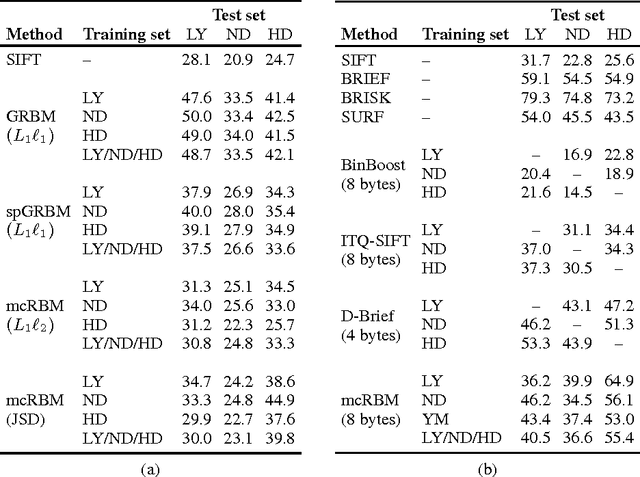

Unsupervised feature learning has shown impressive results for a wide range of input modalities, in particular for object classification tasks in computer vision. Using a large amount of unlabeled data, unsupervised feature learning methods are utilized to construct high-level representations that are discriminative enough for subsequently trained supervised classification algorithms. However, it has never been \emph{quantitatively} investigated yet how well unsupervised learning methods can find \emph{low-level representations} for image patches without any additional supervision. In this paper we examine the performance of pure unsupervised methods on a low-level correspondence task, a problem that is central to many Computer Vision applications. We find that a special type of Restricted Boltzmann Machines (RBMs) performs comparably to hand-crafted descriptors. Additionally, a simple binarization scheme produces compact representations that perform better than several state-of-the-art descriptors.