 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Managed Long-Context Attention: A Preliminary Study of Editable Request-Local Memory
Jun 27, 2026Long-context language models often conflate two different goals: compressing history into an efficient state, and maintaining reliable long-term memory. Linear, recurrent, and sparse attention reduce the cost of processing long sequences, but they do not by themselves specify when a fact should be written, overwritten, protected from distractors, or discarded. We study memory-managed long-context attention, a research route that separates a fast recurrent or sparse backbone from explicit editable request-local memory slots and query-time sparse fallback. Across structured synthetic tasks, token/chunk/sequence bridges, generated natural language, and local frozen-model diagnostics, pure fixed-state or pure sparse methods fail some overwrite, version, anti-pollution, or no-write-signal cases, while a hybrid covers both routes. A small 2,097,152-token mechanism stress test reaches 50/50 pooled accuracy with 2-132 active chunks. A 2.74M-parameter minimal causal event-token model reaches 595/600 with lite write supervision, supporting proof of trainability rather than scale. A six-family frozen-hidden-state bridge reaches 1079/1080 controlled pointer accuracy, but it uses generator-provided integer key IDs and separately encoded canonical key strings; it is an oracle-metadata probe, not open-text entity resolution. Local non-leaderboard RULER 4K diagnostics remain close to full context, whereas a 33-record LongBench v1 16K subset shows that naive lexical selection is not general. The evidence separates three claims: controlled slot lifecycle is feasible, sparse fallback is needed when writes lack future-query signals, and learned open-domain selection remains the main architectural bottleneck. We do not claim a final generative architecture, global slot-trajectory convergence, or systems superiority.
Instruction-Tuned, but Not More Verifiable Instruction-Following: A Cross-Task Diagnosis for LoRA Adapters
Mar 23, 2026Adapters are often selected and deployed based on nominal labels (e.g., instruction-tuned), which implicitly suggest what capability improves after adaptation. We test whether nominal training objectives reliably align with realized cross-task capability gains by evaluating the same LoRA adapter across tasks. Our strongest evidence is tied to strict, automatically verifiable instruction following as measured by IFEval: across multiple seeds, base models, and LoRA settings, nominal labels recurrently but not universally fail to predict improvements on this verifiable target, with clear configuration sensitivity including a near-zero or negative case. As an illustrative strongest-case example in a controlled instruction-versus-numeric setting, an instruction-tuned adapter substantially improves off-target NM-based numeric benchmark performance from 0.133 to 0.632 while not improving verifiable instruction following on IFEval (ILA: 0.313 to 0.271; PLA: 0.250 to 0.143; values rounded to three decimals). We refer to this nominal-versus-realized mismatch pattern as capability drift as a descriptive label. The mismatch is visible in the raw cross-task performance matrix; we use a drift score only as a compact summary in the same units as the underlying metrics, not as a new formal metric contribution. Evidence from broader instruction-following benchmarks is benchmark-dependent and mixed, reflecting heterogeneity in how instruction following is operationalized; we therefore do not treat cross-benchmark agreement as a premise. Overall, the practical takeaway is to perform routine cross-task evaluation before deployment and to avoid treating nominal labels as reliable capability proxies.
When Domain Pretraining Interferes with Instruction Alignment: An Empirical Study of Adapter Merging in Medical LLMs
Jan 26, 2026Large language models (LLMs) show strong general capability but often struggle with medical terminology precision and safety-critical instruction following. We present a case study for adapter interference in safety-critical domains using a 14B-parameter base model through a two-stage LoRA pipeline: (1) domain-adaptive pre-training (PT) to inject broad medical knowledge via continued pre-training (DAPT), and (2) supervised fine-tuning (SFT) to align the model with medical question-answering behaviors through instruction-style data. To balance instruction-following ability and domain knowledge retention, we propose Weighted Adapter Merging, linearly combining SFT and PT adapters before exporting a merged base-model checkpoint. On a held-out medical validation set (F5/F6), the merged model achieves BLEU-4 = 16.38, ROUGE-1 = 20.42, ROUGE-2 = 4.60, and ROUGE-L = 11.54 under a practical decoding configuration. We further analyze decoding sensitivity and training stability with loss curves and controlled decoding comparisons.
Credit Card Fraud Detection Using Autoencoder Neural Network
Aug 30, 2019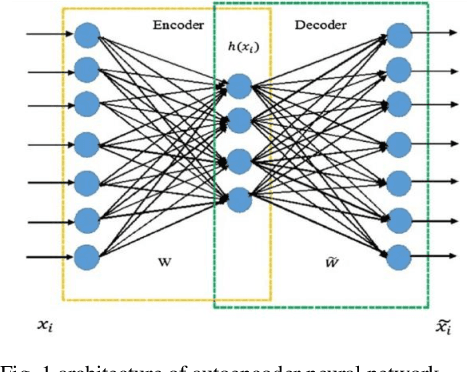
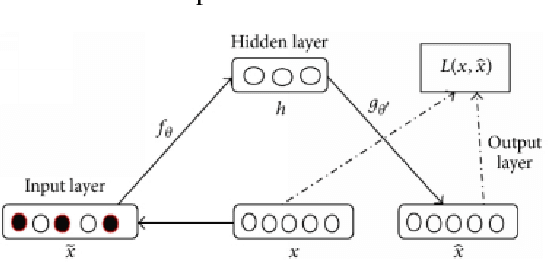

Imbalanced data classification problem has always been a popular topic in the field of machine learning research. In order to balance the samples between majority and minority class. Oversampling algorithm is used to synthesize new minority class samples, but it could bring in noise. Pointing to the noise problems, this paper proposed a denoising autoencoder neural network (DAE) algorithm which can not only oversample minority class sample through misclassification cost, but it can denoise and classify the sampled dataset. Through experiments, compared with the denoising autoencoder neural network (DAE) with oversampling process and traditional fully connected neural networks, the results showed the proposed algorithm improves the classification accuracy of minority class of imbalanced datasets.
Handwritten Chinese Character Recognition by Convolutional Neural Network and Similarity Ranking
Aug 30, 2019

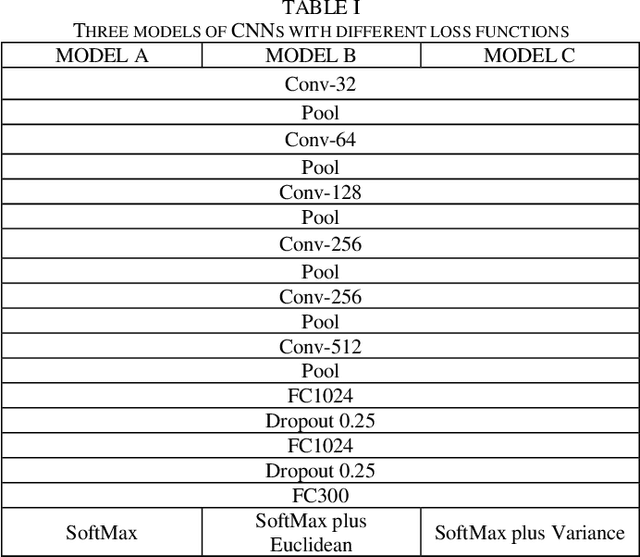
Convolution Neural Networks (CNN) have recently achieved state-of-the art performance on handwritten Chinese character recognition (HCCR). However, most of CNN models employ the SoftMax activation function and minimize cross entropy loss, which may cause loss of inter-class information. To cope with this problem, we propose to combine cross entropy with similarity ranking function and use it as loss function. The experiments results show that the combination loss functions produce higher accuracy in HCCR. This report briefly reviews cross entropy loss function, a typical similarity ranking function: Euclidean distance, and also propose a new similarity ranking function: Average variance similarity. Experiments are done to compare the performances of a CNN model with three different loss functions. In the end, SoftMax cross entropy with Average variance similarity produce the highest accuracy on handwritten Chinese characters recognition.