 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimality of Thompson Sampling with Noninformative Priors for Pareto Bandits
Feb 03, 2023



In the stochastic multi-armed bandit problem, a randomized probability matching policy called Thompson sampling (TS) has shown excellent performance in various reward models. In addition to the empirical performance, TS has been shown to achieve asymptotic problem-dependent lower bounds in several models. However, its optimality has been mainly addressed under light-tailed or one-parameter models that belong to exponential families. In this paper, we consider the optimality of TS for the Pareto model that has a heavy tail and is parameterized by two unknown parameters. Specifically, we discuss the optimality of TS with probability matching priors that include the Jeffreys prior and the reference priors. We first prove that TS with certain probability matching priors can achieve the optimal regret bound. Then, we show the suboptimality of TS with other priors, including the Jeffreys and the reference priors. Nevertheless, we find that TS with the Jeffreys and reference priors can achieve the asymptotic lower bound if one uses a truncation procedure. These results suggest carefully choosing noninformative priors to avoid suboptimality and show the effectiveness of truncation procedures in TS-based policies.
Best-of-Both-Worlds Algorithms for Partial Monitoring
Jul 29, 2022
This paper considers the partial monitoring problem with $k$-actions and $d$-outcomes and provides the first best-of-both-worlds algorithms, whose regrets are bounded poly-logarithmically in the stochastic regime and near-optimally in the adversarial regime. To be more specific, we show that for non-degenerate locally observable games, the regret in the stochastic regime is bounded by $O(k^3 m^2 \log(T) \log(k_{\Pi} T) / \Delta_{\mathrm{\min}})$ and in the adversarial regime by $O(k^{2/3} m \sqrt{T \log(T) \log k_{\Pi}})$, where $T$ is the number of rounds, $m$ is the maximum number of distinct observations per action, $\Delta_{\min}$ is the minimum optimality gap, and $k_{\Pi}$ is the number of Pareto optimal actions. Moreover, we show that for non-degenerate globally observable games, the regret in the stochastic regime is bounded by $O(\max\{c_{\mathcal{G}}^2 / k,\, c_{\mathcal{G}}\} \log(T) \log(k_{\Pi} T) / \Delta_{\min}^2)$ and in the adversarial regime by $O((\max\{c_{\mathcal{G}}^2 / k,\, c_{\mathcal{G}}\} \log(T) \log(k_{\Pi} T)))^{1/3} T^{2/3})$, where $c_{\mathcal{G}}$ is a game-dependent constant. Our algorithms are based on the follow-the-regularized-leader framework that takes into account the nature of the partial monitoring problem, inspired by algorithms in the field of online learning with feedback graphs.
Adversarially Robust Multi-Armed Bandit Algorithm with Variance-Dependent Regret Bounds
Jun 14, 2022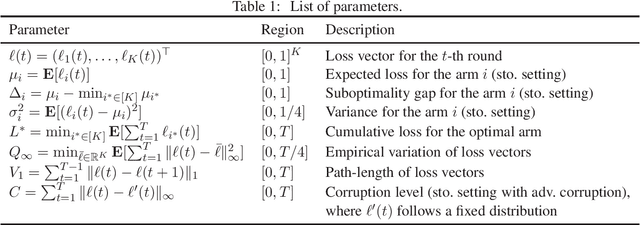



This paper considers the multi-armed bandit (MAB) problem and provides a new best-of-both-worlds (BOBW) algorithm that works nearly optimally in both stochastic and adversarial settings. In stochastic settings, some existing BOBW algorithms achieve tight gap-dependent regret bounds of $O(\sum_{i: \Delta_i>0} \frac{\log T}{\Delta_i})$ for suboptimality gap $\Delta_i$ of arm $i$ and time horizon $T$. As Audibert et al. [2007] have shown, however, that the performance can be improved in stochastic environments with low-variance arms. In fact, they have provided a stochastic MAB algorithm with gap-variance-dependent regret bounds of $O(\sum_{i: \Delta_i>0} (\frac{\sigma_i^2}{\Delta_i} + 1) \log T )$ for loss variance $\sigma_i^2$ of arm $i$. In this paper, we propose the first BOBW algorithm with gap-variance-dependent bounds, showing that the variance information can be used even in the possibly adversarial environment. Further, the leading constant factor in our gap-variance dependent bound is only (almost) twice the value for the lower bound. Additionally, the proposed algorithm enjoys multiple data-dependent regret bounds in adversarial settings and works well in stochastic settings with adversarial corruptions. The proposed algorithm is based on the follow-the-regularized-leader method and employs adaptive learning rates that depend on the empirical prediction error of the loss, which leads to gap-variance-dependent regret bounds reflecting the variance of the arms.
Globally Optimal Algorithms for Fixed-Budget Best Arm Identification
Jun 10, 2022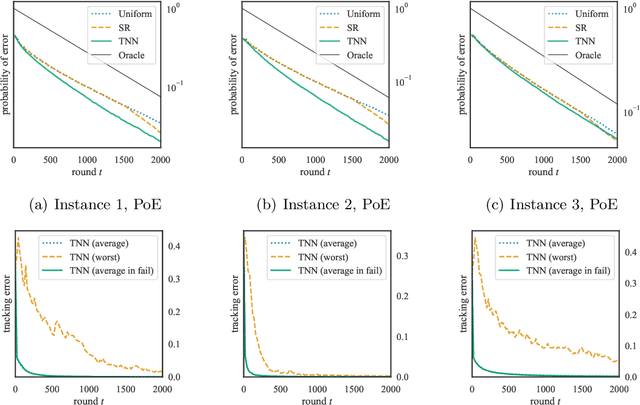

We consider the fixed-budget best arm identification problem where the goal is to find the arm of the largest mean with a fixed number of samples. It is known that the probability of misidentifying the best arm is exponentially small to the number of rounds. However, limited characterizations have been discussed on the rate (exponent) of this value. In this paper, we characterize the optimal rate as a result of global optimization over all possible parameters. We introduce two rates, $R^{\mathrm{go}}$ and $R^{\mathrm{go}}_{\infty}$, corresponding to lower bounds on the misidentification probability, each of which is associated with a proposed algorithm. The rate $R^{\mathrm{go}}$ is associated with $R^{\mathrm{go}}$-tracking, which can be efficiently implemented by a neural network and is shown to outperform existing algorithms. However, this rate requires a nontrivial condition to be achievable. To deal with this issue, we introduce the second rate $R^{\mathrm{go}}_\infty$. We show that this rate is indeed achievable by introducing a conceptual algorithm called delayed optimal tracking (DOT).
The Survival Bandit Problem
Jun 07, 2022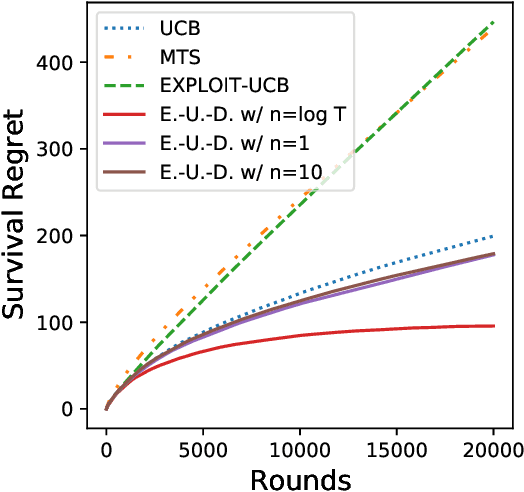
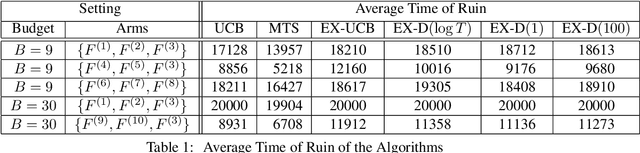
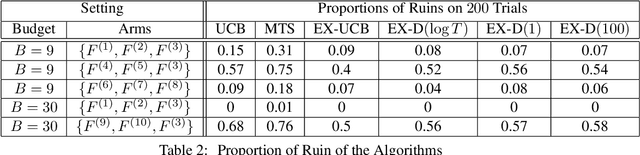
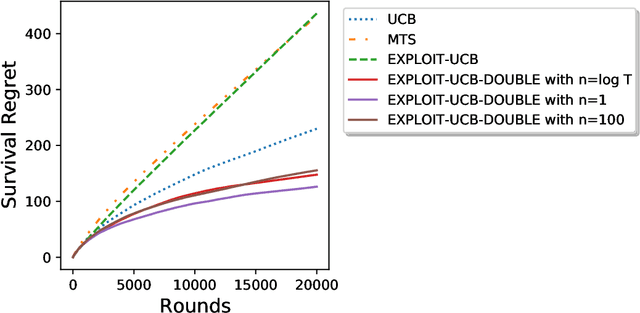
We study the survival bandit problem, a variant of the multi-armed bandit problem introduced in an open problem by Perotto et al. (2019), with a constraint on the cumulative reward; at each time step, the agent receives a (possibly negative) reward and if the cumulative reward becomes lower than a prespecified threshold, the procedure stops, and this phenomenon is called ruin. This is the first paper studying a framework where the ruin might occur but not always. We first discuss that a sublinear regret is unachievable under a naive definition of the regret. Next, we provide tight lower bounds on the probability of ruin (as well as matching policies). Based on this lower bound, we define the survival regret as an objective to minimize and provide a policy achieving a sublinear survival regret (at least in the case of integral rewards) when the time horizon $T$ is known.
Nearly Optimal Best-of-Both-Worlds Algorithms for Online Learning with Feedback Graphs
Jun 02, 2022
This study considers online learning with general directed feedback graphs. For this problem, we present best-of-both-worlds algorithms that achieve nearly tight regret bounds for adversarial environments as well as poly-logarithmic regret bounds for stochastic environments. As Alon et al. [2015] have shown, tight regret bounds depend on the structure of the feedback graph: \textit{strongly observable} graphs yield minimax regret of $\tilde{\Theta}( \alpha^{1/2} T^{1/2} )$, while \textit{weakly observable} graphs induce minimax regret of $\tilde{\Theta}( \delta^{1/3} T^{2/3} )$, where $\alpha$ and $\delta$, respectively, represent the independence number of the graph and the domination number of a certain portion of the graph. Our proposed algorithm for strongly observable graphs has a regret bound of $\tilde{O}( \alpha^{1/2} T^{1/2} ) $ for adversarial environments, as well as of $ {O} ( \frac{\alpha (\ln T)^3 }{\Delta_{\min}} ) $ for stochastic environments, where $\Delta_{\min}$ expresses the minimum suboptimality gap. This result resolves an open question raised by Erez and Koren [2021]. We also provide an algorithm for weakly observable graphs that achieves a regret bound of $\tilde{O}( \delta^{1/3}T^{2/3} )$ for adversarial environments and poly-logarithmic regret for stochastic environments. The proposed algorithms are based on the follow-the-perturbed-leader approach combined with newly designed update rules for learning rates.
Finite-time Analysis of Globally Nonstationary Multi-Armed Bandits
Jul 23, 2021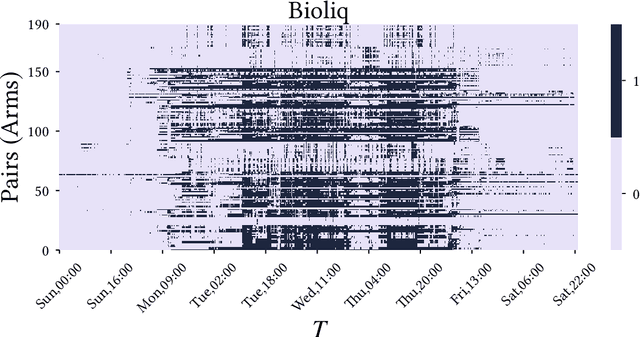

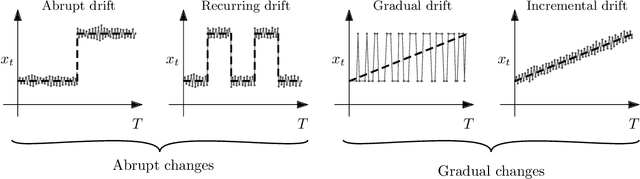

We consider nonstationary multi-armed bandit problems where the model parameters of the arms change over time. We introduce the adaptive resetting bandit (ADR-bandit), which is a class of bandit algorithms that leverages adaptive windowing techniques from the data stream community. We first provide new guarantees on the quality of estimators resulting from adaptive windowing techniques, which are of independent interest in the data mining community. Furthermore, we conduct a finite-time analysis of ADR-bandit in two typical environments: an abrupt environment where changes occur instantaneously and a gradual environment where changes occur progressively. We demonstrate that ADR-bandit has nearly optimal performance when the abrupt or global changes occur in a coordinated manner that we call global changes. We demonstrate that forced exploration is unnecessary when we restrict the interest to the global changes. Unlike the existing nonstationary bandit algorithms, ADR-bandit has optimal performance in stationary environments as well as nonstationary environments with global changes. Our experiments show that the proposed algorithms outperform the existing approaches in synthetic and real-world environments.
Mediated Uncoupled Learning: Learning Functions without Direct Input-output Correspondences
Jul 16, 2021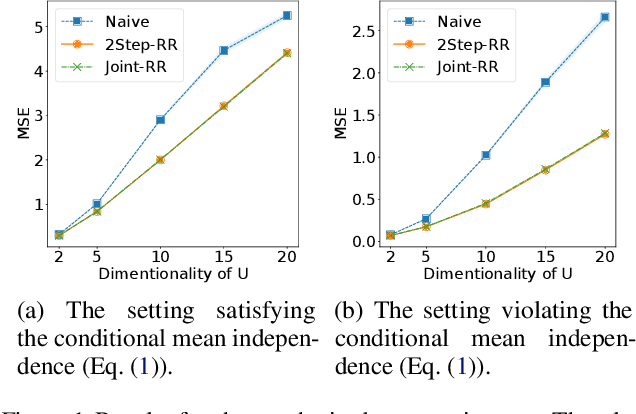
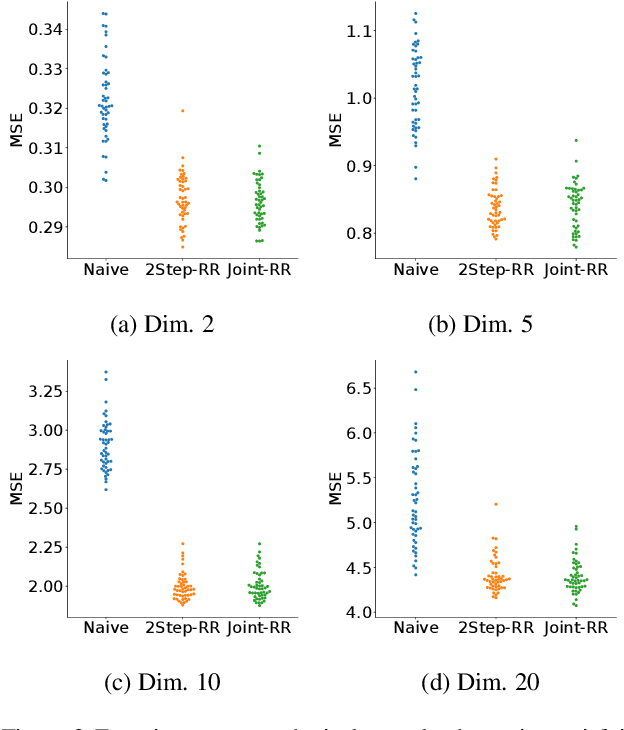
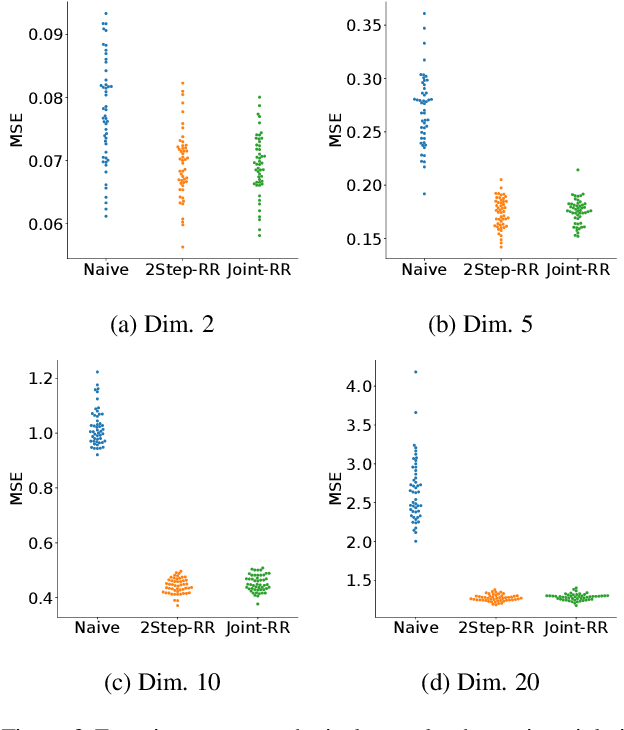
Ordinary supervised learning is useful when we have paired training data of input $X$ and output $Y$. However, such paired data can be difficult to collect in practice. In this paper, we consider the task of predicting $Y$ from $X$ when we have no paired data of them, but we have two separate, independent datasets of $X$ and $Y$ each observed with some mediating variable $U$, that is, we have two datasets $S_X = \{(X_i, U_i)\}$ and $S_Y = \{(U'_j, Y'_j)\}$. A naive approach is to predict $U$ from $X$ using $S_X$ and then $Y$ from $U$ using $S_Y$, but we show that this is not statistically consistent. Moreover, predicting $U$ can be more difficult than predicting $Y$ in practice, e.g., when $U$ has higher dimensionality. To circumvent the difficulty, we propose a new method that avoids predicting $U$ but directly learns $Y = f(X)$ by training $f(X)$ with $S_{X}$ to predict $h(U)$ which is trained with $S_{Y}$ to approximate $Y$. We prove statistical consistency and error bounds of our method and experimentally confirm its practical usefulness.
Combinatorial Pure Exploration with Full-bandit Feedback and Beyond: Solving Combinatorial Optimization under Uncertainty with Limited Observation
Dec 31, 2020
Combinatorial optimization is one of the fundamental research fields that has been extensively studied in theoretical computer science and operations research. When developing an algorithm for combinatorial optimization, it is commonly assumed that parameters such as edge weights are exactly known as inputs. However, this assumption may not be fulfilled since input parameters are often uncertain or initially unknown in many applications such as recommender systems, crowdsourcing, communication networks, and online advertisement. To resolve such uncertainty, the problem of combinatorial pure exploration of multi-armed bandits (CPE) and its variants have recieved increasing attention. Earlier work on CPE has studied the semi-bandit feedback or assumed that the outcome from each individual edge is always accessible at all rounds. However, due to practical constraints such as a budget ceiling or privacy concern, such strong feedback is not always available in recent applications. In this article, we review recently proposed techniques for combinatorial pure exploration problems with limited feedback.
Online Dense Subgraph Discovery via Blurred-Graph Feedback
Jun 24, 2020



Dense subgraph discovery aims to find a dense component in edge-weighted graphs. This is a fundamental graph-mining task with a variety of applications and thus has received much attention recently. Although most existing methods assume that each individual edge weight is easily obtained, such an assumption is not necessarily valid in practice. In this paper, we introduce a novel learning problem for dense subgraph discovery in which a learner queries edge subsets rather than only single edges and observes a noisy sum of edge weights in a queried subset. For this problem, we first propose a polynomial-time algorithm that obtains a nearly-optimal solution with high probability. Moreover, to deal with large-sized graphs, we design a more scalable algorithm with a theoretical guarantee. Computational experiments using real-world graphs demonstrate the effectiveness of our algorithms.