 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRKV: Global Regression for Training-Free KV Cache Compression in Long-Context LLMs
May 29, 2026Large language models (LLMs) with extended context lengths rely on the key-value (KV) cache to support attention over prior tokens. However, maintaining the KV cache incurs substantial memory overhead, motivating KV-cache compression methods that enforce a fixed budget through eviction and merging. Modern eviction methods increasingly adopt span-based retention because preserving contiguous spans is empirically effective and better preserves semantic coherence. Yet, when combined with post-eviction merging, span-based retention concentrates merges onto a small set of span-boundary carrier tokens, producing a highly imbalanced merge pattern that exacerbates over-merging and increases information loss. To address this imbalance, we propose GRKV (Global Regression for KV Cache), a training-free KV-cache merging method that directly minimizes the discrepancy between compressed-cache and full-cache attention outputs. GRKV uses ridge-regression-based merge steps to distribute information from evicted tokens across retained tokens, while regularizing the updates to prevent over-smoothing. Across the LongBench and RULER long-context benchmarks, GRKV is the only merging method that improves overall performance with minimal overhead.
Multimodal Transformers are Hierarchical Modal-wise Heterogeneous Graphs
May 02, 2025Multimodal Sentiment Analysis (MSA) is a rapidly developing field that integrates multimodal information to recognize sentiments, and existing models have made significant progress in this area. The central challenge in MSA is multimodal fusion, which is predominantly addressed by Multimodal Transformers (MulTs). Although act as the paradigm, MulTs suffer from efficiency concerns. In this work, from the perspective of efficiency optimization, we propose and prove that MulTs are hierarchical modal-wise heterogeneous graphs (HMHGs), and we introduce the graph-structured representation pattern of MulTs. Based on this pattern, we propose an Interlaced Mask (IM) mechanism to design the Graph-Structured and Interlaced-Masked Multimodal Transformer (GsiT). It is formally equivalent to MulTs which achieves an efficient weight-sharing mechanism without information disorder through IM, enabling All-Modal-In-One fusion with only 1/3 of the parameters of pure MulTs. A Triton kernel called Decomposition is implemented to ensure avoiding additional computational overhead. Moreover, it achieves significantly higher performance than traditional MulTs. To further validate the effectiveness of GsiT itself and the HMHG concept, we integrate them into multiple state-of-the-art models and demonstrate notable performance improvements and parameter reduction on widely used MSA datasets.
Video Sentiment Analysis with Bimodal Information-augmented Multi-Head Attention
Mar 09, 2021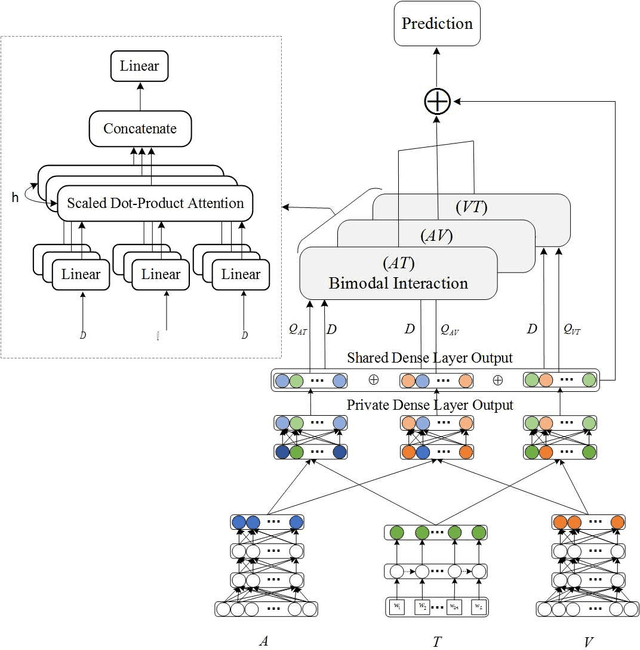
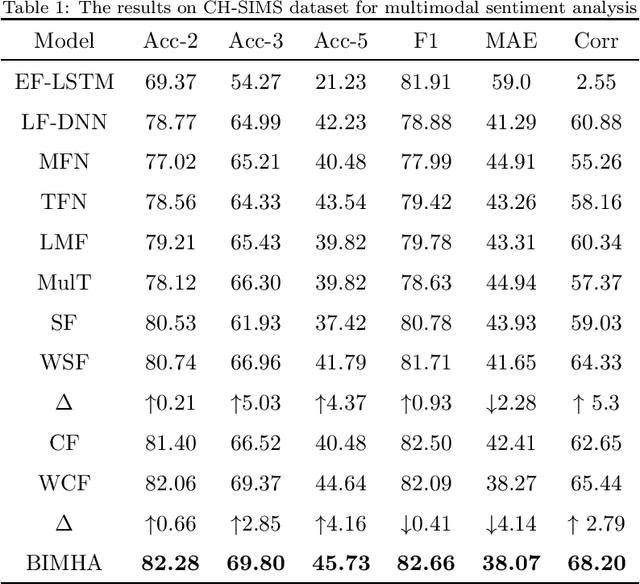
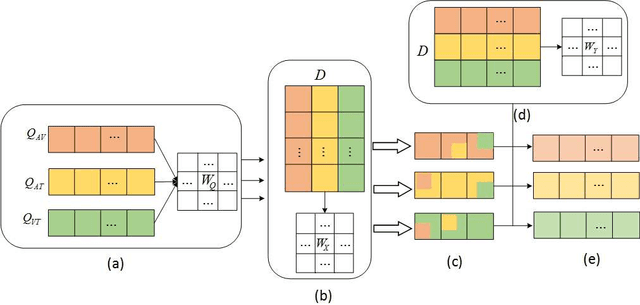
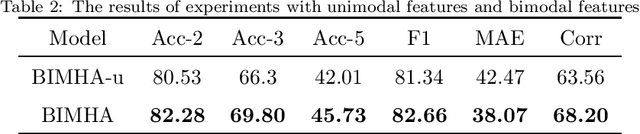
Sentiment analysis is the basis of intelligent human-computer interaction. As one of the frontier research directions of artificial intelligence, it can help computers better identify human intentions and emotional states so that provide more personalized services. However, as human present sentiments by spoken words, gestures, facial expressions and others which involve variable forms of data including text, audio, video, etc., it poses many challenges to this study. Due to the limitations of unimodal sentiment analysis, recent research has focused on the sentiment analysis of videos containing time series data of multiple modalities. When analyzing videos with multimodal data, the key problem is how to fuse these heterogeneous data. In consideration that the contribution of each modality is different, current fusion methods tend to extract the important information of single modality prior to fusion, which ignores the consistency and complementarity of bimodal interaction and has influences on the final decision. To solve this problem, a video sentiment analysis method using multi-head attention with bimodal information augmented is proposed. Based on bimodal interaction, more important bimodal features are assigned larger weights. In this way, different feature representations are adaptively assigned corresponding attention for effective multimodal fusion. Extensive experiments were conducted on both Chinese and English public datasets. The results show that our approach outperforms the existing methods and can give an insight into the contributions of bimodal interaction among three modalities.