 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePULL: PU-Learning-based Accurate Link Prediction
May 20, 2024



Given an edge-incomplete graph, how can we accurately find the missing links? The link prediction in edge-incomplete graphs aims to discover the missing relations between entities when their relationships are represented as a graph. Edge-incomplete graphs are prevalent in real-world due to practical limitations, such as not checking all users when adding friends in a social network. Addressing the problem is crucial for various tasks, including recommending friends in social networks and finding references in citation networks. However, previous approaches rely heavily on the given edge-incomplete (observed) graph, making it challenging to consider the missing (unobserved) links during training. In this paper, we propose PULL (PU-Learning-based Link predictor), an accurate link prediction method based on the positive-unlabeled (PU) learning. PULL treats the observed edges in the training graph as positive examples, and the unconnected node pairs as unlabeled ones. PULL effectively prevents the link predictor from overfitting to the observed graph by proposing latent variables for every edge, and leveraging the expected graph structure with respect to the variables. Extensive experiments on five real-world datasets show that PULL consistently outperforms the baselines for predicting links in edge-incomplete graphs.
Improving Speech Emotion Recognition Through Focus and Calibration Attention Mechanisms
Aug 21, 2022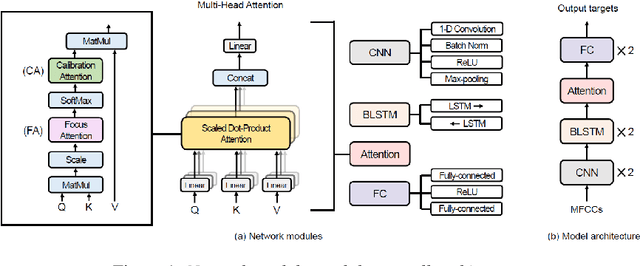
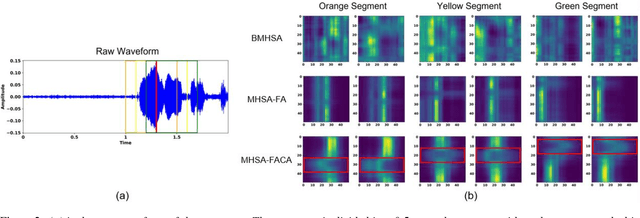
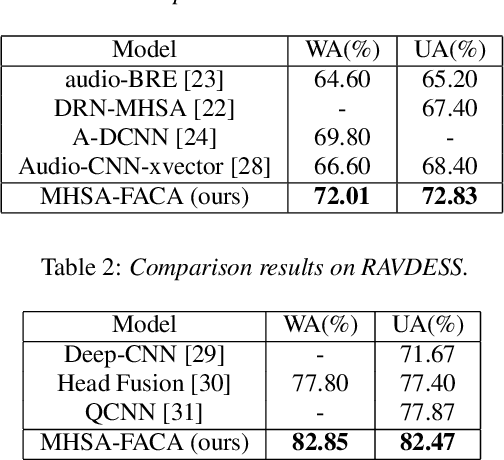
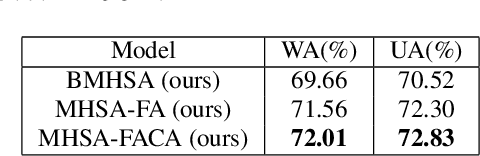
Attention has become one of the most commonly used mechanisms in deep learning approaches. The attention mechanism can help the system focus more on the feature space's critical regions. For example, high amplitude regions can play an important role for Speech Emotion Recognition (SER). In this paper, we identify misalignments between the attention and the signal amplitude in the existing multi-head self-attention. To improve the attention area, we propose to use a Focus-Attention (FA) mechanism and a novel Calibration-Attention (CA) mechanism in combination with the multi-head self-attention. Through the FA mechanism, the network can detect the largest amplitude part in the segment. By employing the CA mechanism, the network can modulate the information flow by assigning different weights to each attention head and improve the utilization of surrounding contexts. To evaluate the proposed method, experiments are performed with the IEMOCAP and RAVDESS datasets. Experimental results show that the proposed framework significantly outperforms the state-of-the-art approaches on both datasets.
Representation Learning with Graph Neural Networks for Speech Emotion Recognition
Aug 21, 2022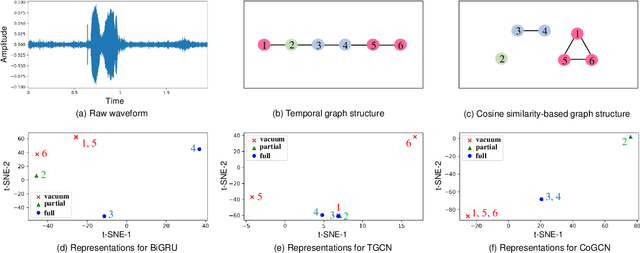
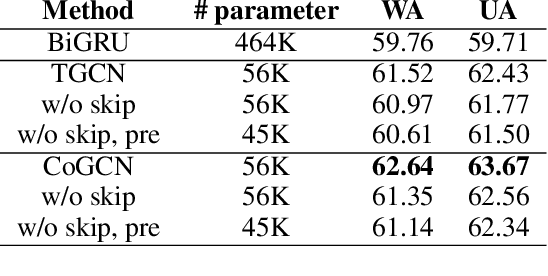
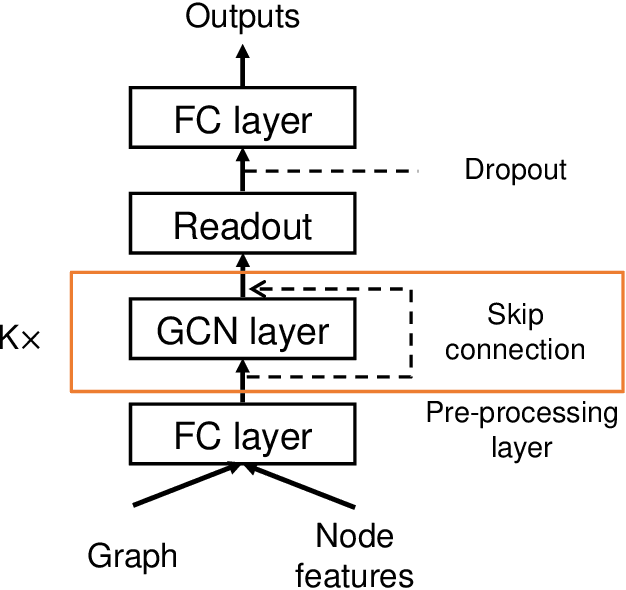
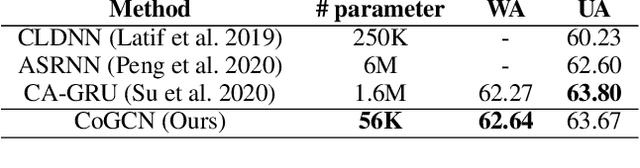
Learning expressive representation is crucial in deep learning. In speech emotion recognition (SER), vacuum regions or noises in the speech interfere with expressive representation learning. However, traditional RNN-based models are susceptible to such noise. Recently, Graph Neural Network (GNN) has demonstrated its effectiveness for representation learning, and we adopt this framework for SER. In particular, we propose a cosine similarity-based graph as an ideal graph structure for representation learning in SER. We present a Cosine similarity-based Graph Convolutional Network (CoGCN) that is robust to perturbation and noise. Experimental results show that our method outperforms state-of-the-art methods or provides competitive results with a significant model size reduction with only 1/30 parameters.