 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Learning of Multi-column Convolutional Neural Network for Crowd Counting
Sep 17, 2019
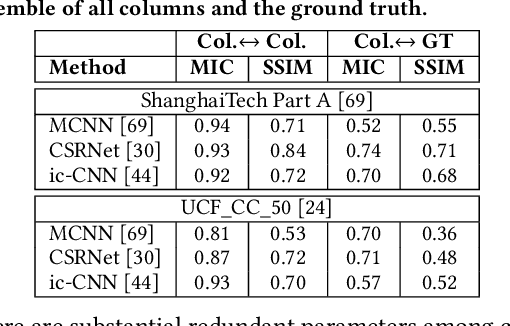
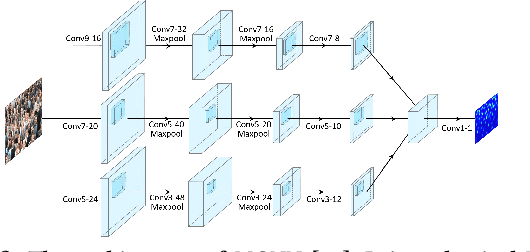
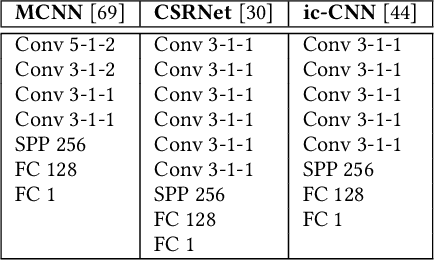
Tremendous variation in the scale of people/head size is a critical problem for crowd counting. To improve the scale invariance of feature representation, recent works extensively employ Convolutional Neural Networks with multi-column structures to handle different scales and resolutions. However, due to the substantial redundant parameters in columns, existing multi-column networks invariably exhibit almost the same scale features in different columns, which severely affects counting accuracy and leads to overfitting. In this paper, we attack this problem by proposing a novel Multi-column Mutual Learning (McML) strategy. It has two main innovations: 1) A statistical network is incorporated into the multi-column framework to estimate the mutual information between columns, which can approximately indicate the scale correlation between features from different columns. By minimizing the mutual information, each column is guided to learn features with different image scales. 2) We devise a mutual learning scheme that can alternately optimize each column while keeping the other columns fixed on each mini-batch training data. With such asynchronous parameter update process, each column is inclined to learn different feature representation from others, which can efficiently reduce the parameter redundancy and improve generalization ability. More remarkably, McML can be applied to all existing multi-column networks and is end-to-end trainable. Extensive experiments on four challenging benchmarks show that McML can significantly improve the original multi-column networks and outperform the other state-of-the-art approaches.
Learning Spatial Awareness to Improve Crowd Counting
Sep 16, 2019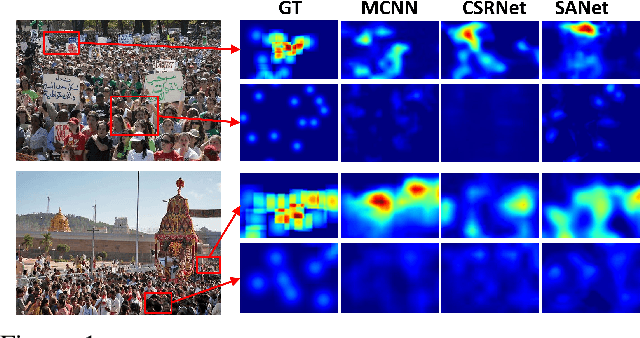
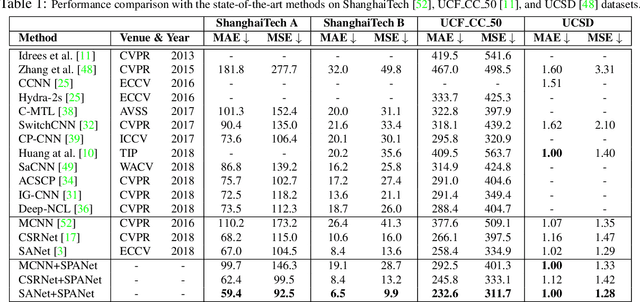
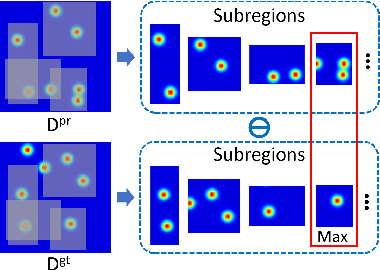
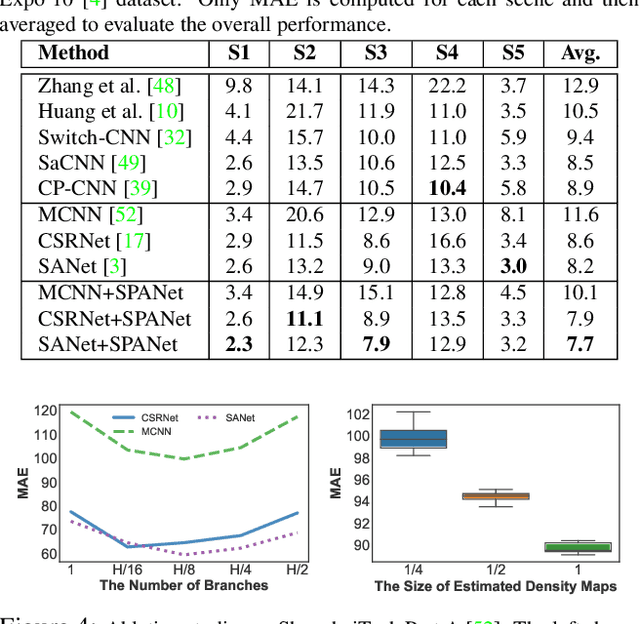
The aim of crowd counting is to estimate the number of people in images by leveraging the annotation of center positions for pedestrians' heads. Promising progresses have been made with the prevalence of deep Convolutional Neural Networks. Existing methods widely employ the Euclidean distance (i.e., $L_2$ loss) to optimize the model, which, however, has two main drawbacks: (1) the loss has difficulty in learning the spatial awareness (i.e., the position of head) since it struggles to retain the high-frequency variation in the density map, and (2) the loss is highly sensitive to various noises in crowd counting, such as the zero-mean noise, head size changes, and occlusions. Although the Maximum Excess over SubArrays (MESA) loss has been previously proposed to address the above issues by finding the rectangular subregion whose predicted density map has the maximum difference from the ground truth, it cannot be solved by gradient descent, thus can hardly be integrated into the deep learning framework. In this paper, we present a novel architecture called SPatial Awareness Network (SPANet) to incorporate spatial context for crowd counting. The Maximum Excess over Pixels (MEP) loss is proposed to achieve this by finding the pixel-level subregion with high discrepancy to the ground truth. To this end, we devise a weakly supervised learning scheme to generate such region with a multi-branch architecture. The proposed framework can be integrated into existing deep crowd counting methods and is end-to-end trainable. Extensive experiments on four challenging benchmarks show that our method can significantly improve the performance of baselines. More remarkably, our approach outperforms the state-of-the-art methods on all benchmark datasets.