 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Aware Crowd Count Network with Annotation Error Correction
Dec 28, 2023Traditional crowd counting networks suffer from information loss when feature maps are downsized through pooling layers, leading to inaccuracies in counting crowds at a distance. Existing methods often assume correct annotations during training, disregarding the impact of noisy annotations, especially in crowded scenes. Furthermore, the use of a fixed Gaussian kernel fails to account for the varying pixel distribution with respect to the camera distance. To overcome these challenges, we propose a Scale-Aware Crowd Counting Network (SACC-Net) that introduces a ``scale-aware'' architecture with error-correcting capabilities of noisy annotations. For the first time, we {\bf simultaneously} model labeling errors (mean) and scale variations (variance) by spatially-varying Gaussian distributions to produce fine-grained heat maps for crowd counting. Furthermore, the proposed adaptive Gaussian kernel variance enables the model to learn dynamically with a low-rank approximation, leading to improved convergence efficiency with comparable accuracy. The performance of SACC-Net is extensively evaluated on four public datasets: UCF-QNRF, UCF CC 50, NWPU, and ShanghaiTech A-B. Experimental results demonstrate that SACC-Net outperforms all state-of-the-art methods, validating its effectiveness in achieving superior crowd counting accuracy.
MixNet: Toward Accurate Detection of Challenging Scene Text in the Wild
Aug 28, 2023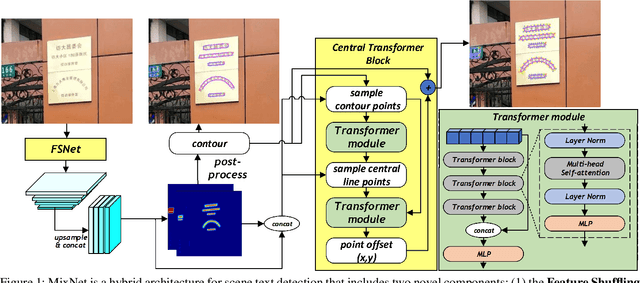
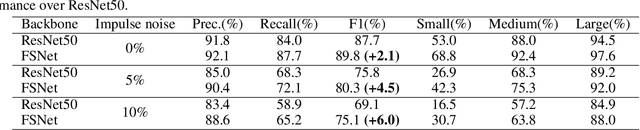
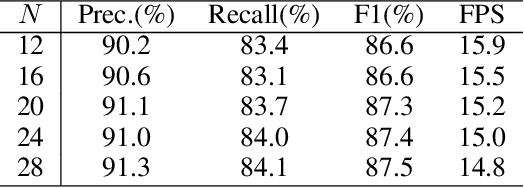

Detecting small scene text instances in the wild is particularly challenging, where the influence of irregular positions and nonideal lighting often leads to detection errors. We present MixNet, a hybrid architecture that combines the strengths of CNNs and Transformers, capable of accurately detecting small text from challenging natural scenes, regardless of the orientations, styles, and lighting conditions. MixNet incorporates two key modules: (1) the Feature Shuffle Network (FSNet) to serve as the backbone and (2) the Central Transformer Block (CTBlock) to exploit the 1D manifold constraint of the scene text. We first introduce a novel feature shuffling strategy in FSNet to facilitate the exchange of features across multiple scales, generating high-resolution features superior to popular ResNet and HRNet. The FSNet backbone has achieved significant improvements over many existing text detection methods, including PAN, DB, and FAST. Then we design a complementary CTBlock to leverage center line based features similar to the medial axis of text regions and show that it can outperform contour-based approaches in challenging cases when small scene texts appear closely. Extensive experimental results show that MixNet, which mixes FSNet with CTBlock, achieves state-of-the-art results on multiple scene text detection datasets.
FishEye8K: A Benchmark and Dataset for Fisheye Camera Object Detection
Jun 06, 2023With the advance of AI, road object detection has been a prominent topic in computer vision, mostly using perspective cameras. Fisheye lens provides omnidirectional wide coverage for using fewer cameras to monitor road intersections, however with view distortions. To our knowledge, there is no existing open dataset prepared for traffic surveillance on fisheye cameras. This paper introduces an open FishEye8K benchmark dataset for road object detection tasks, which comprises 157K bounding boxes across five classes (Pedestrian, Bike, Car, Bus, and Truck). In addition, we present benchmark results of State-of-The-Art (SoTA) models, including variations of YOLOv5, YOLOR, YOLO7, and YOLOv8. The dataset comprises 8,000 images recorded in 22 videos using 18 fisheye cameras for traffic monitoring in Hsinchu, Taiwan, at resolutions of 1080$\times$1080 and 1280$\times$1280. The data annotation and validation process were arduous and time-consuming, due to the ultra-wide panoramic and hemispherical fisheye camera images with large distortion and numerous road participants, particularly people riding scooters. To avoid bias, frames from a particular camera were assigned to either the training or test sets, maintaining a ratio of about 70:30 for both the number of images and bounding boxes in each class. Experimental results show that YOLOv8 and YOLOR outperform on input sizes 640$\times$640 and 1280$\times$1280, respectively. The dataset will be available on GitHub with PASCAL VOC, MS COCO, and YOLO annotation formats. The FishEye8K benchmark will provide significant contributions to the fisheye video analytics and smart city applications.
RATs-NAS: Redirection of Adjacent Trails on GCN for Neural Architecture Search
May 09, 2023Various hand-designed CNN architectures have been developed, such as VGG, ResNet, DenseNet, etc., and achieve State-of-the-Art (SoTA) levels on different tasks. Neural Architecture Search (NAS) now focuses on automatically finding the best CNN architecture to handle the above tasks. However, the verification of a searched architecture is very time-consuming and makes predictor-based methods become an essential and important branch of NAS. Two commonly used techniques to build predictors are graph-convolution networks (GCN) and multilayer perceptron (MLP). In this paper, we consider the difference between GCN and MLP on adjacent operation trails and then propose the Redirected Adjacent Trails NAS (RATs-NAS) to quickly search for the desired neural network architecture. The RATs-NAS consists of two components: the Redirected Adjacent Trails GCN (RATs-GCN) and the Predictor-based Search Space Sampling (P3S) module. RATs-GCN can change trails and their strengths to search for a better neural network architecture. P3S can rapidly focus on tighter intervals of FLOPs in the search space. Based on our observations on cell-based NAS, we believe that architectures with similar FLOPs will perform similarly. Finally, the RATs-NAS consisting of RATs-GCN and P3S beats WeakNAS, Arch-Graph, and others by a significant margin on three sub-datasets of NASBench-201.
SARAS-Net: Scale and Relation Aware Siamese Network for Change Detection
Dec 02, 2022



Change detection (CD) aims to find the difference between two images at different times and outputs a change map to represent whether the region has changed or not. To achieve a better result in generating the change map, many State-of-The-Art (SoTA) methods design a deep learning model that has a powerful discriminative ability. However, these methods still get lower performance because they ignore spatial information and scaling changes between objects, giving rise to blurry or wrong boundaries. In addition to these, they also neglect the interactive information of two different images. To alleviate these problems, we propose our network, the Scale and Relation-Aware Siamese Network (SARAS-Net) to deal with this issue. In this paper, three modules are proposed that include relation-aware, scale-aware, and cross-transformer to tackle the problem of scene change detection more effectively. To verify our model, we tested three public datasets, including LEVIR-CD, WHU-CD, and DSFIN, and obtained SoTA accuracy. Our code is available at https://github.com/f64051041/SARAS-Net.
SMILEtrack: SiMIlarity LEarning for Multiple Object Tracking
Nov 17, 2022



Multiple Object Tracking (MOT) is widely investigated in computer vision with many applications. Tracking-By-Detection (TBD) is a popular multiple-object tracking paradigm. TBD consists of the first step of object detection and the subsequent of data association, tracklet generation, and update. We propose a Similarity Learning Module (SLM) motivated from the Siamese network to extract important object appearance features and a procedure to combine object motion and appearance features effectively. This design strengthens the modeling of object motion and appearance features for data association. We design a Similarity Matching Cascade (SMC) for the data association of our SMILEtrack tracker. SMILEtrack achieves 81.06 MOTA and 80.5 IDF1 on the MOTChallenge and the MOT17 test set, respectively.
Scale-Aware Crowd Counting Using a Joint Likelihood Density Map and Synthetic Fusion Pyramid Network
Nov 13, 2022We develop a Synthetic Fusion Pyramid Network (SPF-Net) with a scale-aware loss function design for accurate crowd counting. Existing crowd-counting methods assume that the training annotation points were accurate and thus ignore the fact that noisy annotations can lead to large model-learning bias and counting error, especially for counting highly dense crowds that appear far away. To the best of our knowledge, this work is the first to properly handle such noise at multiple scales in end-to-end loss design and thus push the crowd counting state-of-the-art. We model the noise of crowd annotation points as a Gaussian and derive the crowd probability density map from the input image. We then approximate the joint distribution of crowd density maps with the full covariance of multiple scales and derive a low-rank approximation for tractability and efficient implementation. The derived scale-aware loss function is used to train the SPF-Net. We show that it outperforms various loss functions on four public datasets: UCF-QNRF, UCF CC 50, NWPU and ShanghaiTech A-B datasets. The proposed SPF-Net can accurately predict the locations of people in the crowd, despite training on noisy training annotations.
NAS-based Recursive Stage Partial Network for Light-Weight Semantic Segmentation
Oct 03, 2022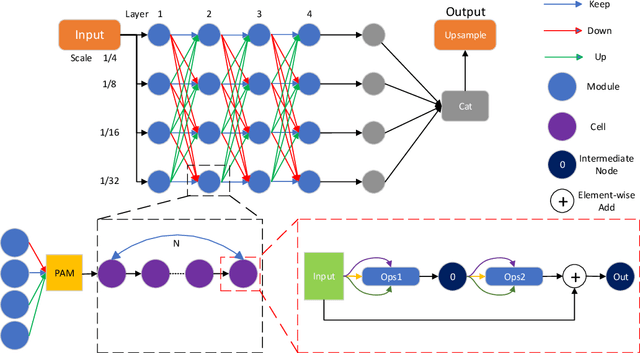

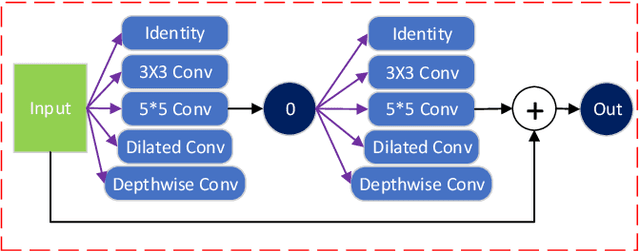
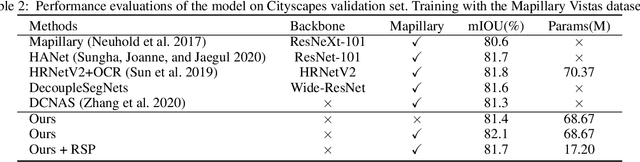
Current NAS-based semantic segmentation methods focus on accuracy improvements rather than light-weight design. In this paper, we proposed a two-stage framework to design our NAS-based RSPNet model for light-weight semantic segmentation. The first architecture search determines the inner cell structure, and the second architecture search considers exponentially growing paths to finalize the outer structure of the network. It was shown in the literature that the fusion of high- and low-resolution feature maps produces stronger representations. To find the expected macro structure without manual design, we adopt a new path-attention mechanism to efficiently search for suitable paths to fuse useful information for better segmentation. Our search for repeatable micro-structures from cells leads to a superior network architecture in semantic segmentation. In addition, we propose an RSP (recursive Stage Partial) architecture to search a light-weight design for NAS-based semantic segmentation. The proposed architecture is very efficient, simple, and effective that both the macro- and micro- structure searches can be completed in five days of computation on two V100 GPUs. The light-weight NAS architecture with only 1/4 parameter size of SoTA architectures can achieve SoTA performance on semantic segmentation on the Cityscapes dataset without using any backbones.
Siamese-NAS: Using Trained Samples Efficiently to Find Lightweight Neural Architecture by Prior Knowledge
Oct 02, 2022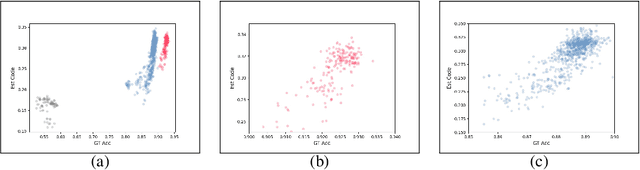
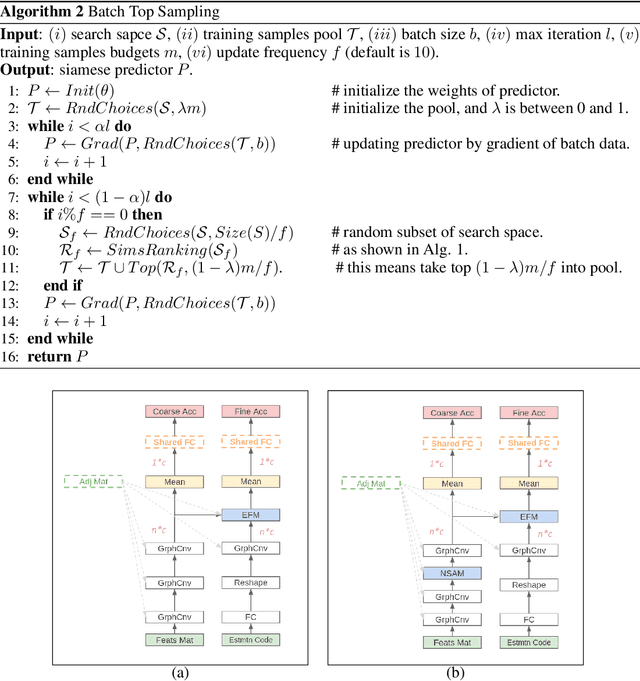
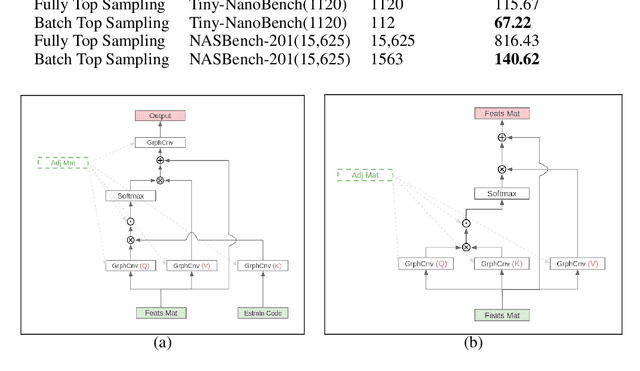
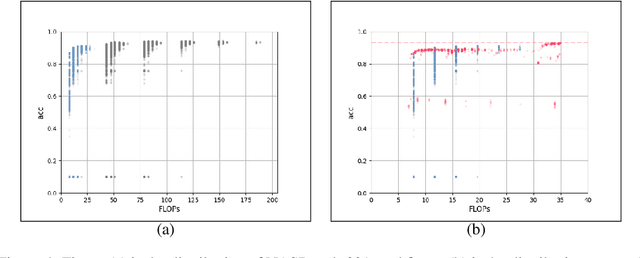
In the past decade, many architectures of convolution neural networks were designed by handcraft, such as Vgg16, ResNet, DenseNet, etc. They all achieve state-of-the-art level on different tasks in their time. However, it still relies on human intuition and experience, and it also takes so much time consumption for trial and error. Neural Architecture Search (NAS) focused on this issue. In recent works, the Neural Predictor has significantly improved with few training architectures as training samples. However, the sampling efficiency is already considerable. In this paper, our proposed Siamese-Predictor is inspired by past works of predictor-based NAS. It is constructed with the proposed Estimation Code, which is the prior knowledge about the training procedure. The proposed Siamese-Predictor gets significant benefits from this idea. This idea causes it to surpass the current SOTA predictor on NASBench-201. In order to explore the impact of the Estimation Code, we analyze the relationship between it and accuracy. We also propose the search space Tiny-NanoBench for lightweight CNN architecture. This well-designed search space is easier to find better architecture with few FLOPs than NASBench-201. In summary, the proposed Siamese-Predictor is a predictor-based NAS. It achieves the SOTA level, especially with limited computation budgets. It applied to the proposed Tiny-NanoBench can just use a few trained samples to find extremely lightweight CNN architecture.
Class-Specific Channel Attention for Few-Shot Learning
Sep 03, 2022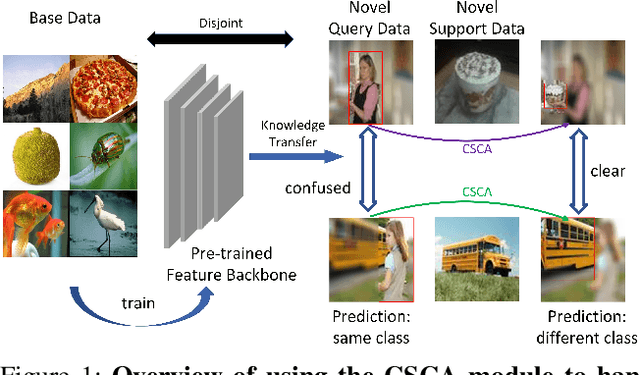
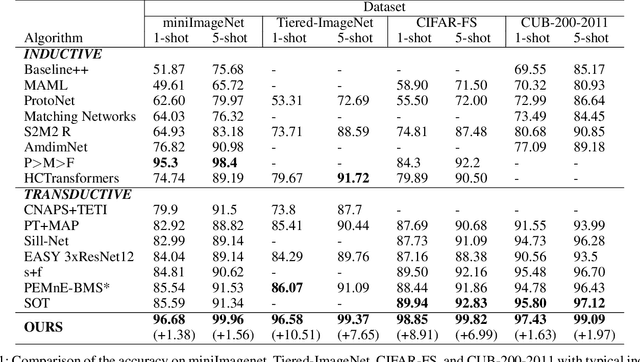
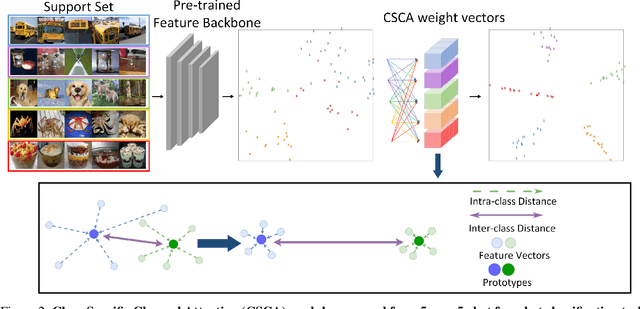
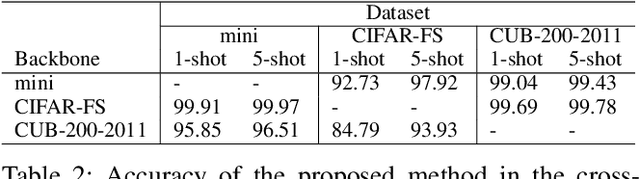
Few-Shot Learning (FSL) has attracted growing attention in computer vision due to its capability in model training without the need for excessive data. FSL is challenging because the training and testing categories (the base vs. novel sets) can be largely diversified. Conventional transfer-based solutions that aim to transfer knowledge learned from large labeled training sets to target testing sets are limited, as critical adverse impacts of the shift in task distribution are not adequately addressed. In this paper, we extend the solution of transfer-based methods by incorporating the concept of metric-learning and channel attention. To better exploit the feature representations extracted by the feature backbone, we propose Class-Specific Channel Attention (CSCA) module, which learns to highlight the discriminative channels in each class by assigning each class one CSCA weight vector. Unlike general attention modules designed to learn global-class features, the CSCA module aims to learn local and class-specific features with very effective computation. We evaluated the performance of the CSCA module on standard benchmarks including miniImagenet, Tiered-ImageNet, CIFAR-FS, and CUB-200-2011. Experiments are performed in inductive and in/cross-domain settings. We achieve new state-of-the-art results.