 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing item recommendations and LLMs in marketing email titles
Aug 27, 2025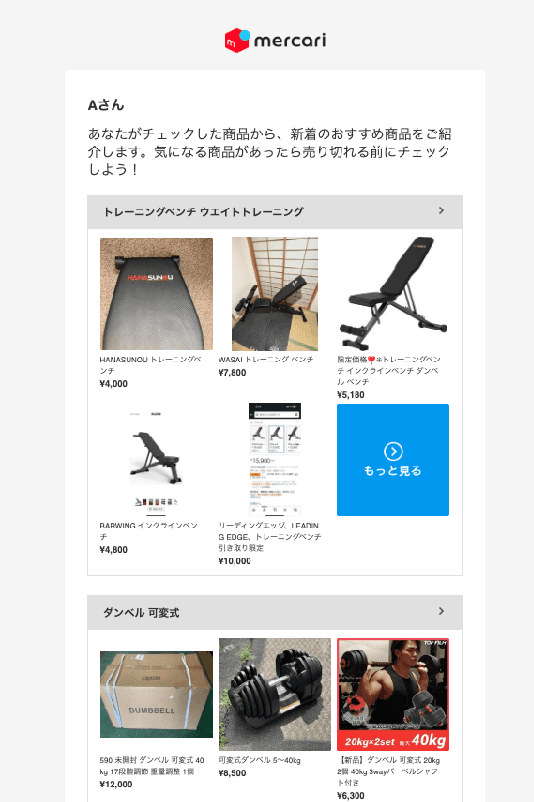


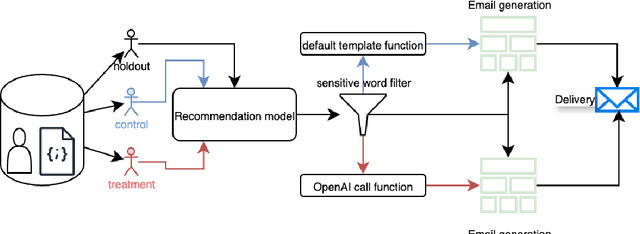
E-commerce marketplaces make use of a number of marketing channels like emails, push notifications, etc. to reach their users and stimulate purchases. Personalized emails especially are a popular touch point for marketers to inform users of latest items in stock, especially for those who stopped visiting the marketplace. Such emails contain personalized recommendations tailored to each user's interests, enticing users to buy relevant items. A common limitation of these emails is that the primary entry point, the title of the email, tends to follow fixed templates, failing to inspire enough interest in the contents. In this work, we explore the potential of large language models (LLMs) for generating thematic titles that reflect the personalized content of the emails. We perform offline simulations and conduct online experiments on the order of millions of users, finding our techniques useful in improving the engagement between customers and our emails. We highlight key findings and learnings as we productionize the safe and automated generation of email titles for millions of users.
CERM: Context-aware Literature-based Discovery via Sentiment Analysis
Jan 27, 2024Driven by the abundance of biomedical publications, we introduce a sentiment analysis task to understand food-health relationship. Prior attempts to incorporate health into recipe recommendation and analysis systems have primarily focused on ingredient nutritional components or utilized basic computational models trained on curated labeled data. Enhanced models that capture the inherent relationship between food ingredients and biomedical concepts can be more beneficial for food-related research, given the wealth of information in biomedical texts. Considering the costly data labeling process, these models should effectively utilize both labeled and unlabeled data. This paper introduces Entity Relationship Sentiment Analysis (ERSA), a new task that captures the sentiment of a text based on an entity pair. ERSA extends the widely studied Aspect Based Sentiment Analysis (ABSA) task. Specifically, our study concentrates on the ERSA task applied to biomedical texts, focusing on (entity-entity) pairs of biomedical and food concepts. ERSA poses a significant challenge compared to traditional sentiment analysis tasks, as sentence sentiment may not align with entity relationship sentiment. Additionally, we propose CERM, a semi-supervised architecture that combines different word embeddings to enhance the encoding of the ERSA task. Experimental results showcase the model's efficiency across diverse learning scenarios.