 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Method for Keyword Extraction for Patent Claims
Jul 08, 2024



The search for prior art is crucial in patent application processing, it consists in retrieving other documents relevant to the invention of the application. Most methods feed a search engine with keywords that are extracted by frequency-analysis methods. We suggest and demonstrate a new method that relies on the way information is provided in patent claims.
Legal Search in Case Law and Statute Law
Aug 23, 2021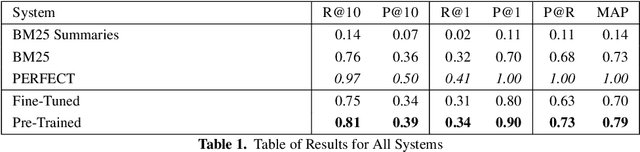

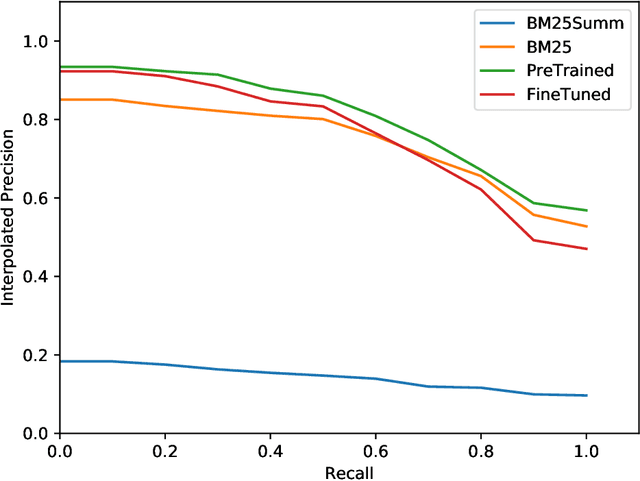
In this work we describe a method to identify document pairwise relevance in the context of a typical legal document collection: limited resources, long queries and long documents. We review the usage of generalized language models, including supervised and unsupervised learning. We observe how our method, while using text summaries, overperforms existing baselines based on full text, and motivate potential improvement directions for future work.
VerbCL: A Dataset of Verbatim Quotes for Highlight Extraction in Case Law
Aug 23, 2021
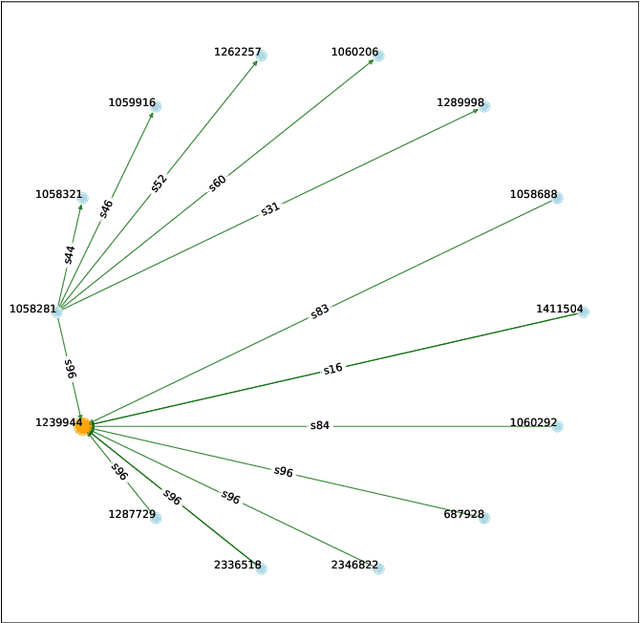

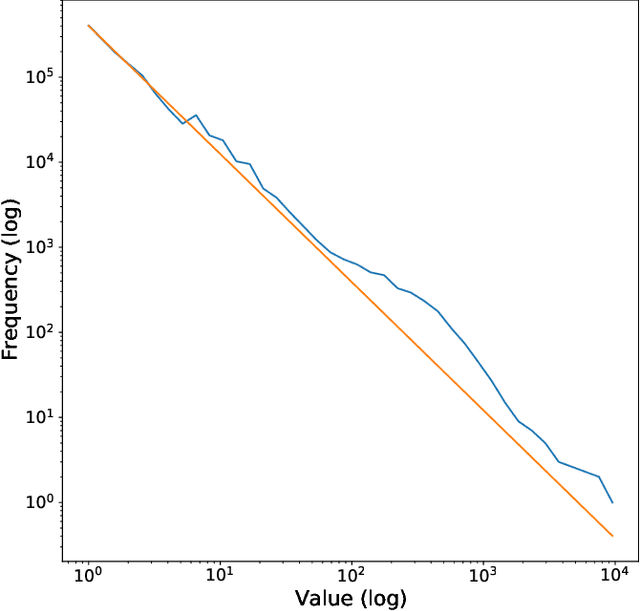
Citing legal opinions is a key part of legal argumentation, an expert task that requires retrieval, extraction and summarization of information from court decisions. The identification of legally salient parts in an opinion for the purpose of citation may be seen as a domain-specific formulation of a highlight extraction or passage retrieval task. As similar tasks in other domains such as web search show significant attention and improvement, progress in the legal domain is hindered by the lack of resources for training and evaluation. This paper presents a new dataset that consists of the citation graph of court opinions, which cite previously published court opinions in support of their arguments. In particular, we focus on the verbatim quotes, i.e., where the text of the original opinion is directly reused. With this approach, we explain the relative importance of different text spans of a court opinion by showcasing their usage in citations, and measuring their contribution to the relations between opinions in the citation graph. We release VerbCL, a large-scale dataset derived from CourtListener and introduce the task of highlight extraction as a single-document summarization task based on the citation graph establishing the first baseline results for this task on the VerbCL dataset.
Code Word Detection in Fraud Investigations using a Deep-Learning Approach
Mar 17, 2021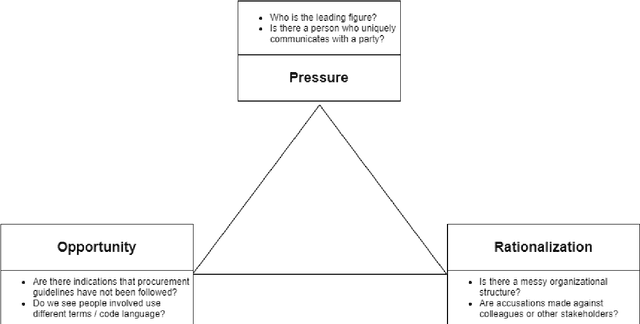
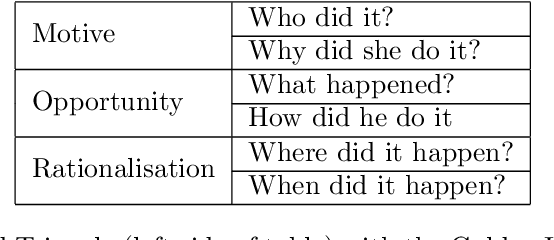
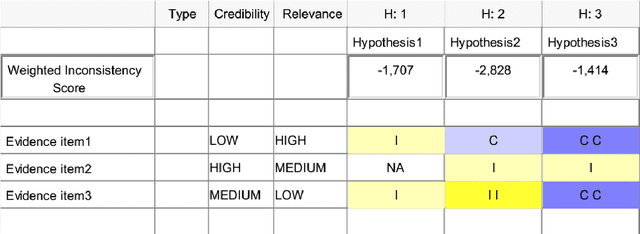
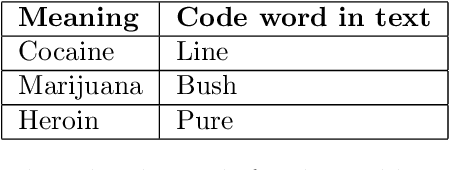
In modern litigation, fraud investigators often face an overwhelming number of documents that must be reviewed throughout a matter. In the majority of legal cases, fraud investigators do not know beforehand, exactly what they are looking for, nor where to find it. In addition, fraudsters may use deception to hide their behaviour and intentions by using code words. Effectively, this means fraud investigators are looking for a needle in the haystack without knowing what the needle looks like. As part of a larger research program, we use a framework to expedite the investigation process applying text-mining and machine learning techniques. We structure this framework using three well-known methods in fraud investigations: (i) the fraud triangle (ii) the golden ("W") investigation questions, and (iii) the analysis of competing hypotheses. With this framework, it is possible to automatically organize investigative data, so it is easier for investigators to find answers to typical investigative questions. In this research, we focus on one of the components of this framework: the identification of the usage of code words by fraudsters. Here for, a novel (annotated) synthetic data set is created containing such code words, hidden in normal email communication. Subsequently, a range of machine learning techniques are employed to detect such code words. We show that the state-of-the-art BERT model significantly outperforms other methods on this task. With this result, we demonstrate that deep neural language models can reliably (F1 score of 0.9) be applied in fraud investigations for the detection of code words.
A Benchmark for Lease Contract Review
Oct 20, 2020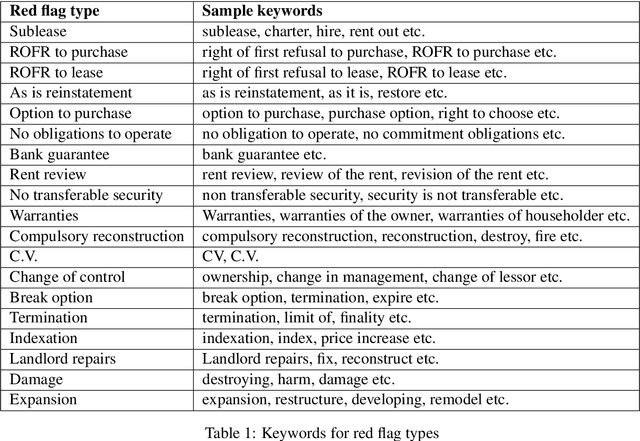
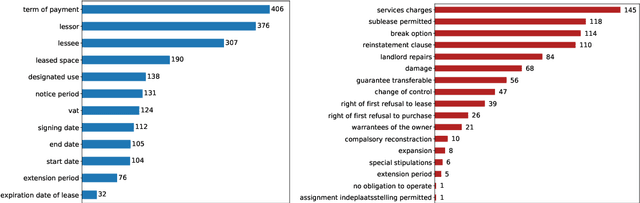

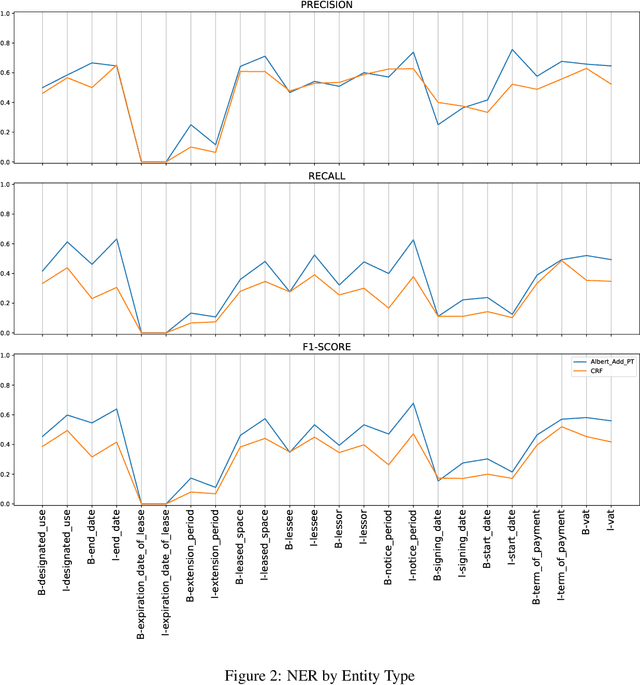
Extracting entities and other useful information from legal contracts is an important task whose automation can help legal professionals perform contract reviews more efficiently and reduce relevant risks. In this paper, we tackle the problem of detecting two different types of elements that play an important role in a contract review, namely entities and red flags. The latter are terms or sentences that indicate that there is some danger or other potentially problematic situation for one or more of the signing parties. We focus on supporting the review of lease agreements, a contract type that has received little attention in the legal information extraction literature, and we define the types of entities and red flags needed for that task. We release a new benchmark dataset of 179 lease agreement documents that we have manually annotated with the entities and red flags they contain, and which can be used to train and test relevant extraction algorithms. Finally, we release a new language model, called ALeaseBERT, pre-trained on this dataset and fine-tuned for the detection of the aforementioned elements, providing a baseline for further research
Query Generation for Patent Retrieval with Keyword Extraction based on Syntactic Features
Jun 18, 2019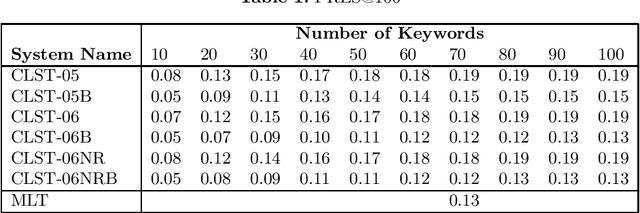
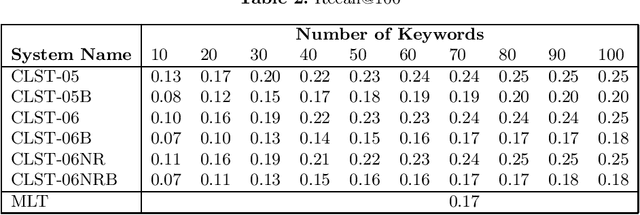
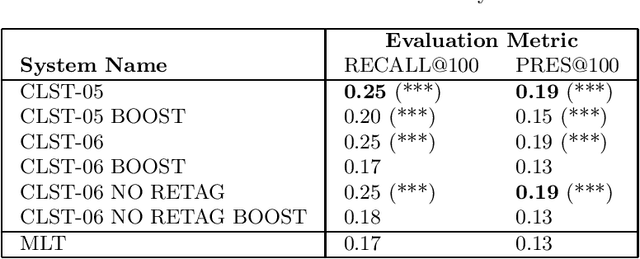
This paper describes a new method to extract relevant keywords from patent claims, as part of the task of retrieving other patents with similar claims (search for prior art). The method combines a qualitative analysis of the writing style of the claims with NLP methods to parse text, in order to represent a legal text as a specialization arborescence of terms. In this setting, the set of extracted keywords are yielding better search results than keywords extracted with traditional methods such as tf-idf. The performance is measured on the search results of a query consisting of the extracted keywords.