 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Forecasting of Scientific Breakthroughs from Concept Network Dynamics
Jun 02, 2026We introduce an explainable machine-learning approach that forecasts the structural precursors of scientific breakthroughs -- the emergence and intensification of links between research concepts -- by modelling how OpenAlex concept networks evolve over time. Using 59 semantic and topological features, a two-stage LightGBM model jointly predicts the formation and the future weight of concept pairs, adding a regression stage that quantifies expected intensity to prior link-existence forecasts. Relative to the state of the art, the approach improves accuracy and explainability at once: comparative validation across four technology and biomedical domains yields ROC-AUC in [0.954, 0.967] at all horizons without re-tuning, exceeding the roughly 0.90 of prior models, while every forecast rests on structural, auditable features rather than opaque embeddings. Classification performance is high (AUC about 0.95) and regression remains stable (RMSLE 0.45 to 0.6 over one to five years). Feature attribution shows that structural factors -- particularly Adamic-Adar similarity and degree-based Hadamard measures -- consistently drive accuracy, suggesting that breakthrough-relevant recombinations emerge in tightly connected sub-networks. Two expert-anchored cases, quantum annealing and AI-enabled quantum architectures, show the model surfacing technological convergence consistent with expert expectations. We then outline a three-layer decision architecture -- detection, expert translation, institutional integration -- that turns these forecasts into evidence-based research strategy and policy, anchored in open data and explainable features.
Forecasting Conceptual Diffusion in Science: The Case of Quantum Computing
Jun 02, 2026Understanding and anticipating scientific change requires models that distinguish between endogenous consolidation and exogenous diffusion of scientific concepts. Using the quantum computing subtree of concepts in OpenAlex, we construct a temporally resolved concept co-occurrence network and track each concept pair through its upstream citation lineage and downstream diffusion. We train LightGBM models on distributional and diversity-aware features to predict four outcomes: endogenous reinforcement, exogenous diffusion, their ratio, and diffusion entropy. After controlling for overall publication growth of the scientific body, endogenous reinforcement proves largely unpredictable in the primary quantum-computing benchmark. In contrast, exogenous diffusion and entropy are strongly predictable ($R^2$ up to $0.78à) and are driven by upstream heterogeneity, citation breadth, and distributional dispersion, as shown by SHAP analyses; replications on robotics, advanced materials, and neuro implants confirm that exogenous diffusion remains the top-ranked target across fields ($R^2_test \sim 0.60-0.87$), while endogenous predictability rises markedly in neuro implants (R^2_test = 0.83), indicating that the quantum-computing asymmetry does not generalise uniformly. Case studies reveal that sharp entropy increases coincide with the opening of new conceptual frontiers, while entropy collapses signal technological convergence or paradigm displacement. These results demonstrate that conceptual diffusion is governed by stable structural regularities embedded in semantic and citation environments. By identifying early diversity-based signals of cross-domain uptake, the approach provides a scalable foundation for anticipatory scientometrics, technology foresight, and innovation-oriented policy analysis in rapidly evolving research fields.
Measuring Technological Convergence in Encryption Technologies with Proximity Indices: A Text Mining and Bibliometric Analysis using OpenAlex
Mar 03, 2024



Identifying technological convergence among emerging technologies in cybersecurity is crucial for advancing science and fostering innovation. Unlike previous studies focusing on the binary relationship between a paper and the concept it attributes to technology, our approach utilizes attribution scores to enhance the relationships between research papers, combining keywords, citation rates, and collaboration status with specific technological concepts. The proposed method integrates text mining and bibliometric analyses to formulate and predict technological proximity indices for encryption technologies using the "OpenAlex" catalog. Our case study findings highlight a significant convergence between blockchain and public-key cryptography, evidenced by the increasing proximity indices. These results offer valuable strategic insights for those contemplating investments in these domains.
Classification and Explanation of Distributed Denial-of-Service (DDoS) Attack Detection using Machine Learning and Shapley Additive Explanation (SHAP) Methods
Jun 27, 2023



DDoS attacks involve overwhelming a target system with a large number of requests or traffic from multiple sources, disrupting the normal traffic of a targeted server, service, or network. Distinguishing between legitimate traffic and malicious traffic is a challenging task. It is possible to classify legitimate traffic and malicious traffic and analysis the network traffic by using machine learning and deep learning techniques. However, an inter-model explanation implemented to classify a traffic flow whether is benign or malicious is an important investigation of the inner working theory of the model to increase the trustworthiness of the model. Explainable Artificial Intelligence (XAI) can explain the decision-making of the machine learning models that can be classified and identify DDoS traffic. In this context, we proposed a framework that can not only classify legitimate traffic and malicious traffic of DDoS attacks but also use SHAP to explain the decision-making of the classifier model. To address this concern, we first adopt feature selection techniques to select the top 20 important features based on feature importance techniques (e.g., XGB-based SHAP feature importance). Following that, the Multi-layer Perceptron Network (MLP) part of our proposed model uses the optimized features of the DDoS attack dataset as inputs to classify legitimate and malicious traffic. We perform extensive experiments with all features and selected features. The evaluation results show that the model performance with selected features achieves above 99\% accuracy. Finally, to provide interpretability, XAI can be adopted to explain the model performance between the prediction results and features based on global and local explanations by SHAP, which can better explain the results achieved by our proposed framework.
Generative Adversarial Networks for Malware Detection: a Survey
Feb 24, 2023


Since their proposal in the 2014 paper by Ian Goodfellow, there has been an explosion of research into the area of Generative Adversarial Networks. While they have been utilised in many fields, the realm of malware research is a problem space in which GANs have taken root. From balancing datasets to creating unseen examples in rare classes, GAN models offer extensive opportunities for application. This paper surveys the current research and literature for the use of Generative Adversarial Networks in the malware problem space. This is done with the hope that the reader may be able to gain an overall understanding as to what the Generative Adversarial model provides for this field, and for what areas within malware research it is best utilised. It covers the current related surveys, the different categories of GAN, and gives the outcomes of recent research into optimising GANs for different topics, as well as future directions for exploration.
Improving Multilayer-Perceptron(MLP)-based Network Anomaly Detection with Birch Clustering on CICIDS-2017 Dataset
Aug 20, 2022
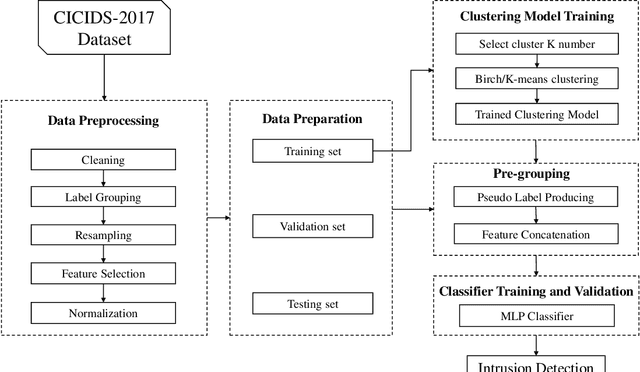
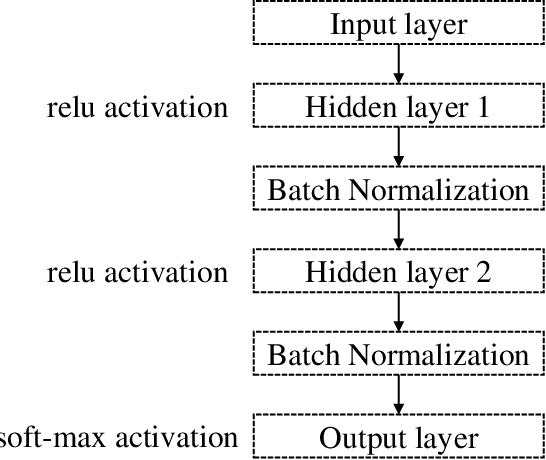
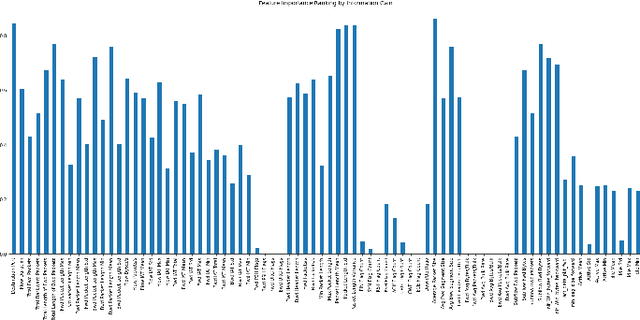
Machine learning algorithms have been widely used in intrusion detection systems, including Multi-layer Perceptron (MLP). In this study, we proposed a two-stage model that combines the Birch clustering algorithm and MLP classifier to improve the performance of network anomaly multi-classification. In our proposed method, we first apply Birch or Kmeans as an unsupervised clustering algorithm to the CICIDS-2017 dataset to pre-group the data. The generated pseudo-label is then added as an additional feature to the training of the MLP-based classifier. The experimental results show that using Birch and K-Means clustering for data pre-grouping can improve intrusion detection system performance. Our method can achieve 99.73% accuracy in multi-classification using Birch clustering, which is better than similar researches using a stand-alone MLP model.
LSTM-Autoencoder based Anomaly Detection for Indoor Air Quality Time Series Data
Apr 14, 2022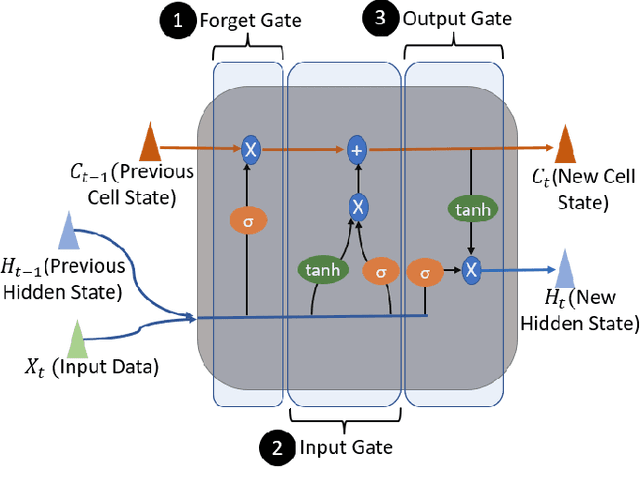
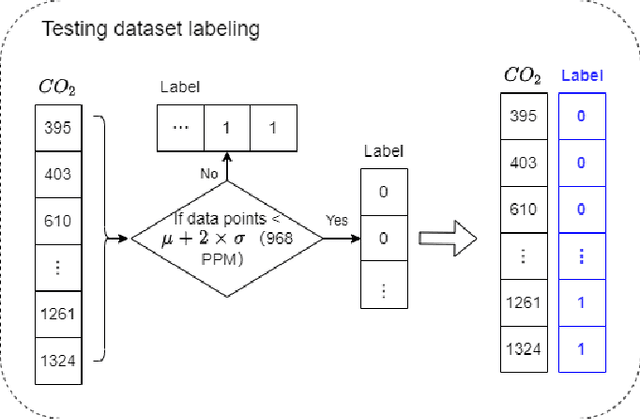
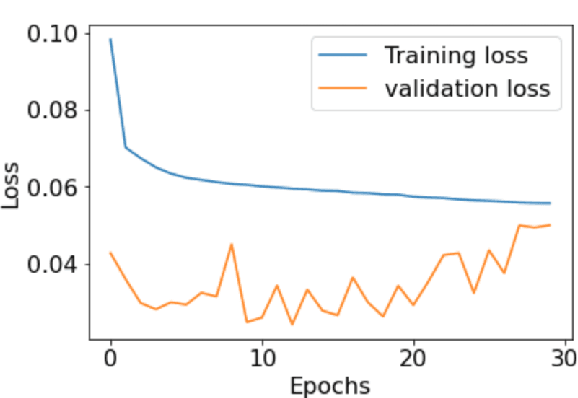
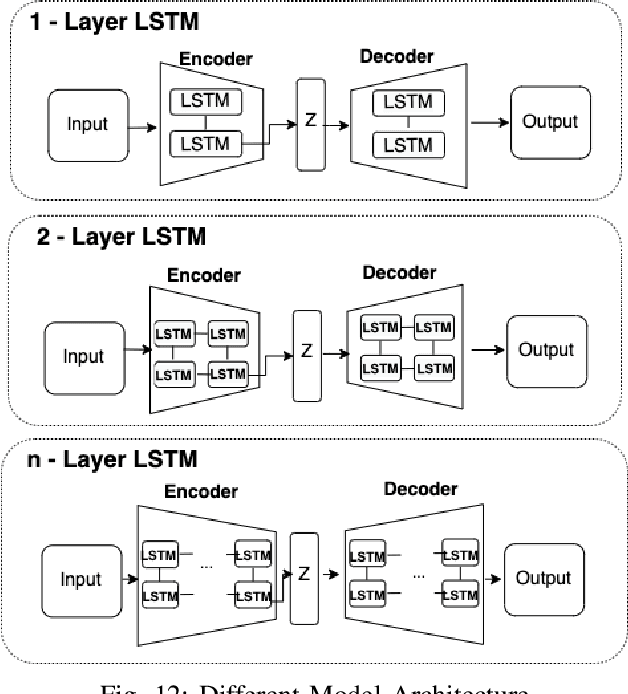
Anomaly detection for indoor air quality (IAQ) data has become an important area of research as the quality of air is closely related to human health and well-being. However, traditional statistics and shallow machine learning-based approaches in anomaly detection in the IAQ area could not detect anomalies involving the observation of correlations across several data points (i.e., often referred to as long-term dependences). We propose a hybrid deep learning model that combines LSTM with Autoencoder for anomaly detection tasks in IAQ to address this issue. In our approach, the LSTM network is comprised of multiple LSTM cells that work with each other to learn the long-term dependences of the data in a time-series sequence. Autoencoder identifies the optimal threshold based on the reconstruction loss rates evaluated on every data across all time-series sequences. Our experimental results, based on the Dunedin CO2 time-series dataset obtained through a real-world deployment of the schools in New Zealand, demonstrate a very high and robust accuracy rate (99.50%) that outperforms other similar models.
IGRF-RFE: A Hybrid Feature Selection Method for MLP-based Network Intrusion Detection on UNSW-NB15 Dataset
Mar 30, 2022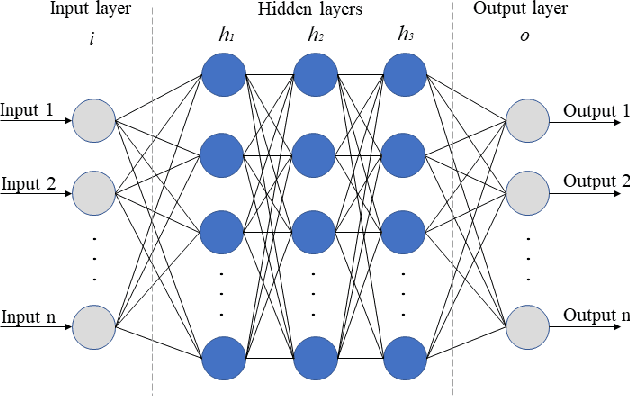
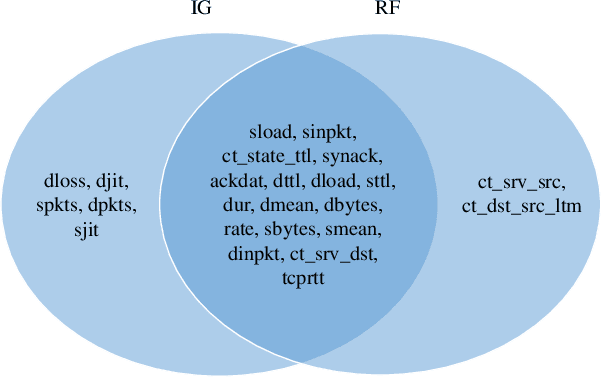
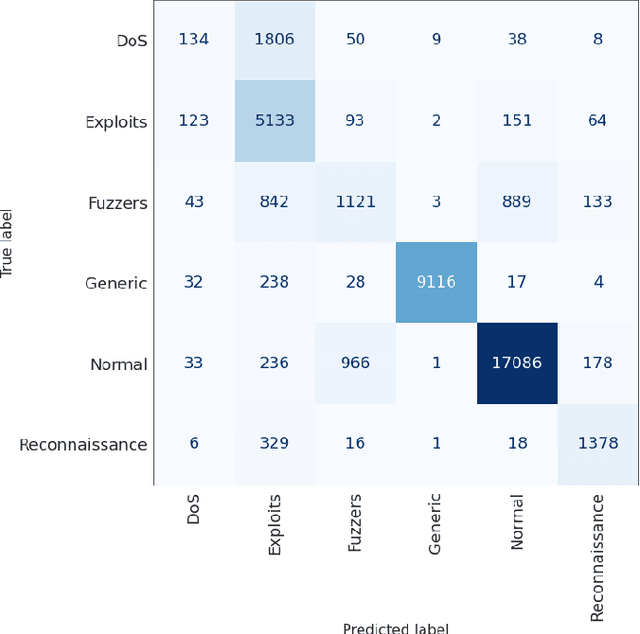
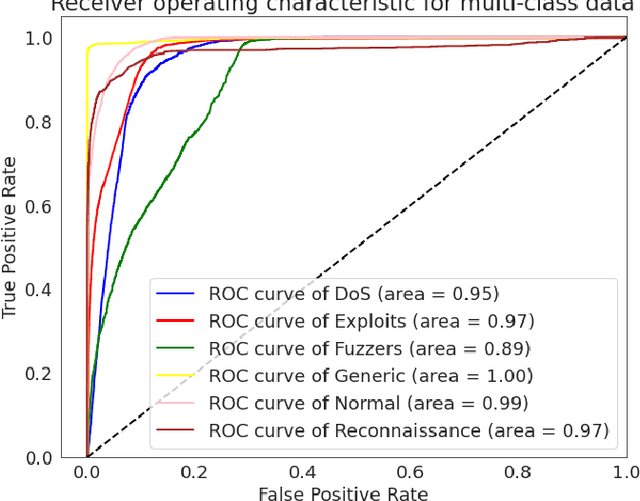
The effectiveness of machine learning models is significantly affected by the size of the dataset and the quality of features as redundant and irrelevant features can radically degrade the performance. This paper proposes IGRF-RFE: a hybrid feature selection method tasked for multi-class network anomalies using a Multilayer perceptron (MLP) network. IGRF-RFE can be considered as a feature reduction technique based on both the filter feature selection method and the wrapper feature selection method. In our proposed method, we use the filter feature selection method, which is the combination of Information Gain and Random Forest Importance, to reduce the feature subset search space. Then, we apply recursive feature elimination(RFE) as a wrapper feature selection method to further eliminate redundant features recursively on the reduced feature subsets. Our experimental results obtained based on the UNSW-NB15 dataset confirm that our proposed method can improve the accuracy of anomaly detection while reducing the feature dimension. The results show that the feature dimension is reduced from 42 to 23 while the multi-classification accuracy of MLP is improved from 82.25% to 84.24%.
Training a Bidirectional GAN-based One-Class Classifier for Network Intrusion Detection
Feb 02, 2022

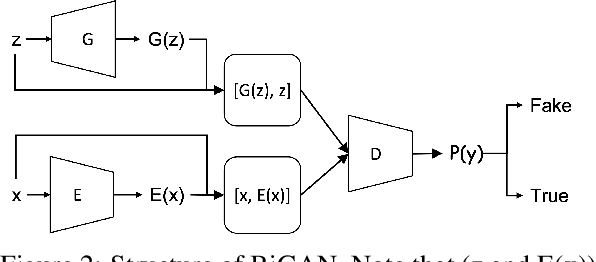
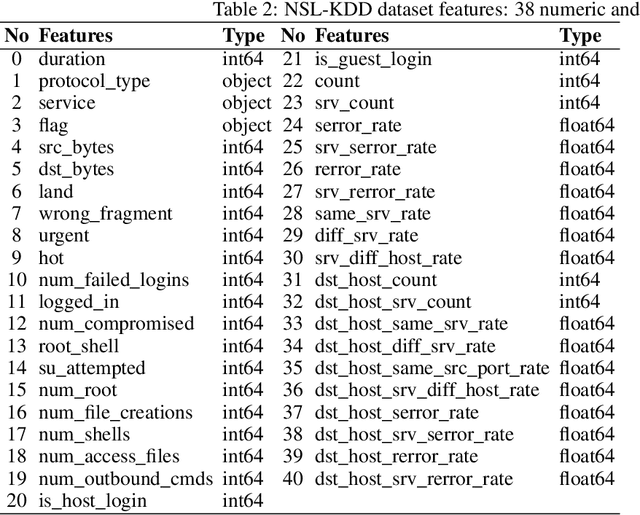
The network intrusion detection task is challenging because of the imbalanced and unlabeled nature of the dataset it operates on. Existing generative adversarial networks (GANs), are primarily used for creating synthetic samples from reals. They also have been proved successful in anomaly detection tasks. In our proposed method, we construct the trained encoder-discriminator as a one-class classifier based on Bidirectional GAN (Bi-GAN) for detecting anomalous traffic from normal traffic other than calculating expensive and complex anomaly scores or thresholds. Our experimental result illustrates that our proposed method is highly effective to be used in network intrusion detection tasks and outperforms other similar generative methods on the NSL-KDD dataset.
A Game-Theoretic Approach for AI-based Botnet Attack Defence
Dec 04, 2021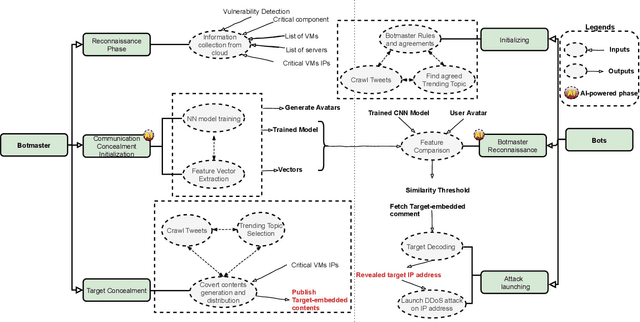
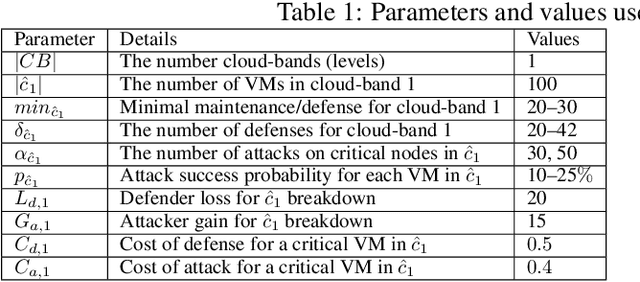
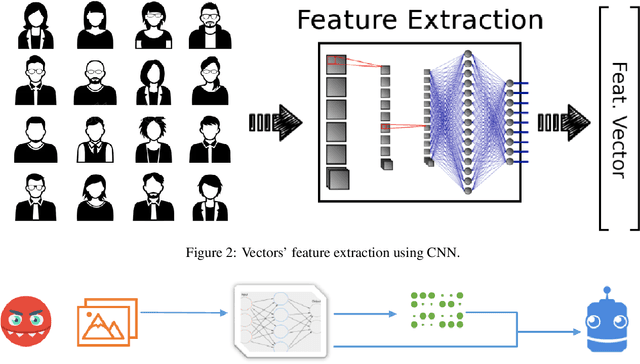
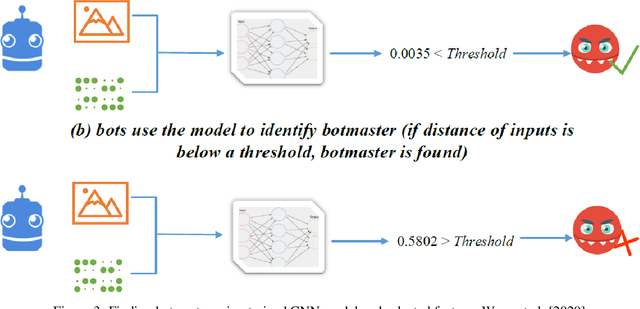
The new generation of botnets leverages Artificial Intelligent (AI) techniques to conceal the identity of botmasters and the attack intention to avoid detection. Unfortunately, there has not been an existing assessment tool capable of evaluating the effectiveness of existing defense strategies against this kind of AI-based botnet attack. In this paper, we propose a sequential game theory model that is capable to analyse the details of the potential strategies botnet attackers and defenders could use to reach Nash Equilibrium (NE). The utility function is computed under the assumption when the attacker launches the maximum number of DDoS attacks with the minimum attack cost while the defender utilises the maximum number of defense strategies with the minimum defense cost. We conduct a numerical analysis based on a various number of defense strategies involved on different (simulated) cloud-band sizes in relation to different attack success rate values. Our experimental results confirm that the success of defense highly depends on the number of defense strategies used according to careful evaluation of attack rates.