 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeVer at CheckThat! 2026: Cluster-Aware Hard-Negative Mining for Multilingual Scientific-Source Retrieval
May 22, 2026Identifying the scientific source behind a social media claim requires matching short, informal, and often multilingual claims against large collections of scientific publications, where semantically related papers may act as challenging distractors or false negatives during training. We present our submission to CheckThat! 2026 Task 1 on multilingual scientific-source retrieval, focusing on how hard-negative mining should be adapted to multi-stage retrieval pipelines for scientific-source retrieval. We propose cluster-aware hard-negative mining strategies that exploit the semantic structure of retrieved candidate pools in order to construct more informative training negatives for dense retrieval and reranking. Our experiments show that different hard-negative structures induce different retrieval behaviors. Localized cluster negatives tend to favor precision-oriented retrieval, whereas broader non-gold semantic negatives provide stronger candidate coverage and more consistent reranking performance across languages. We further study multiple LLM-based evidence-selection formulations, including direct classification, pairwise comparison, and listwise reranking prompts, and find that constrained classification prompts provide the most reliable final document selection. The final system combines a dense retriever, a multilingual cross-encoder reranker, and a selective LLM-based disagreement resolver, ranking 6th among 37 submissions in the shared task evaluation. Overall, our results suggest that hard-negative mining should be treated as a stage-aware design problem rather than as a single retrieval optimization strategy.
TopClustRAG at SIGIR 2025 LiveRAG Challenge
Jun 18, 2025



We present TopClustRAG, a retrieval-augmented generation (RAG) system developed for the LiveRAG Challenge, which evaluates end-to-end question answering over large-scale web corpora. Our system employs a hybrid retrieval strategy combining sparse and dense indices, followed by K-Means clustering to group semantically similar passages. Representative passages from each cluster are used to construct cluster-specific prompts for a large language model (LLM), generating intermediate answers that are filtered, reranked, and finally synthesized into a single, comprehensive response. This multi-stage pipeline enhances answer diversity, relevance, and faithfulness to retrieved evidence. Evaluated on the FineWeb Sample-10BT dataset, TopClustRAG ranked 2nd in faithfulness and 7th in correctness on the official leaderboard, demonstrating the effectiveness of clustering-based context filtering and prompt aggregation in large-scale RAG systems.
SemEval-2025 Task 9: The Food Hazard Detection Challenge
Mar 25, 2025



In this challenge, we explored text-based food hazard prediction with long tail distributed classes. The task was divided into two subtasks: (1) predicting whether a web text implies one of ten food-hazard categories and identifying the associated food category, and (2) providing a more fine-grained classification by assigning a specific label to both the hazard and the product. Our findings highlight that large language model-generated synthetic data can be highly effective for oversampling long-tail distributions. Furthermore, we find that fine-tuned encoder-only, encoder-decoder, and decoder-only systems achieve comparable maximum performance across both subtasks. During this challenge, we gradually released (under CC BY-NC-SA 4.0) a novel set of 6,644 manually labeled food-incident reports.
Towards Systematic Monolingual NLP Surveys: GenA of Greek NLP
Jul 13, 2024Natural Language Processing (NLP) research has traditionally been predominantly focused on English, driven by the availability of resources, the size of the research community, and market demands. Recently, there has been a noticeable shift towards multilingualism in NLP, recognizing the need for inclusivity and effectiveness across diverse languages and cultures. Monolingual surveys have the potential to complement the broader trend towards multilingualism in NLP by providing foundational insights and resources necessary for effectively addressing the linguistic diversity of global communication. However, monolingual NLP surveys are extremely rare in literature. This study fills the gap by introducing a method for creating systematic and comprehensive monolingual NLP surveys. Characterized by a structured search protocol, it can be used to select publications and organize them through a taxonomy of NLP tasks. We include a classification of Language Resources (LRs), according to their availability, and datasets, according to their annotation, to highlight publicly-available and machine-actionable LRs. By applying our method, we conducted a systematic literature review of Greek NLP from 2012 to 2022, providing a comprehensive overview of the current state and challenges of Greek NLP research. We discuss the progress of Greek NLP and outline encountered Greek LRs, classified by availability and usability. As we show, our proposed method helps avoid common pitfalls, such as data leakage and contamination, and to assess language support per NLP task. We consider this systematic literature review of Greek NLP an application of our method that showcases the benefits of a monolingual NLP survey. Similar applications could be regard the myriads of languages whose progress in NLP lags behind that of well-supported languages.
Improved Abusive Comment Moderation with User Embeddings
Aug 11, 2017
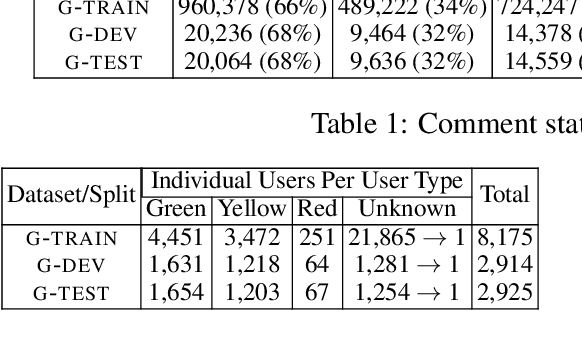
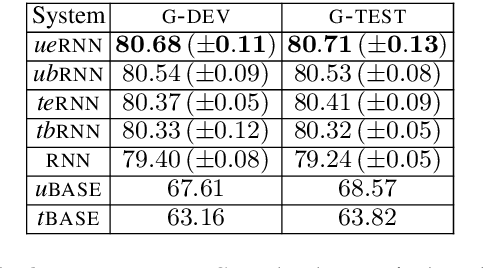
Experimenting with a dataset of approximately 1.6M user comments from a Greek news sports portal, we explore how a state of the art RNN-based moderation method can be improved by adding user embeddings, user type embeddings, user biases, or user type biases. We observe improvements in all cases, with user embeddings leading to the biggest performance gains.