 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4DGS360: 360° Gaussian Reconstruction of Dynamic Objects from a Single Video
Mar 23, 2026We introduce 4DGS360, a diffusion-free framework for 360$^{\circ}$ dynamic object reconstruction from casual monocular video. Existing methods often fail to reconstruct consistent 360$^{\circ}$ geometry, as their heavy reliance on 2D-native priors causes initial points to overfit to visible surface in each training view. 4DGS360 addresses this challenge through a advanced 3D-native initialization that mitigates the geometric ambiguity of occluded regions. Our proposed 3D tracker, AnchorTAP3D, produces reinforced 3D point trajectories by leveraging confident 2D track points as anchors, suppressing drift and providing reliable initialization that preserves geometry in occluded regions. This initialization, combined with optimization, yields coherent 360$^{\circ}$ 4D reconstructions. We further present iPhone360, a new benchmark where test cameras are placed up to 135$^{\circ}$ apart from training views, enabling 360$^{\circ}$ evaluation that existing datasets cannot provide. Experiments show that 4DGS360 achieves state-of-the-art performance on the iPhone360, iPhone, and DAVIS datasets, both qualitatively and quantitatively.
LoGoColor: Local-Global 3D Colorization for 360° Scenes
Dec 10, 2025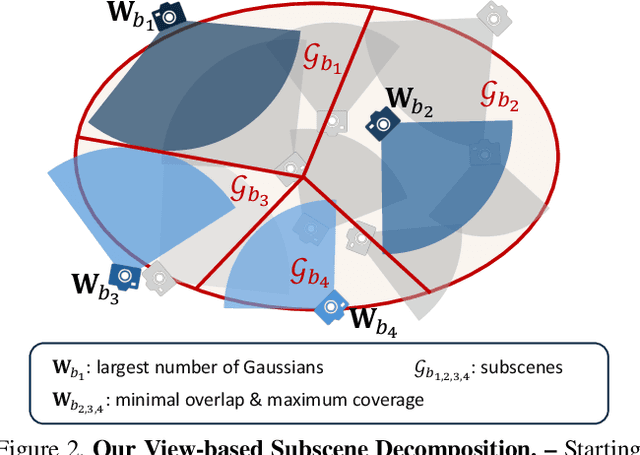
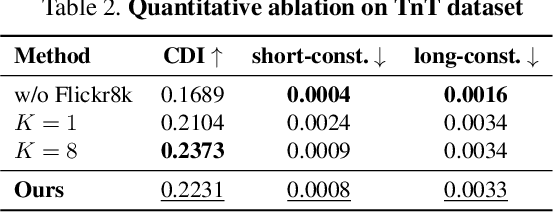
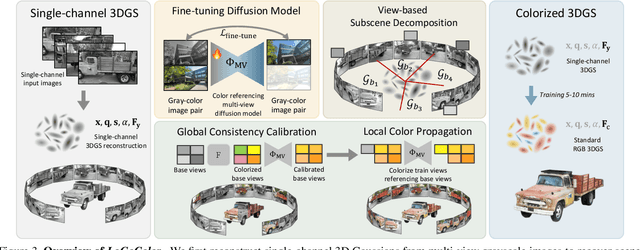

Single-channel 3D reconstruction is widely used in fields such as robotics and medical imaging. While this line of work excels at reconstructing 3D geometry, the outputs are not colored 3D models, thus 3D colorization is required for visualization. Recent 3D colorization studies address this problem by distilling 2D image colorization models. However, these approaches suffer from an inherent inconsistency of 2D image models. This results in colors being averaged during training, leading to monotonous and oversimplified results, particularly in complex 360° scenes. In contrast, we aim to preserve color diversity by generating a new set of consistently colorized training views, thereby bypassing the averaging process. Nevertheless, eliminating the averaging process introduces a new challenge: ensuring strict multi-view consistency across these colorized views. To achieve this, we propose LoGoColor, a pipeline designed to preserve color diversity by eliminating this guidance-averaging process with a `Local-Global' approach: we partition the scene into subscenes and explicitly tackle both inter-subscene and intra-subscene consistency using a fine-tuned multi-view diffusion model. We demonstrate that our method achieves quantitatively and qualitatively more consistent and plausible 3D colorization on complex 360° scenes than existing methods, and validate its superior color diversity using a novel Color Diversity Index.
Duplex: A Device for Large Language Models with Mixture of Experts, Grouped Query Attention, and Continuous Batching
Sep 02, 2024



Large language models (LLMs) have emerged due to their capability to generate high-quality content across diverse contexts. To reduce their explosively increasing demands for computing resources, a mixture of experts (MoE) has emerged. The MoE layer enables exploiting a huge number of parameters with less computation. Applying state-of-the-art continuous batching increases throughput; however, it leads to frequent DRAM access in the MoE and attention layers. We observe that conventional computing devices have limitations when processing the MoE and attention layers, which dominate the total execution time and exhibit low arithmetic intensity (Op/B). Processing MoE layers only with devices targeting low-Op/B such as processing-in-memory (PIM) architectures is challenging due to the fluctuating Op/B in the MoE layer caused by continuous batching. To address these challenges, we propose Duplex, which comprises xPU tailored for high-Op/B and Logic-PIM to effectively perform low-Op/B operation within a single device. Duplex selects the most suitable processor based on the Op/B of each layer within LLMs. As the Op/B of the MoE layer is at least 1 and that of the attention layer has a value of 4-8 for grouped query attention, prior PIM architectures are not efficient, which place processing units inside DRAM dies and only target extremely low-Op/B (under one) operations. Based on recent trends, Logic-PIM adds more through-silicon vias (TSVs) to enable high-bandwidth communication between the DRAM die and the logic die and place powerful processing units on the logic die, which is best suited for handling low-Op/B operations ranging from few to a few dozens. To maximally utilize the xPU and Logic-PIM, we propose expert and attention co-processing.