 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthio-Fake: Cutting-Edge Approaches to Combat Fake News in Under-Resourced Languages Using Explainable AI
Oct 03, 2024
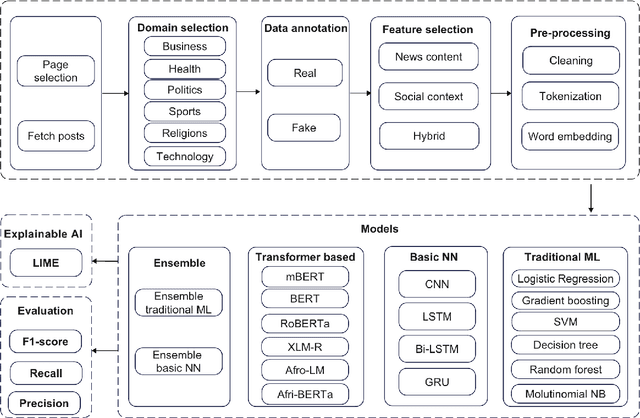
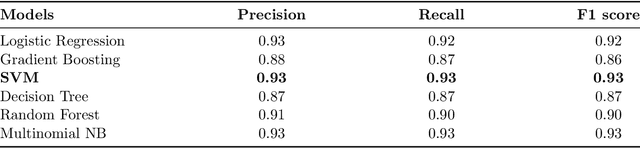

The proliferation of fake news has emerged as a significant threat to the integrity of information dissemination, particularly on social media platforms. Misinformation can spread quickly due to the ease of creating and disseminating content, affecting public opinion and sociopolitical events. Identifying false information is therefore essential to reducing its negative consequences and maintaining the reliability of online news sources. Traditional approaches to fake news detection often rely solely on content-based features, overlooking the crucial role of social context in shaping the perception and propagation of news articles. In this paper, we propose a comprehensive approach that integrates social context-based features with news content features to enhance the accuracy of fake news detection in under-resourced languages. We perform several experiments utilizing a variety of methodologies, including traditional machine learning, neural networks, ensemble learning, and transfer learning. Assessment of the outcomes of the experiments shows that the ensemble learning approach has the highest accuracy, achieving a 0.99 F1 score. Additionally, when compared with monolingual models, the fine-tuned model with the target language outperformed others, achieving a 0.94 F1 score. We analyze the functioning of the models, considering the important features that contribute to model performance, using explainable AI techniques.
Abstractive Text Summarization: State of the Art, Challenges, and Improvements
Sep 04, 2024Specifically focusing on the landscape of abstractive text summarization, as opposed to extractive techniques, this survey presents a comprehensive overview, delving into state-of-the-art techniques, prevailing challenges, and prospective research directions. We categorize the techniques into traditional sequence-to-sequence models, pre-trained large language models, reinforcement learning, hierarchical methods, and multi-modal summarization. Unlike prior works that did not examine complexities, scalability and comparisons of techniques in detail, this review takes a comprehensive approach encompassing state-of-the-art methods, challenges, solutions, comparisons, limitations and charts out future improvements - providing researchers an extensive overview to advance abstractive summarization research. We provide vital comparison tables across techniques categorized - offering insights into model complexity, scalability and appropriate applications. The paper highlights challenges such as inadequate meaning representation, factual consistency, controllable text summarization, cross-lingual summarization, and evaluation metrics, among others. Solutions leveraging knowledge incorporation and other innovative strategies are proposed to address these challenges. The paper concludes by highlighting emerging research areas like factual inconsistency, domain-specific, cross-lingual, multilingual, and long-document summarization, as well as handling noisy data. Our objective is to provide researchers and practitioners with a structured overview of the domain, enabling them to better understand the current landscape and identify potential areas for further research and improvement.
* 9 Tables, 7 Figures
Explainable Artificial Intelligence: A Survey of Needs, Techniques, Applications, and Future Direction
Aug 30, 2024



Artificial intelligence models encounter significant challenges due to their black-box nature, particularly in safety-critical domains such as healthcare, finance, and autonomous vehicles. Explainable Artificial Intelligence (XAI) addresses these challenges by providing explanations for how these models make decisions and predictions, ensuring transparency, accountability, and fairness. Existing studies have examined the fundamental concepts of XAI, its general principles, and the scope of XAI techniques. However, there remains a gap in the literature as there are no comprehensive reviews that delve into the detailed mathematical representations, design methodologies of XAI models, and other associated aspects. This paper provides a comprehensive literature review encompassing common terminologies and definitions, the need for XAI, beneficiaries of XAI, a taxonomy of XAI methods, and the application of XAI methods in different application areas. The survey is aimed at XAI researchers, XAI practitioners, AI model developers, and XAI beneficiaries who are interested in enhancing the trustworthiness, transparency, accountability, and fairness of their AI models.
A Survey of Malware Detection Using Deep Learning
Jul 27, 2024



The problem of malicious software (malware) detection and classification is a complex task, and there is no perfect approach. There is still a lot of work to be done. Unlike most other research areas, standard benchmarks are difficult to find for malware detection. This paper aims to investigate recent advances in malware detection on MacOS, Windows, iOS, Android, and Linux using deep learning (DL) by investigating DL in text and image classification, the use of pre-trained and multi-task learning models for malware detection approaches to obtain high accuracy and which the best approach if we have a standard benchmark dataset. We discuss the issues and the challenges in malware detection using DL classifiers by reviewing the effectiveness of these DL classifiers and their inability to explain their decisions and actions to DL developers presenting the need to use Explainable Machine Learning (XAI) or Interpretable Machine Learning (IML) programs. Additionally, we discuss the impact of adversarial attacks on deep learning models, negatively affecting their generalization capabilities and resulting in poor performance on unseen data. We believe there is a need to train and test the effectiveness and efficiency of the current state-of-the-art deep learning models on different malware datasets. We examine eight popular DL approaches on various datasets. This survey will help researchers develop a general understanding of malware recognition using deep learning.
MaskPure: Improving Defense Against Text Adversaries with Stochastic Purification
Jun 18, 2024



The improvement of language model robustness, including successful defense against adversarial attacks, remains an open problem. In computer vision settings, the stochastic noising and de-noising process provided by diffusion models has proven useful for purifying input images, thus improving model robustness against adversarial attacks. Similarly, some initial work has explored the use of random noising and de-noising to mitigate adversarial attacks in an NLP setting, but improving the quality and efficiency of these methods is necessary for them to remain competitive. We extend upon methods of input text purification that are inspired by diffusion processes, which randomly mask and refill portions of the input text before classification. Our novel method, MaskPure, exceeds or matches robustness compared to other contemporary defenses, while also requiring no adversarial classifier training and without assuming knowledge of the attack type. In addition, we show that MaskPure is provably certifiably robust. To our knowledge, MaskPure is the first stochastic-purification method with demonstrated success against both character-level and word-level attacks, indicating the generalizable and promising nature of stochastic denoising defenses. In summary: the MaskPure algorithm bridges literature on the current strongest certifiable and empirical adversarial defense methods, showing that both theoretical and practical robustness can be obtained together. Code is available on GitHub at https://github.com/hubarruby/MaskPure.
Deep Multi-Task Learning for Malware Image Classification
May 09, 2024



Malicious software is a pernicious global problem. A novel multi-task learning framework is proposed in this paper for malware image classification for accurate and fast malware detection. We generate bitmap (BMP) and (PNG) images from malware features, which we feed to a deep learning classifier. Our state-of-the-art multi-task learning approach has been tested on a new dataset, for which we have collected approximately 100,000 benign and malicious PE, APK, Mach-o, and ELF examples. Experiments with seven tasks tested with 4 activation functions, ReLU, LeakyReLU, PReLU, and ELU separately demonstrate that PReLU gives the highest accuracy of more than 99.87% on all tasks. Our model can effectively detect a variety of obfuscation methods like packing, encryption, and instruction overlapping, strengthing the beneficial claims of our model, in addition to achieving the state-of-art methods in terms of accuracy.
CNN-LSTM and Transfer Learning Models for Malware Classification based on Opcodes and API Calls
May 04, 2024



In this paper, we propose a novel model for a malware classification system based on Application Programming Interface (API) calls and opcodes, to improve classification accuracy. This system uses a novel design of combined Convolutional Neural Network and Long Short-Term Memory. We extract opcode sequences and API Calls from Windows malware samples for classification. We transform these features into N-grams (N = 2, 3, and 10)-gram sequences. Our experiments on a dataset of 9,749,57 samples produce high accuracy of 99.91% using the 8-gram sequences. Our method significantly improves the malware classification performance when using a wide range of recent deep learning architectures, leading to state-of-the-art performance. In particular, we experiment with ConvNeXt-T, ConvNeXt-S, RegNetY-4GF, RegNetY-8GF, RegNetY-12GF, EfficientNetV2, Sequencer2D-L, Swin-T, ViT-G/14, ViT-Ti, ViT-S, VIT-B, VIT-L, and MaxViT-B. Among these architectures, Swin-T and Sequencer2D-L architectures achieved high accuracies of 99.82% and 99.70%, respectively, comparable to our CNN-LSTM architecture although not surpassing it.
EthioMT: Parallel Corpus for Low-resource Ethiopian Languages
Mar 28, 2024



Recent research in natural language processing (NLP) has achieved impressive performance in tasks such as machine translation (MT), news classification, and question-answering in high-resource languages. However, the performance of MT leaves much to be desired for low-resource languages. This is due to the smaller size of available parallel corpora in these languages, if such corpora are available at all. NLP in Ethiopian languages suffers from the same issues due to the unavailability of publicly accessible datasets for NLP tasks, including MT. To help the research community and foster research for Ethiopian languages, we introduce EthioMT -- a new parallel corpus for 15 languages. We also create a new benchmark by collecting a dataset for better-researched languages in Ethiopia. We evaluate the newly collected corpus and the benchmark dataset for 23 Ethiopian languages using transformer and fine-tuning approaches.
Language Model Sentence Completion with a Parser-Driven Rhetorical Control Method
Feb 09, 2024Controlled text generation (CTG) seeks to guide large language model (LLM) output to produce text that conforms to desired criteria. The current study presents a novel CTG algorithm that enforces adherence toward specific rhetorical relations in an LLM sentence-completion context by a parser-driven decoding scheme that requires no model fine-tuning. The method is validated both with automatic and human evaluation. The code is accessible on GitHub.
Action-Item-Driven Summarization of Long Meeting Transcripts
Jan 06, 2024

The increased prevalence of online meetings has significantly enhanced the practicality of a model that can automatically generate the summary of a given meeting. This paper introduces a novel and effective approach to automate the generation of meeting summaries. Current approaches to this problem generate general and basic summaries, considering the meeting simply as a long dialogue. However, our novel algorithms can generate abstractive meeting summaries that are driven by the action items contained in the meeting transcript. This is done by recursively generating summaries and employing our action-item extraction algorithm for each section of the meeting in parallel. All of these sectional summaries are then combined and summarized together to create a coherent and action-item-driven summary. In addition, this paper introduces three novel methods for dividing up long transcripts into topic-based sections to improve the time efficiency of our algorithm, as well as to resolve the issue of large language models (LLMs) forgetting long-term dependencies. Our pipeline achieved a BERTScore of 64.98 across the AMI corpus, which is an approximately 4.98% increase from the current state-of-the-art result produced by a fine-tuned BART (Bidirectional and Auto-Regressive Transformers) model.