 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIFA: Fast Inference Approximation for Action Segmentation
Aug 09, 2021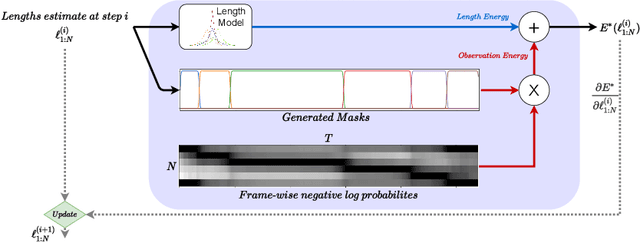
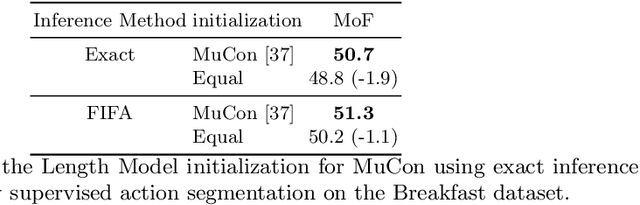
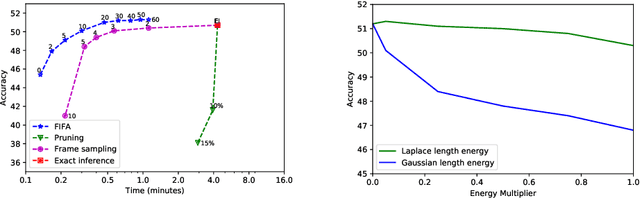
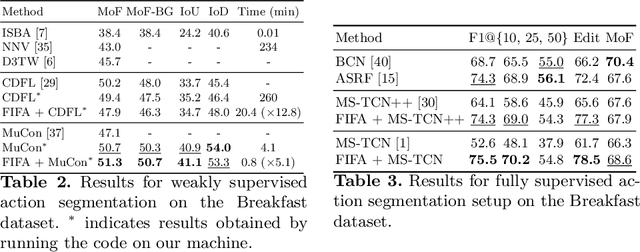
We introduce FIFA, a fast approximate inference method for action segmentation and alignment. Unlike previous approaches, FIFA does not rely on expensive dynamic programming for inference. Instead, it uses an approximate differentiable energy function that can be minimized using gradient-descent. FIFA is a general approach that can replace exact inference improving its speed by more than 5 times while maintaining its performance. FIFA is an anytime inference algorithm that provides a better speed vs. accuracy trade-off compared to exact inference. We apply FIFA on top of state-of-the-art approaches for weakly supervised action segmentation and alignment as well as fully supervised action segmentation. FIFA achieves state-of-the-art results on most metrics on two action segmentation datasets.
Using Visual Anomaly Detection for Task Execution Monitoring
Jul 29, 2021
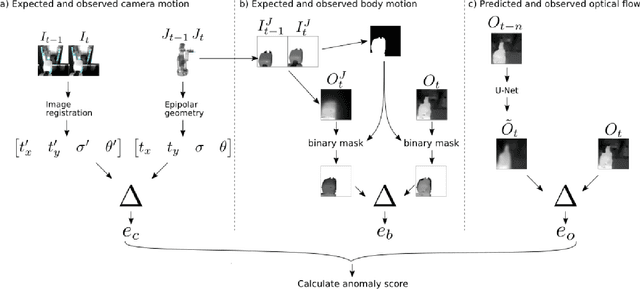

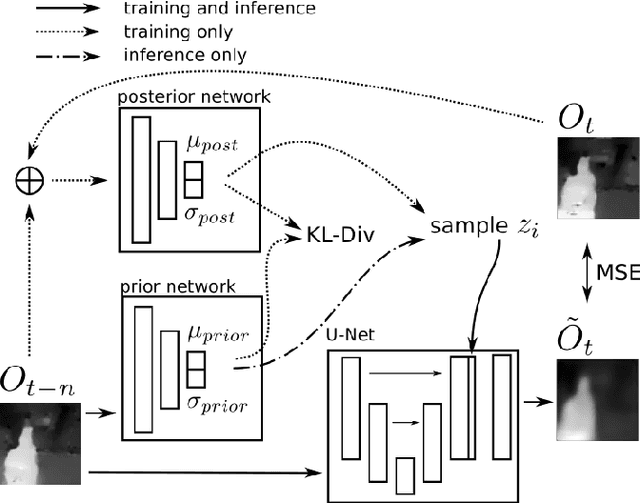
Execution monitoring is essential for robots to detect and respond to failures. Since it is impossible to enumerate all failures for a given task, we learn from successful executions of the task to detect visual anomalies during runtime. Our method learns to predict the motions that occur during the nominal execution of a task, including camera and robot body motion. A probabilistic U-Net architecture is used to learn to predict optical flow, and the robot's kinematics and 3D model are used to model camera and body motion. The errors between the observed and predicted motion are used to calculate an anomaly score. We evaluate our method on a dataset of a robot placing a book on a shelf, which includes anomalies such as falling books, camera occlusions, and robot disturbances. We find that modeling camera and body motion, in addition to the learning-based optical flow prediction, results in an improvement of the area under the receiver operating characteristic curve from 0.752 to 0.804, and the area under the precision-recall curve from 0.467 to 0.549.
Multi-Modal Temporal Convolutional Network for Anticipating Actions in Egocentric Videos
Jul 18, 2021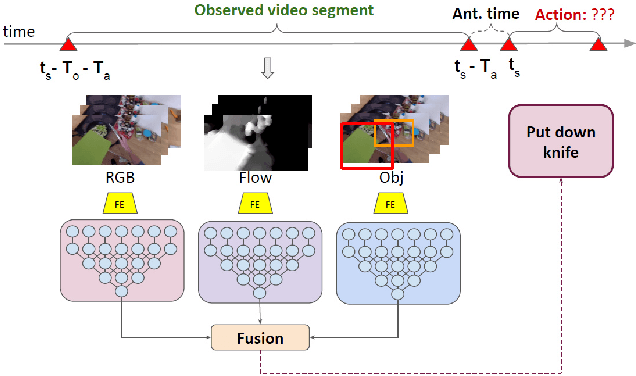
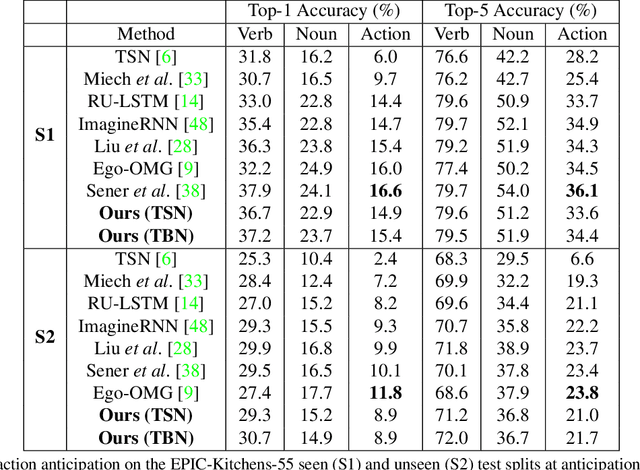
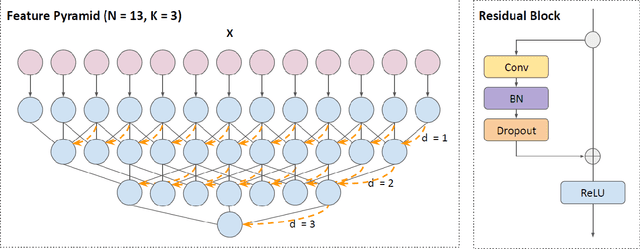
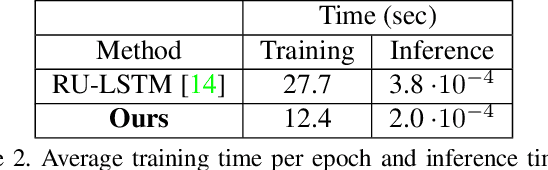
Anticipating human actions is an important task that needs to be addressed for the development of reliable intelligent agents, such as self-driving cars or robot assistants. While the ability to make future predictions with high accuracy is crucial for designing the anticipation approaches, the speed at which the inference is performed is not less important. Methods that are accurate but not sufficiently fast would introduce a high latency into the decision process. Thus, this will increase the reaction time of the underlying system. This poses a problem for domains such as autonomous driving, where the reaction time is crucial. In this work, we propose a simple and effective multi-modal architecture based on temporal convolutions. Our approach stacks a hierarchy of temporal convolutional layers and does not rely on recurrent layers to ensure a fast prediction. We further introduce a multi-modal fusion mechanism that captures the pairwise interactions between RGB, flow, and object modalities. Results on two large-scale datasets of egocentric videos, EPIC-Kitchens-55 and EPIC-Kitchens-100, show that our approach achieves comparable performance to the state-of-the-art approaches while being significantly faster.
Towards Better Adversarial Synthesis of Human Images from Text
Jul 05, 2021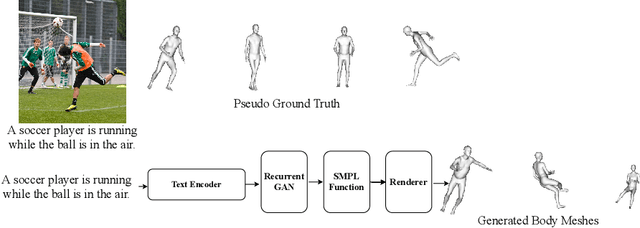
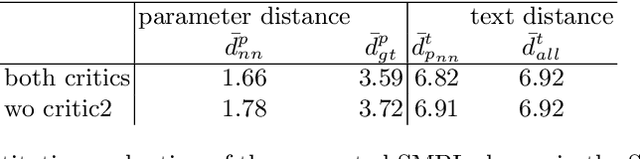

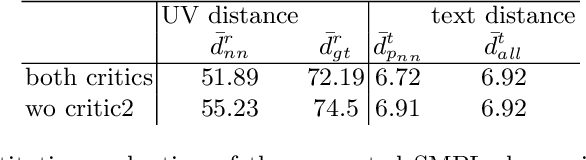
This paper proposes an approach that generates multiple 3D human meshes from text. The human shapes are represented by 3D meshes based on the SMPL model. The model's performance is evaluated on the COCO dataset, which contains challenging human shapes and intricate interactions between individuals. The model is able to capture the dynamics of the scene and the interactions between individuals based on text. We further show how using such a shape as input to image synthesis frameworks helps to constrain the network to synthesize humans with realistic human shapes.
Learning to Generate Novel Scene Compositions from Single Images and Videos
May 12, 2021
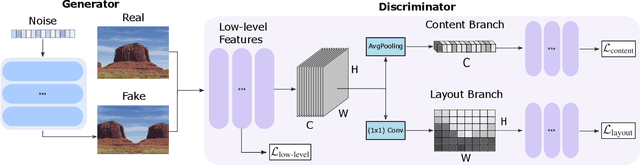


Training GANs in low-data regimes remains a challenge, as overfitting often leads to memorization or training divergence. In this work, we introduce One-Shot GAN that can learn to generate samples from a training set as little as one image or one video. We propose a two-branch discriminator, with content and layout branches designed to judge the internal content separately from the scene layout realism. This allows synthesis of visually plausible, novel compositions of a scene, with varying content and layout, while preserving the context of the original sample. Compared to previous single-image GAN models, One-Shot GAN achieves higher diversity and quality of synthesis. It is also not restricted to the single image setting, successfully learning in the introduced setting of a single video.
Temporal Action Segmentation from Timestamp Supervision
Mar 26, 2021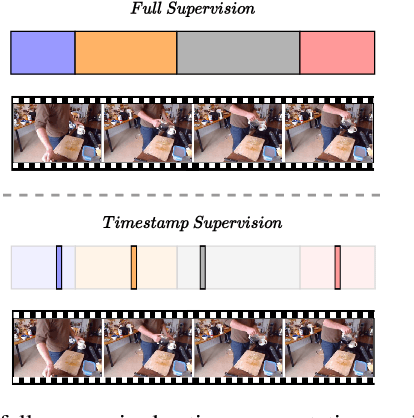
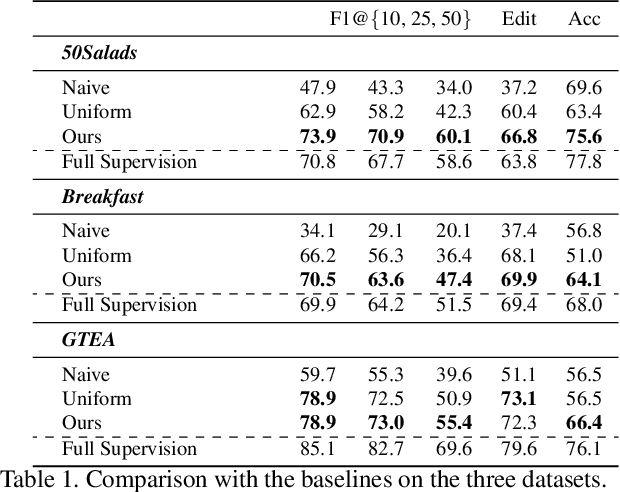
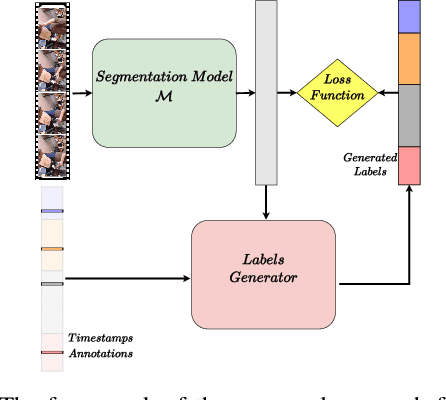
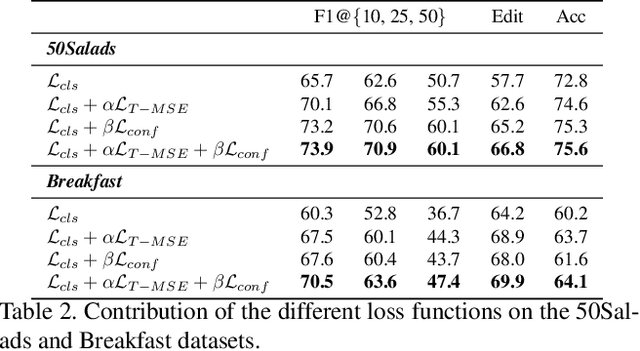
Temporal action segmentation approaches have been very successful recently. However, annotating videos with frame-wise labels to train such models is very expensive and time consuming. While weakly supervised methods trained using only ordered action lists require less annotation effort, the performance is still worse than fully supervised approaches. In this paper, we propose to use timestamp supervision for the temporal action segmentation task. Timestamps require a comparable annotation effort to weakly supervised approaches, and yet provide a more supervisory signal. To demonstrate the effectiveness of timestamp supervision, we propose an approach to train a segmentation model using only timestamps annotations. Our approach uses the model output and the annotated timestamps to generate frame-wise labels by detecting the action changes. We further introduce a confidence loss that forces the predicted probabilities to monotonically decrease as the distance to the timestamps increases. This ensures that all and not only the most distinctive frames of an action are learned during training. The evaluation on four datasets shows that models trained with timestamps annotations achieve comparable performance to the fully supervised approaches.
One-Shot GAN: Learning to Generate Samples from Single Images and Videos
Mar 24, 2021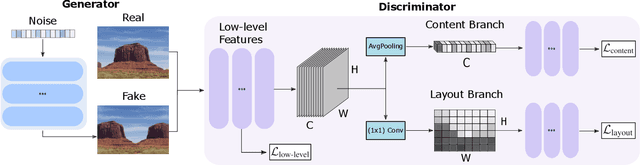
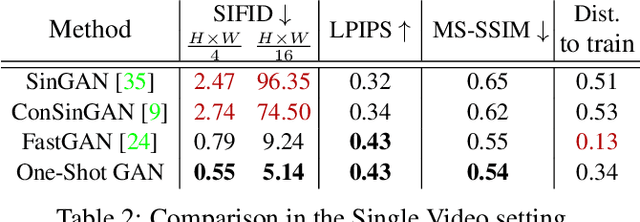

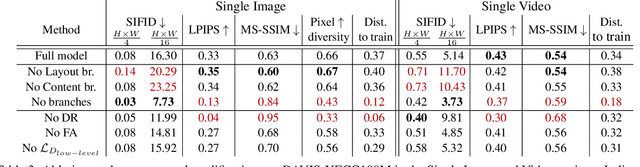
Given a large number of training samples, GANs can achieve remarkable performance for the image synthesis task. However, training GANs in extremely low-data regimes remains a challenge, as overfitting often occurs, leading to memorization or training divergence. In this work, we introduce One-Shot GAN, an unconditional generative model that can learn to generate samples from a single training image or a single video clip. We propose a two-branch discriminator architecture, with content and layout branches designed to judge internal content and scene layout realism separately from each other. This allows synthesis of visually plausible, novel compositions of a scene, with varying content and layout, while preserving the context of the original sample. Compared to previous single-image GAN models, One-Shot GAN generates more diverse, higher quality images, while also not being restricted to a single image setting. We show that our model successfully deals with other one-shot regimes, and introduce a new task of learning generative models from a single video.
Iterative Greedy Matching for 3D Human Pose Tracking from Multiple Views
Jan 24, 2021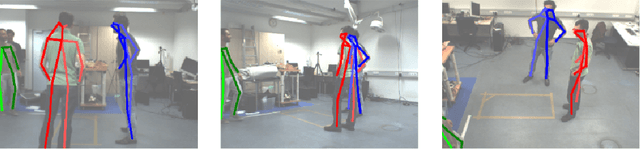
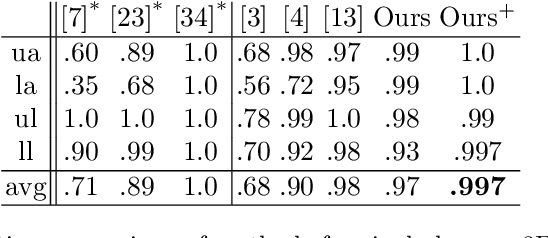

In this work we propose an approach for estimating 3D human poses of multiple people from a set of calibrated cameras. Estimating 3D human poses from multiple views has several compelling properties: human poses are estimated within a global coordinate space and multiple cameras provide an extended field of view which helps in resolving ambiguities, occlusions and motion blur. Our approach builds upon a real-time 2D multi-person pose estimation system and greedily solves the association problem between multiple views. We utilize bipartite matching to track multiple people over multiple frames. This proofs to be especially efficient as problems associated with greedy matching such as occlusion can be easily resolved in 3D. Our approach achieves state-of-the-art results on popular benchmarks and may serve as a baseline for future work.
* German Conference on Pattern Recognition 2019
Hierarchical Graph-RNNs for Action Detection of Multiple Activities
Jan 21, 2021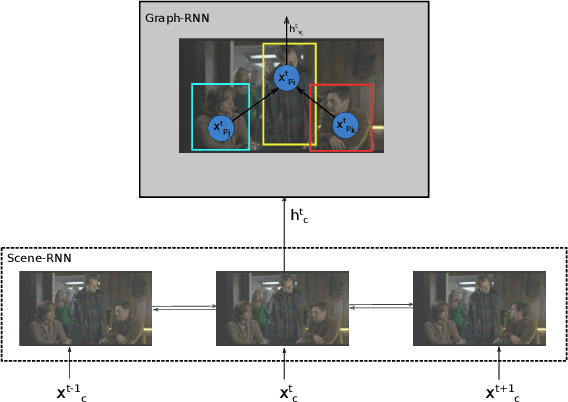



In this paper, we propose an approach that spatially localizes the activities in a video frame where each person can perform multiple activities at the same time. Our approach takes the temporal scene context as well as the relations of the actions of detected persons into account. While the temporal context is modeled by a temporal recurrent neural network (RNN), the relations of the actions are modeled by a graph RNN. Both networks are trained together and the proposed approach achieves state of the art results on the AVA dataset.
Discovering Multi-Label Actor-Action Association in a Weakly Supervised Setting
Jan 21, 2021
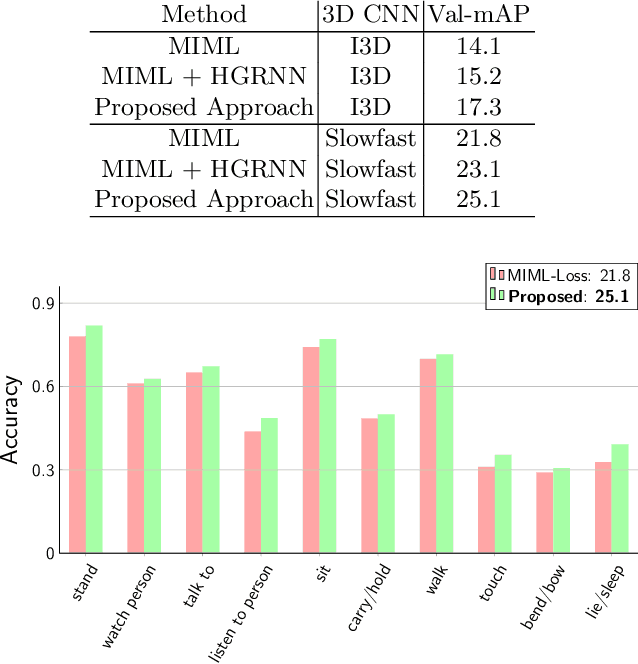
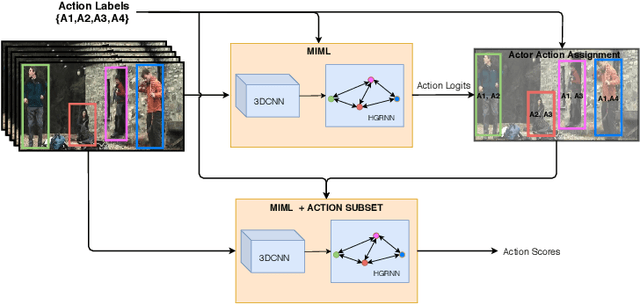
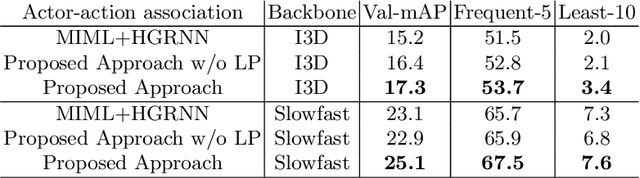
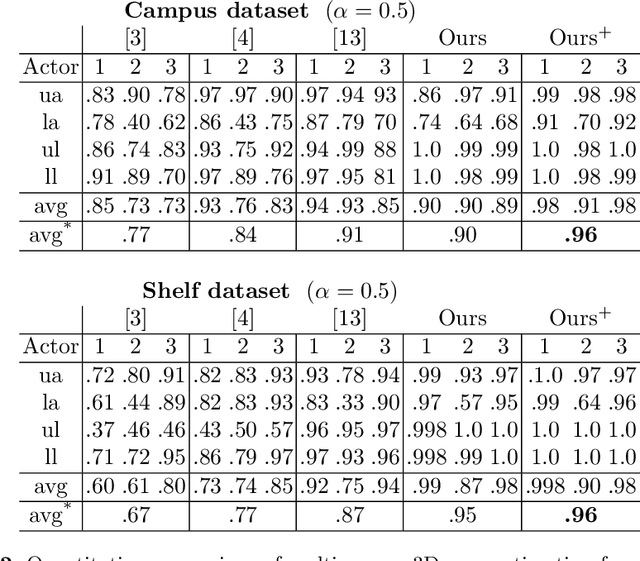
Since collecting and annotating data for spatio-temporal action detection is very expensive, there is a need to learn approaches with less supervision. Weakly supervised approaches do not require any bounding box annotations and can be trained only from labels that indicate whether an action occurs in a video clip. Current approaches, however, cannot handle the case when there are multiple persons in a video that perform multiple actions at the same time. In this work, we address this very challenging task for the first time. We propose a baseline based on multi-instance and multi-label learning. Furthermore, we propose a novel approach that uses sets of actions as representation instead of modeling individual action classes. Since computing, the probabilities for the full power set becomes intractable as the number of action classes increases, we assign an action set to each detected person under the constraint that the assignment is consistent with the annotation of the video clip. We evaluate the proposed approach on the challenging AVA dataset where the proposed approach outperforms the MIML baseline and is competitive to fully supervised approaches.