 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystèmes du LIA à DEFT'13
Feb 21, 2017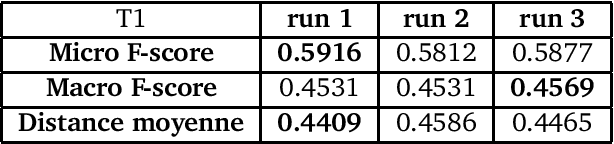


The 2013 D\'efi de Fouille de Textes (DEFT) campaign is interested in two types of language analysis tasks, the document classification and the information extraction in the specialized domain of cuisine recipes. We present the systems that the LIA has used in DEFT 2013. Our systems show interesting results, even though the complexity of the proposed tasks.
* 12 pages, 3 tables, (Paper in French)
Efficient Social Network Multilingual Classification using Character, POS n-grams and Dynamic Normalization
Feb 21, 2017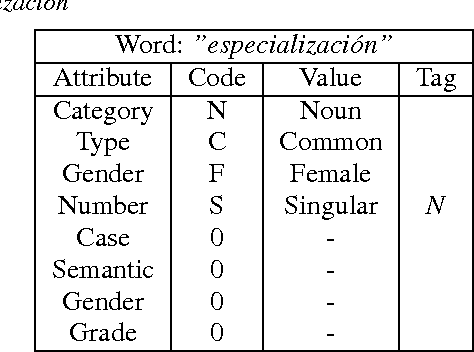
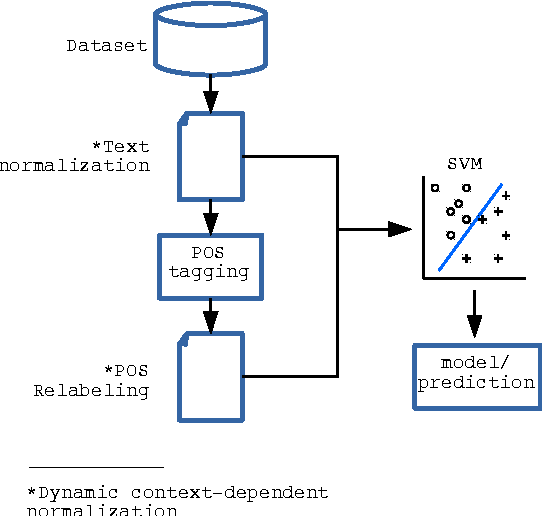

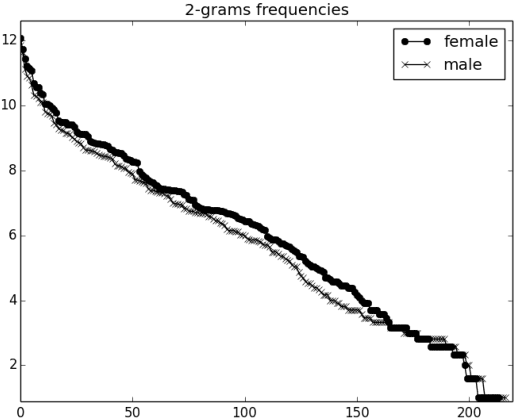
In this paper we describe a dynamic normalization process applied to social network multilingual documents (Facebook and Twitter) to improve the performance of the Author profiling task for short texts. After the normalization process, $n$-grams of characters and n-grams of POS tags are obtained to extract all the possible stylistic information encoded in the documents (emoticons, character flooding, capital letters, references to other users, hyperlinks, hashtags, etc.). Experiments with SVM showed up to 90% of performance.
* 8 pages, 6 figures, Conference paper
LIA-RAG: a system based on graphs and divergence of probabilities applied to Speech-To-Text Summarization
Jan 26, 2016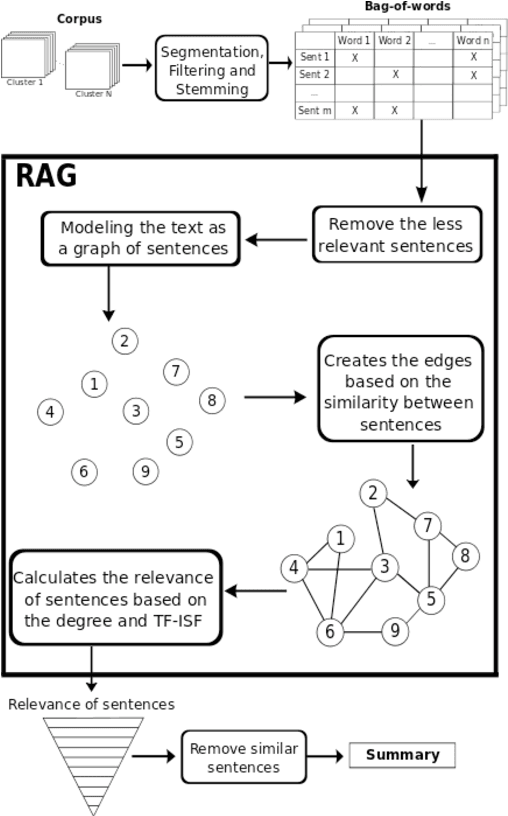
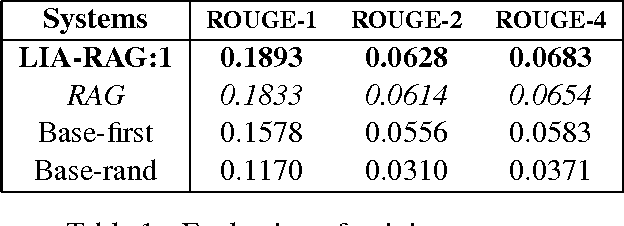
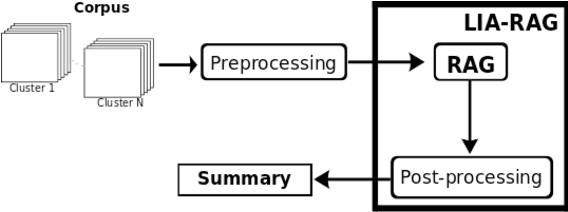

This paper aims to introduces a new algorithm for automatic speech-to-text summarization based on statistical divergences of probabilities and graphs. The input is a text from speech conversations with noise, and the output a compact text summary. Our results, on the pilot task CCCS Multiling 2015 French corpus are very encouraging
Regroupement sémantique de définitions en espagnol
Jan 20, 2015
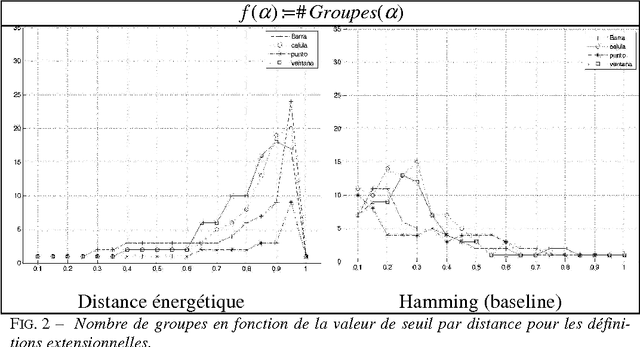
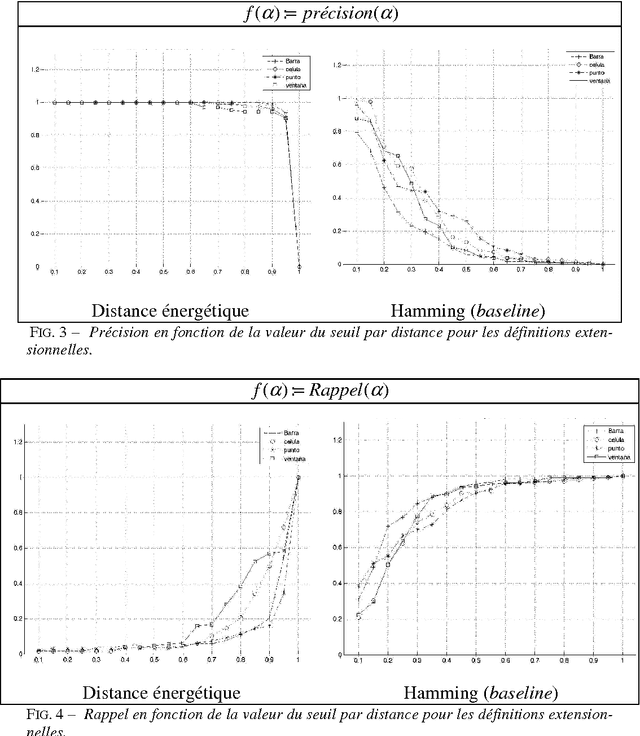
This article focuses on the description and evaluation of a new unsupervised learning method of clustering of definitions in Spanish according to their semantic. Textual Energy was used as a clustering measure, and we study an adaptation of the Precision and Recall to evaluate our method.
Optimisation using Natural Language Processing: Personalized Tour Recommendation for Museums
Jan 06, 2015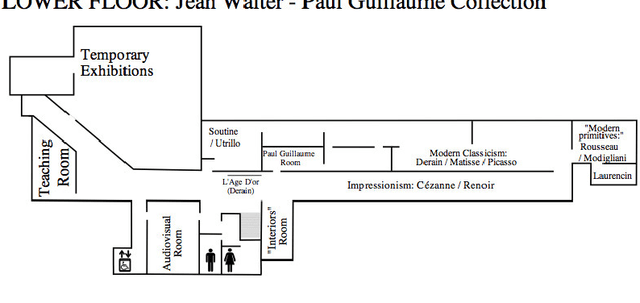
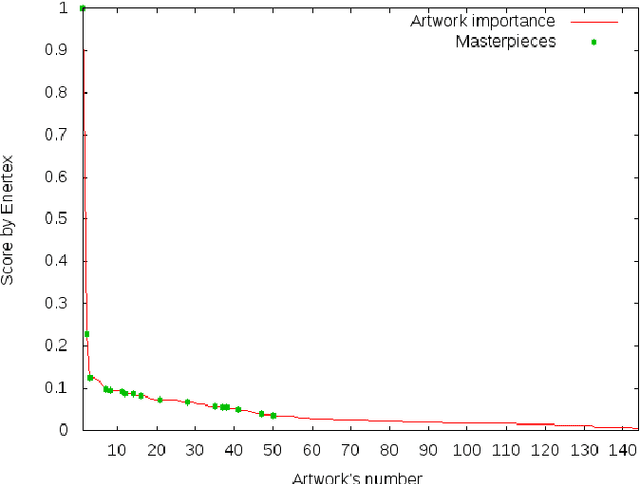
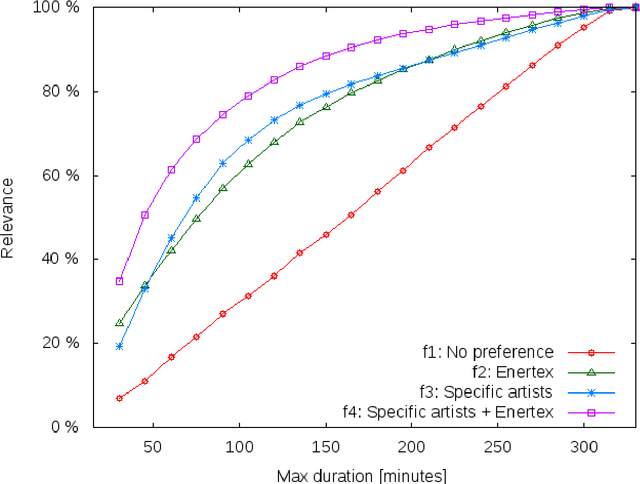
This paper proposes a new method to provide personalized tour recommendation for museum visits. It combines an optimization of preference criteria of visitors with an automatic extraction of artwork importance from museum information based on Natural Language Processing using textual energy. This project includes researchers from computer and social sciences. Some results are obtained with numerical experiments. They show that our model clearly improves the satisfaction of the visitor who follows the proposed tour. This work foreshadows some interesting outcomes and applications about on-demand personalized visit of museums in a very near future.
Un résumeur à base de graphes, indépéndant de la langue
Jan 06, 2015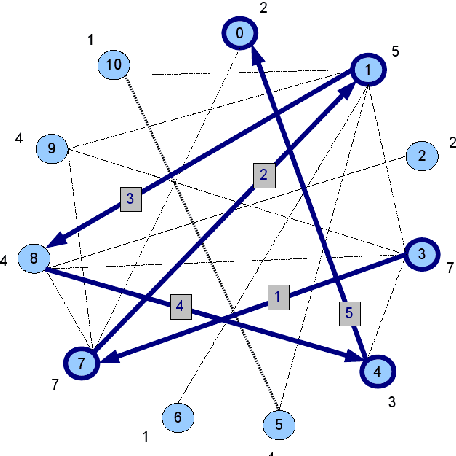

In this paper we present REG, a graph-based approach for study a fundamental problem of Natural Language Processing (NLP): the automatic text summarization. The algorithm maps a document as a graph, then it computes the weight of their sentences. We have applied this approach to summarize documents in three languages.
Sentence Compression in Spanish driven by Discourse Segmentation and Language Models
Dec 17, 2012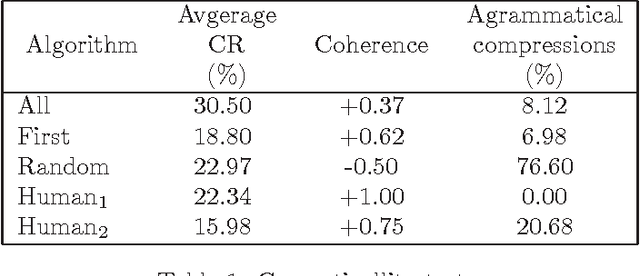

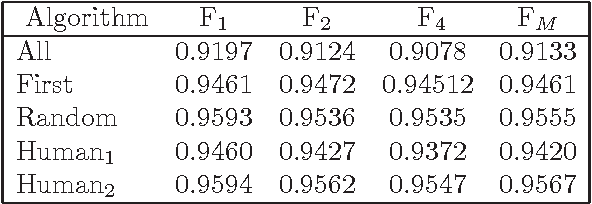
Previous works demonstrated that Automatic Text Summarization (ATS) by sentences extraction may be improved using sentence compression. In this work we present a sentence compressions approach guided by level-sentence discourse segmentation and probabilistic language models (LM). The results presented here show that the proposed solution is able to generate coherent summaries with grammatical compressed sentences. The approach is simple enough to be transposed into other languages.
Condensés de textes par des méthodes numériques
Dec 09, 2012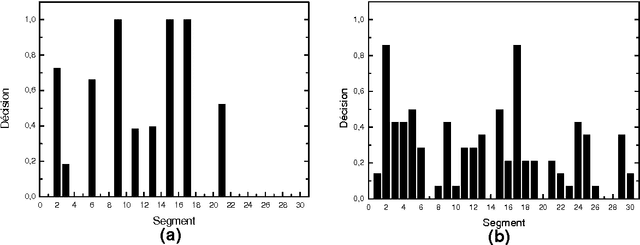
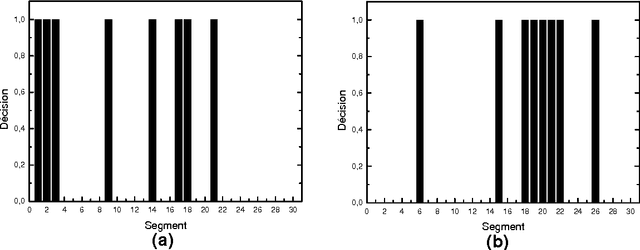
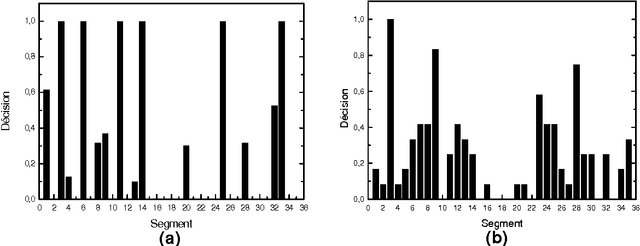
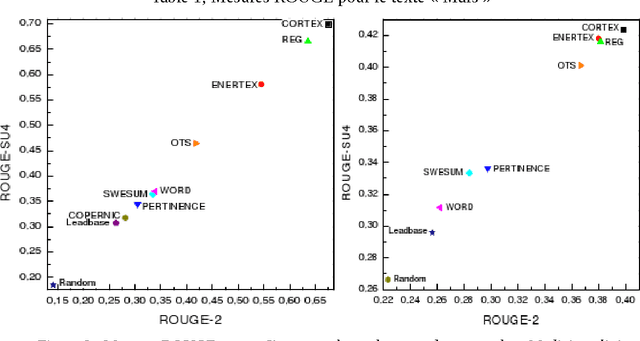
Since information in electronic form is already a standard, and that the variety and the quantity of information become increasingly large, the methods of summarizing or automatic condensation of texts is a critical phase of the analysis of texts. This article describes CORTEX a system based on numerical methods, which allows obtaining a condensation of a text, which is independent of the topic and of the length of the text. The structure of the system enables it to find the abstracts in French or Spanish in very short times.
Artex is AnotheR TEXt summarizer
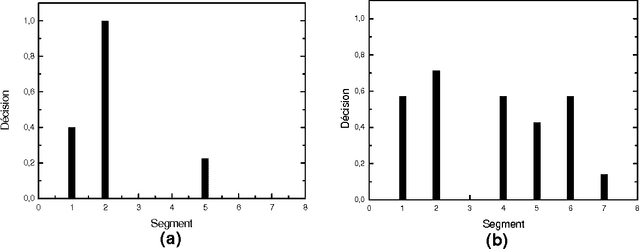
Oct 11, 2012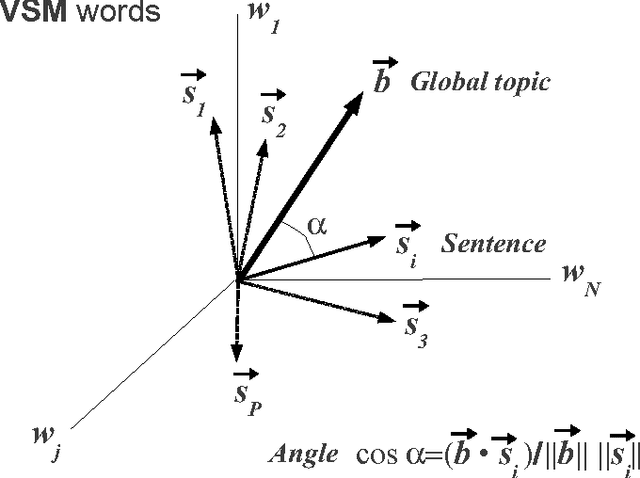
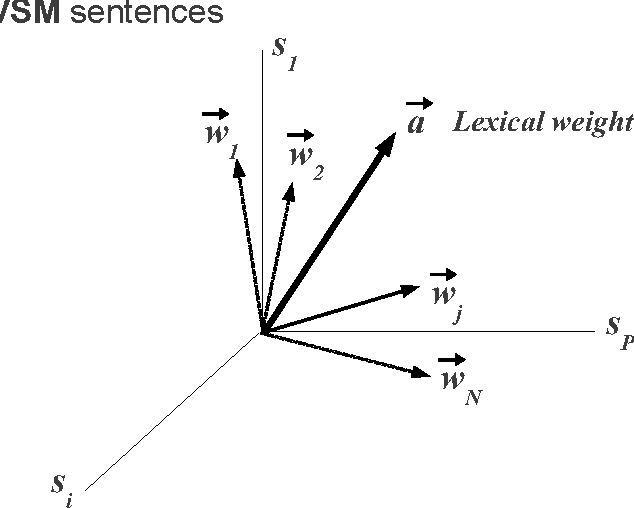
This paper describes Artex, another algorithm for Automatic Text Summarization. In order to rank sentences, a simple inner product is calculated between each sentence, a document vector (text topic) and a lexical vector (vocabulary used by a sentence). Summaries are then generated by assembling the highest ranked sentences. No ruled-based linguistic post-processing is necessary in order to obtain summaries. Tests over several datasets (coming from Document Understanding Conferences (DUC), Text Analysis Conferences (TAC), evaluation campaigns, etc.) in French, English and Spanish have shown that summarizer achieves interesting results.
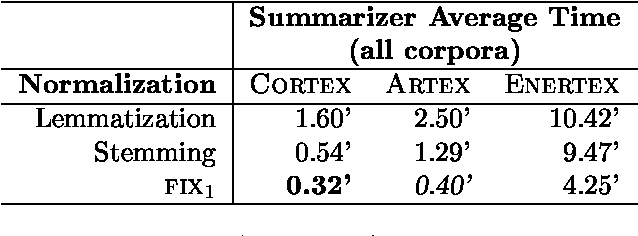
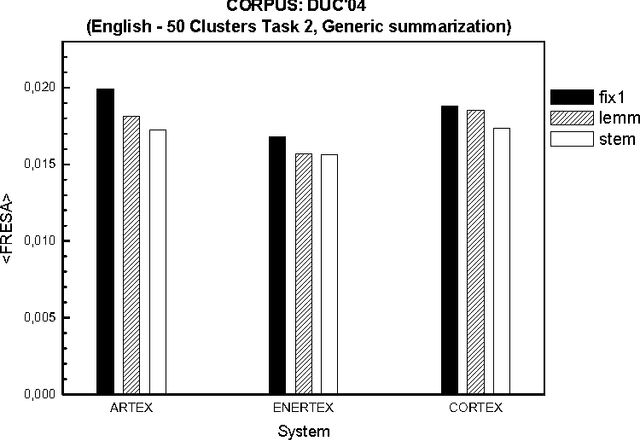
Beyond Stemming and Lemmatization: Ultra-stemming to Improve Automatic Text Summarization
Sep 14, 2012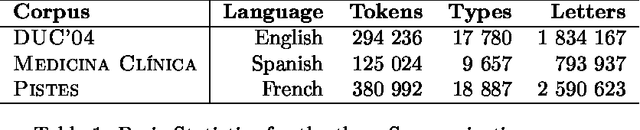
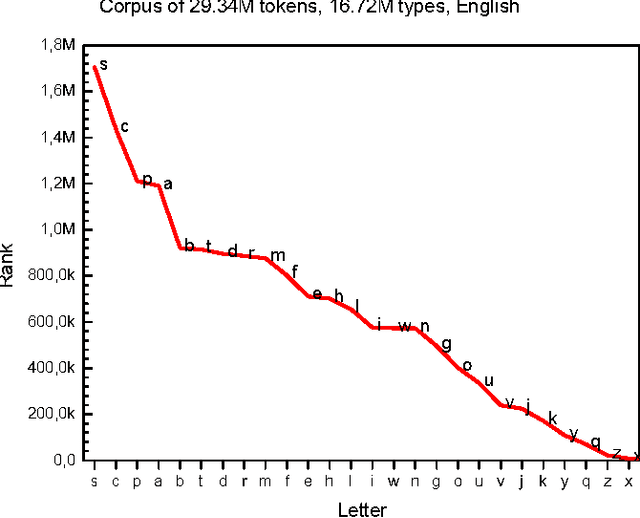
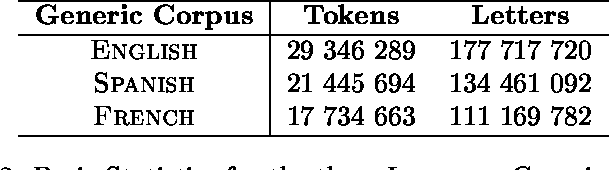
In Automatic Text Summarization, preprocessing is an important phase to reduce the space of textual representation. Classically, stemming and lemmatization have been widely used for normalizing words. However, even using normalization on large texts, the curse of dimensionality can disturb the performance of summarizers. This paper describes a new method for normalization of words to further reduce the space of representation. We propose to reduce each word to its initial letters, as a form of Ultra-stemming. The results show that Ultra-stemming not only preserve the content of summaries produced by this representation, but often the performances of the systems can be dramatically improved. Summaries on trilingual corpora were evaluated automatically with Fresa. Results confirm an increase in the performance, regardless of summarizer system used.