 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Fidelity End-to-End Video Encoder Pre-training for Temporal Action Localization
Mar 30, 2021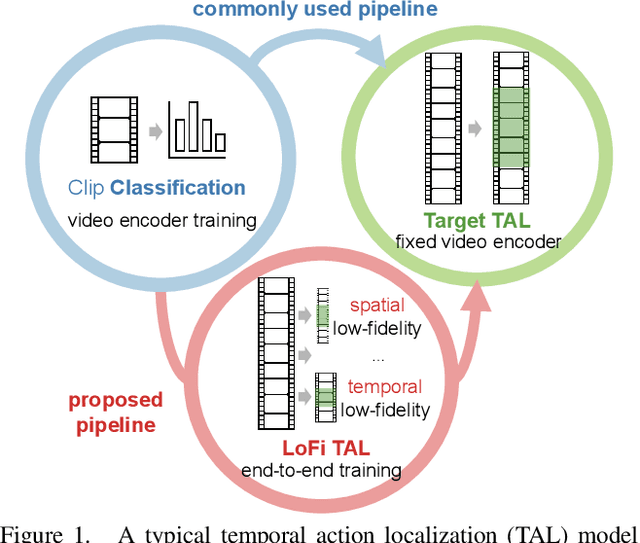
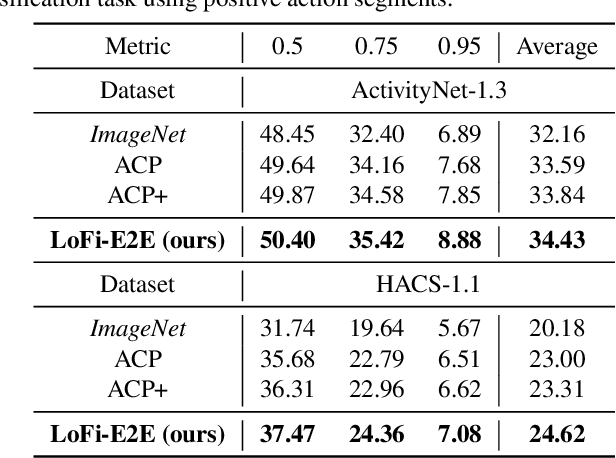
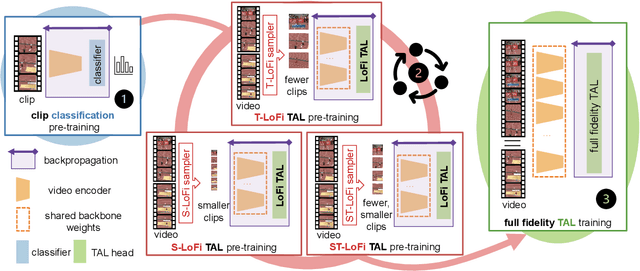
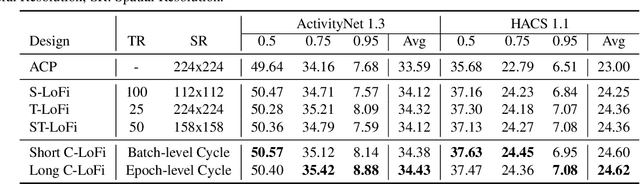
Temporal action localization (TAL) is a fundamental yet challenging task in video understanding. Existing TAL methods rely on pre-training a video encoder through action classification supervision. This results in a task discrepancy problem for the video encoder -- trained for action classification, but used for TAL. Intuitively, end-to-end model optimization is a good solution. However, this is not operable for TAL subject to the GPU memory constraints, due to the prohibitive computational cost in processing long untrimmed videos. In this paper, we resolve this challenge by introducing a novel low-fidelity end-to-end (LoFi) video encoder pre-training method. Instead of always using the full training configurations for TAL learning, we propose to reduce the mini-batch composition in terms of temporal, spatial or spatio-temporal resolution so that end-to-end optimization for the video encoder becomes operable under the memory conditions of a mid-range hardware budget. Crucially, this enables the gradient to flow backward through the video encoder from a TAL loss supervision, favourably solving the task discrepancy problem and providing more effective feature representations. Extensive experiments show that the proposed LoFi pre-training approach can significantly enhance the performance of existing TAL methods. Encouragingly, even with a lightweight ResNet18 based video encoder in a single RGB stream, our method surpasses two-stream ResNet50 based alternatives with expensive optical flow, often by a good margin.
Boundary-sensitive Pre-training for Temporal Localization in Videos
Nov 24, 2020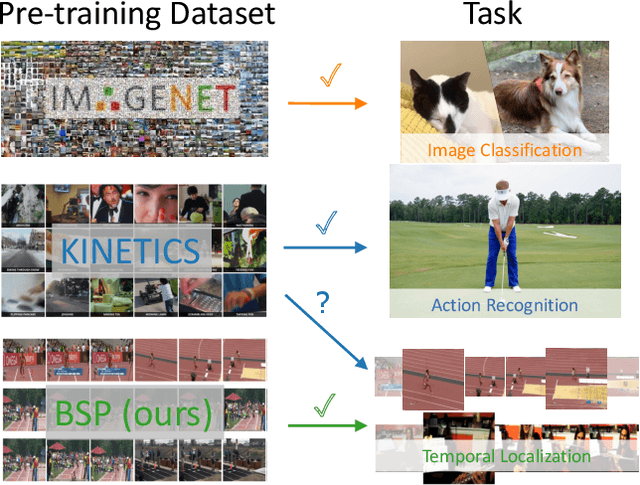
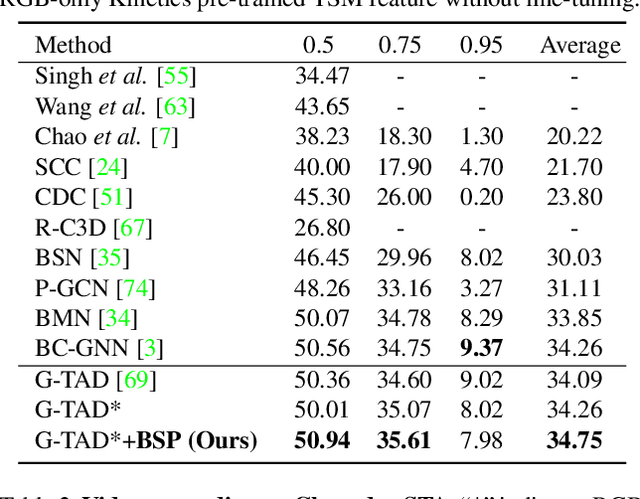

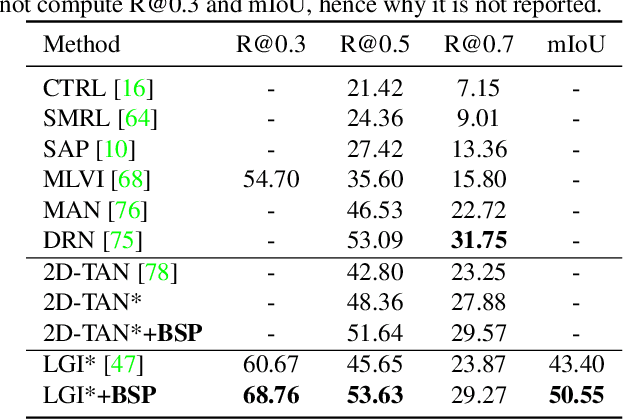
Many video analysis tasks require temporal localization thus detection of content changes. However, most existing models developed for these tasks are pre-trained on general video action classification tasks. This is because large scale annotation of temporal boundaries in untrimmed videos is expensive. Therefore no suitable datasets exist for temporal boundary-sensitive pre-training. In this paper for the first time, we investigate model pre-training for temporal localization by introducing a novel boundary-sensitive pretext (BSP) task. Instead of relying on costly manual annotations of temporal boundaries, we propose to synthesize temporal boundaries in existing video action classification datasets. With the synthesized boundaries, BSP can be simply conducted via classifying the boundary types. This enables the learning of video representations that are much more transferable to downstream temporal localization tasks. Extensive experiments show that the proposed BSP is superior and complementary to the existing action classification based pre-training counterpart, and achieves new state-of-the-art performance on several temporal localization tasks.
Egocentric Action Recognition by Video Attention and Temporal Context
Jul 03, 2020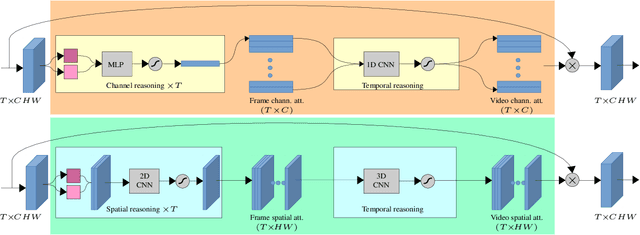
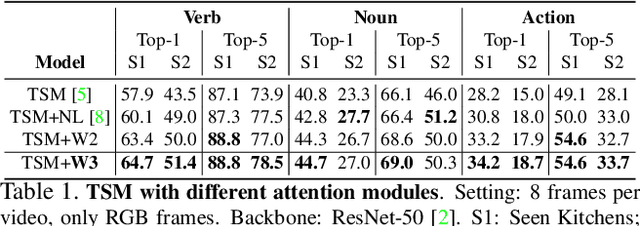
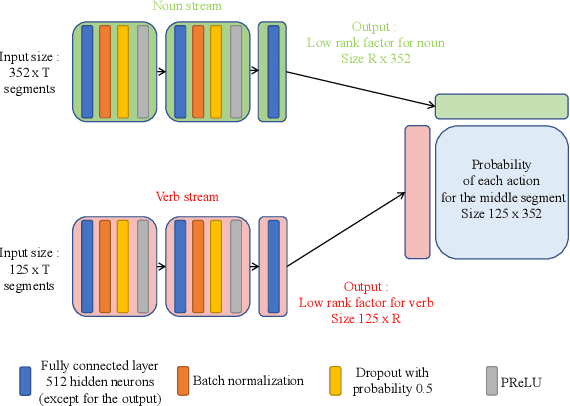
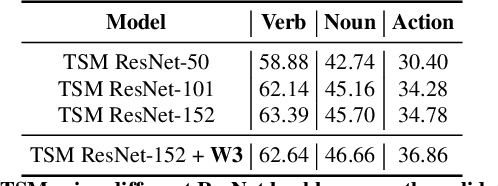
We present the submission of Samsung AI Centre Cambridge to the CVPR2020 EPIC-Kitchens Action Recognition Challenge. In this challenge, action recognition is posed as the problem of simultaneously predicting a single `verb' and `noun' class label given an input trimmed video clip. That is, a `verb' and a `noun' together define a compositional `action' class. The challenging aspects of this real-life action recognition task include small fast moving objects, complex hand-object interactions, and occlusions. At the core of our submission is a recently-proposed spatial-temporal video attention model, called `W3' (`What-Where-When') attention~\cite{perez2020knowing}. We further introduce a simple yet effective contextual learning mechanism to model `action' class scores directly from long-term temporal behaviour based on the `verb' and `noun' prediction scores. Our solution achieves strong performance on the challenge metrics without using object-specific reasoning nor extra training data. In particular, our best solution with multimodal ensemble achieves the 2$^{nd}$ best position for `verb', and 3$^{rd}$ best for `noun' and `action' on the Seen Kitchens test set.
Knowing What, Where and When to Look: Efficient Video Action Modeling with Attention
Apr 02, 2020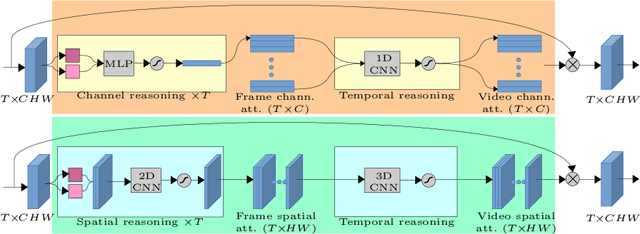
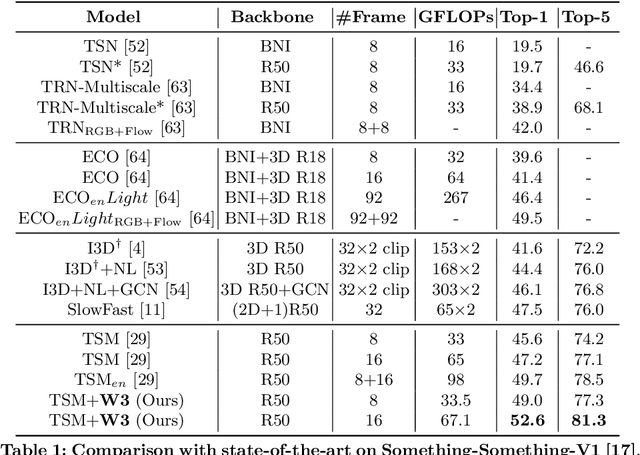
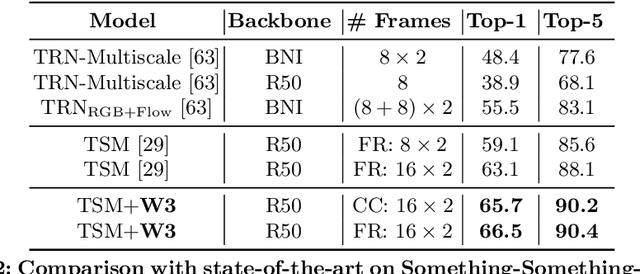
Attentive video modeling is essential for action recognition in unconstrained videos due to their rich yet redundant information over space and time. However, introducing attention in a deep neural network for action recognition is challenging for two reasons. First, an effective attention module needs to learn what (objects and their local motion patterns), where (spatially), and when (temporally) to focus on. Second, a video attention module must be efficient because existing action recognition models already suffer from high computational cost. To address both challenges, a novel What-Where-When (W3) video attention module is proposed. Departing from existing alternatives, our W3 module models all three facets of video attention jointly. Crucially, it is extremely efficient by factorizing the high-dimensional video feature data into low-dimensional meaningful spaces (1D channel vector for `what' and 2D spatial tensors for `where'), followed by lightweight temporal attention reasoning. Extensive experiments show that our attention model brings significant improvements to existing action recognition models, achieving new state-of-the-art performance on a number of benchmarks.
Incremental Few-Shot Object Detection
Mar 12, 2020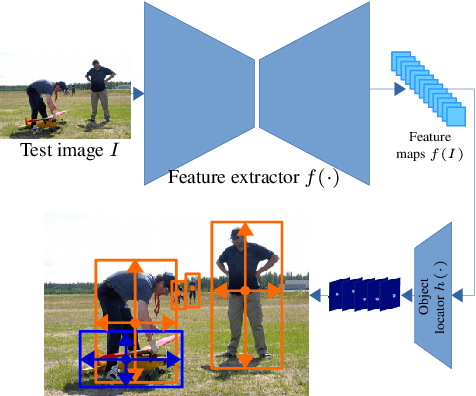
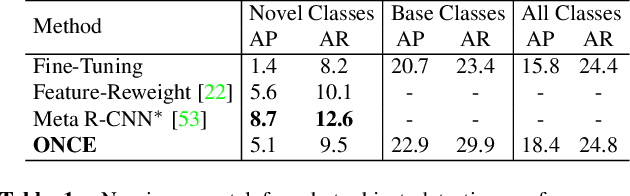
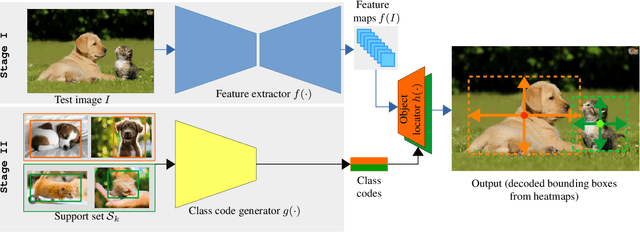
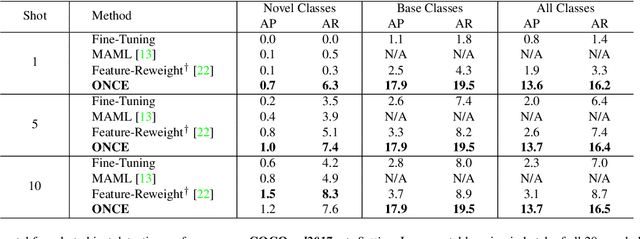
Most existing object detection methods rely on the availability of abundant labelled training samples per class and offline model training in a batch mode. These requirements substantially limit their scalability to open-ended accommodation of novel classes with limited labelled training data. We present a study aiming to go beyond these limitations by considering the Incremental Few-Shot Detection (iFSD) problem setting, where new classes must be registered incrementally (without revisiting base classes) and with few examples. To this end we propose OpeN-ended Centre nEt (ONCE), a detector designed for incrementally learning to detect novel class objects with few examples. This is achieved by an elegant adaptation of the CentreNet detector to the few-shot learning scenario, and meta-learning a class-specific code generator model for registering novel classes. ONCE fully respects the incremental learning paradigm, with novel class registration requiring only a single forward pass of few-shot training samples, and no access to base classes -- thus making it suitable for deployment on embedded devices. Extensive experiments conducted on both the standard object detection and fashion landmark detection tasks show the feasibility of iFSD for the first time, opening an interesting and very important line of research.
Efficient Progressive Neural Architecture Search
Aug 01, 2018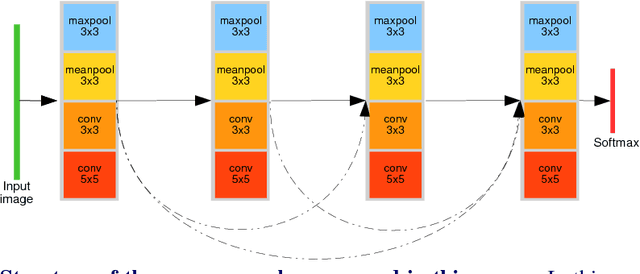
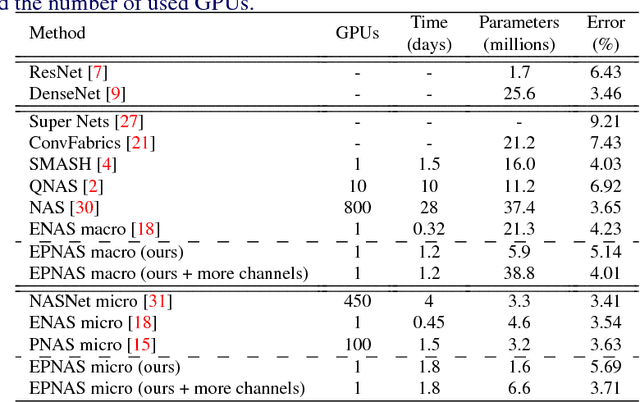
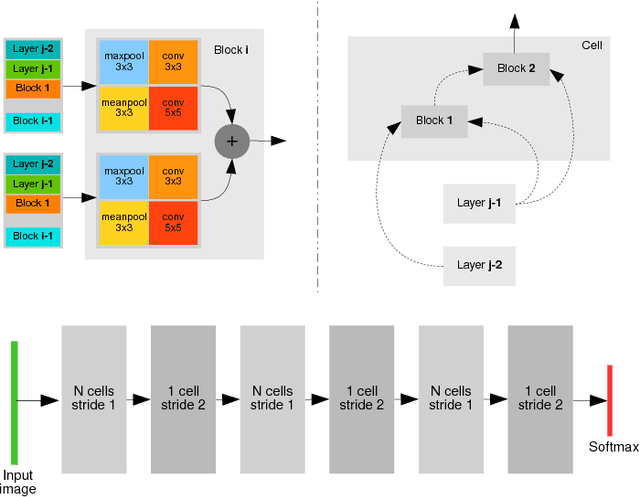
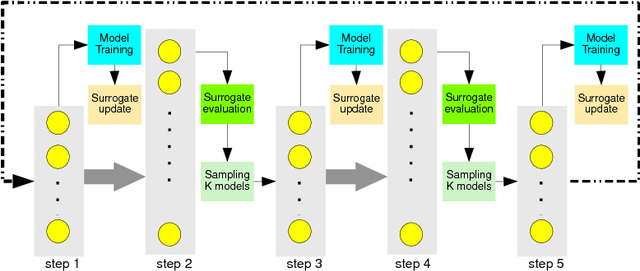
This paper addresses the difficult problem of finding an optimal neural architecture design for a given image classification task. We propose a method that aggregates two main results of the previous state-of-the-art in neural architecture search. These are, appealing to the strong sampling efficiency of a search scheme based on sequential model-based optimization (SMBO), and increasing training efficiency by sharing weights among sampled architectures. Sequential search has previously demonstrated its capabilities to find state-of-the-art neural architectures for image classification. However, its computational cost remains high, even unreachable under modest computational settings. Affording SMBO with weight-sharing alleviates this problem. On the other hand, progressive search with SMBO is inherently greedy, as it leverages a learned surrogate function to predict the validation error of neural architectures. This prediction is directly used to rank the sampled neural architectures. We propose to attenuate the greediness of the original SMBO method by relaxing the role of the surrogate function so it predicts architecture sampling probability instead. We demonstrate with experiments on the CIFAR-10 dataset that our method, denominated Efficient progressive neural architecture search (EPNAS), leads to increased search efficiency, while retaining competitiveness of found architectures.
Learning how to be robust: Deep polynomial regression
May 23, 2018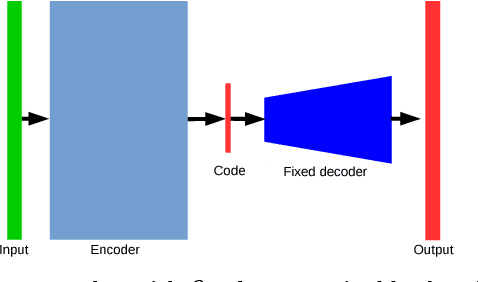
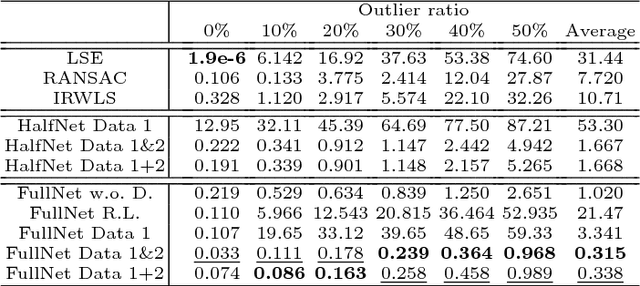
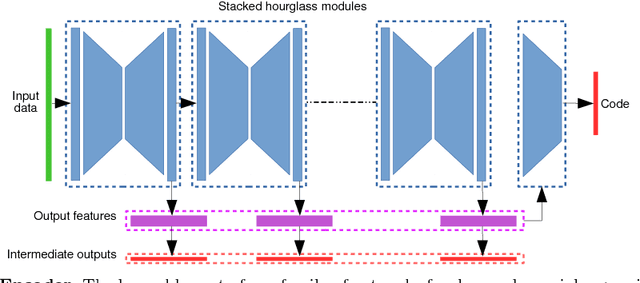
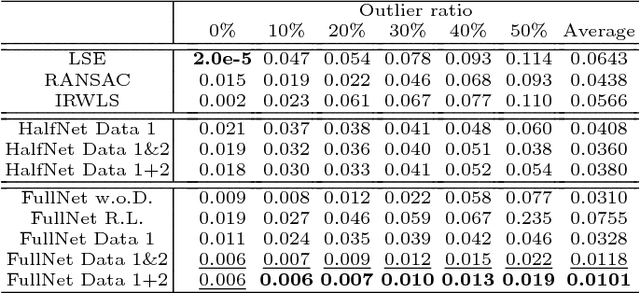
Polynomial regression is a recurrent problem with a large number of applications. In computer vision it often appears in motion analysis. Whatever the application, standard methods for regression of polynomial models tend to deliver biased results when the input data is heavily contaminated by outliers. Moreover, the problem is even harder when outliers have strong structure. Departing from problem-tailored heuristics for robust estimation of parametric models, we explore deep convolutional neural networks. Our work aims to find a generic approach for training deep regression models without the explicit need of supervised annotation. We bypass the need for a tailored loss function on the regression parameters by attaching to our model a differentiable hard-wired decoder corresponding to the polynomial operation at hand. We demonstrate the value of our findings by comparing with standard robust regression methods. Furthermore, we demonstrate how to use such models for a real computer vision problem, i.e., video stabilization. The qualitative and quantitative experiments show that neural networks are able to learn robustness for general polynomial regression, with results that well overpass scores of traditional robust estimation methods.