 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cross-institutional Evaluation on Breast Cancer Phenotyping NLP Algorithms on Electronic Health Records
Mar 15, 2023Objective: The generalizability of clinical large language models is usually ignored during the model development process. This study evaluated the generalizability of BERT-based clinical NLP models across different clinical settings through a breast cancer phenotype extraction task. Materials and Methods: Two clinical corpora of breast cancer patients were collected from the electronic health records from the University of Minnesota and the Mayo Clinic, and annotated following the same guideline. We developed three types of NLP models (i.e., conditional random field, bi-directional long short-term memory and CancerBERT) to extract cancer phenotypes from clinical texts. The models were evaluated for their generalizability on different test sets with different learning strategies (model transfer vs. locally trained). The entity coverage score was assessed with their association with the model performances. Results: We manually annotated 200 and 161 clinical documents at UMN and MC, respectively. The corpora of the two institutes were found to have higher similarity between the target entities than the overall corpora. The CancerBERT models obtained the best performances among the independent test sets from two clinical institutes and the permutation test set. The CancerBERT model developed in one institute and further fine-tuned in another institute achieved reasonable performance compared to the model developed on local data (micro-F1: 0.925 vs 0.932). Conclusions: The results indicate the CancerBERT model has the best learning ability and generalizability among the three types of clinical NLP models. The generalizability of the models was found to be correlated with the similarity of the target entities between the corpora.
Robust Autoencoders for Collective Corruption Removal
Mar 06, 2023


Robust PCA is a standard tool for learning a linear subspace in the presence of sparse corruption or rare outliers. What about robustly learning manifolds that are more realistic models for natural data, such as images? There have been several recent attempts to generalize robust PCA to manifold settings. In this paper, we propose $\ell_1$- and scaling-invariant $\ell_1/\ell_2$-robust autoencoders based on a surprisingly compact formulation built on the intuition that deep autoencoders perform manifold learning. We demonstrate on several standard image datasets that the proposed formulation significantly outperforms all previous methods in collectively removing sparse corruption, without clean images for training. Moreover, we also show that the learned manifold structures can be generalized to unseen data samples effectively.
Welfare and Fairness Dynamics in Federated Learning: A Client Selection Perspective
Feb 17, 2023



Federated learning (FL) is a privacy-preserving learning technique that enables distributed computing devices to train shared learning models across data silos collaboratively. Existing FL works mostly focus on designing advanced FL algorithms to improve the model performance. However, the economic considerations of the clients, such as fairness and incentive, are yet to be fully explored. Without such considerations, self-motivated clients may lose interest and leave the federation. To address this problem, we designed a novel incentive mechanism that involves a client selection process to remove low-quality clients and a money transfer process to ensure a fair reward distribution. Our experimental results strongly demonstrate that the proposed incentive mechanism can effectively improve the duration and fairness of the federation.
Interpretable Deep Learning Methods for Multiview Learning
Feb 15, 2023Technological advances have enabled the generation of unique and complementary types of data or views (e.g. genomics, proteomics, metabolomics) and opened up a new era in multiview learning research with the potential to lead to new biomedical discoveries. We propose iDeepViewLearn (Interpretable Deep Learning Method for Multiview Learning) for learning nonlinear relationships in data from multiple views while achieving feature selection. iDeepViewLearn combines deep learning flexibility with the statistical benefits of data and knowledge-driven feature selection, giving interpretable results. Deep neural networks are used to learn view-independent low-dimensional embedding through an optimization problem that minimizes the difference between observed and reconstructed data, while imposing a regularization penalty on the reconstructed data. The normalized Laplacian of a graph is used to model bilateral relationships between variables in each view, therefore, encouraging selection of related variables. iDeepViewLearn is tested on simulated and two real-world data, including breast cancer-related gene expression and methylation data. iDeepViewLearn had competitive classification results and identified genes and CpG sites that differentiated between individuals who died from breast cancer and those who did not. The results of our real data application and simulations with small to moderate sample sizes suggest that iDeepViewLearn may be a useful method for small-sample-size problems compared to other deep learning methods for multiview learning.
Practical Phase Retrieval Using Double Deep Image Priors
Nov 02, 2022Phase retrieval (PR) concerns the recovery of complex phases from complex magnitudes. We identify the connection between the difficulty level and the number and variety of symmetries in PR problems. We focus on the most difficult far-field PR (FFPR), and propose a novel method using double deep image priors. In realistic evaluation, our method outperforms all competing methods by large margins. As a single-instance method, our method requires no training data and minimal hyperparameter tuning, and hence enjoys good practicality.
NCVX: A General-Purpose Optimization Solver for Constrained Machine and Deep Learning
Oct 03, 2022Imposing explicit constraints is relatively new but increasingly pressing in deep learning, stimulated by, e.g., trustworthy AI that performs robust optimization over complicated perturbation sets and scientific applications that need to respect physical laws and constraints. However, it can be hard to reliably solve constrained deep learning problems without optimization expertise. The existing deep learning frameworks do not admit constraints. General-purpose optimization packages can handle constraints but do not perform auto-differentiation and have trouble dealing with nonsmoothness. In this paper, we introduce a new software package called NCVX, whose initial release contains the solver PyGRANSO, a PyTorch-enabled general-purpose optimization package for constrained machine/deep learning problems, the first of its kind. NCVX inherits auto-differentiation, GPU acceleration, and tensor variables from PyTorch, and is built on freely available and widely used open-source frameworks. NCVX is available at https://ncvx.org, with detailed documentation and numerous examples from machine/deep learning and other fields.
Optimization for Robustness Evaluation beyond $\ell_p$ Metrics
Oct 02, 2022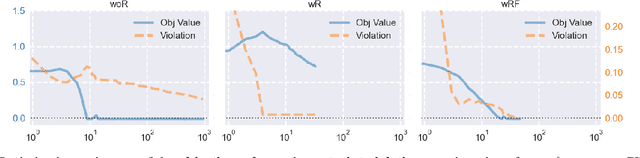
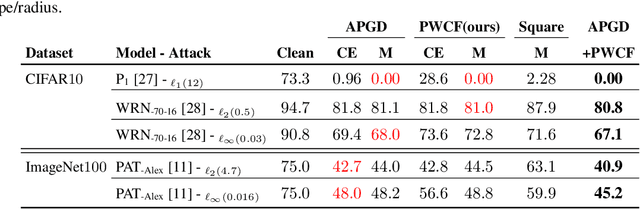
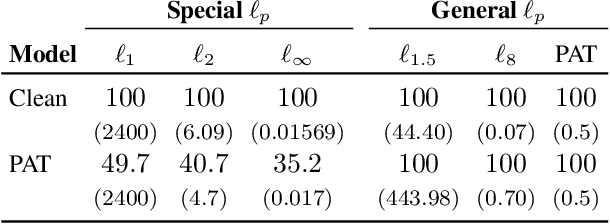
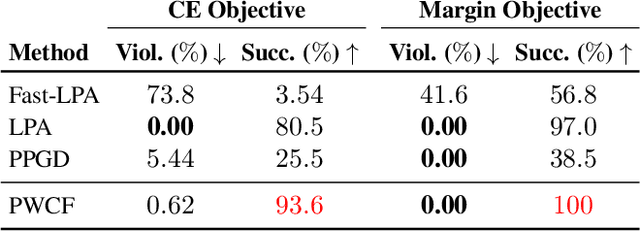
Empirical evaluation of deep learning models against adversarial attacks entails solving nontrivial constrained optimization problems. Popular algorithms for solving these constrained problems rely on projected gradient descent (PGD) and require careful tuning of multiple hyperparameters. Moreover, PGD can only handle $\ell_1$, $\ell_2$, and $\ell_\infty$ attack models due to the use of analytical projectors. In this paper, we introduce a novel algorithmic framework that blends a general-purpose constrained-optimization solver PyGRANSO, With Constraint-Folding (PWCF), to add reliability and generality to robustness evaluation. PWCF 1) finds good-quality solutions without the need of delicate hyperparameter tuning, and 2) can handle general attack models, e.g., general $\ell_p$ ($p \geq 0$) and perceptual attacks, which are inaccessible to PGD-based algorithms.
Blind Image Deblurring with Unknown Kernel Size and Substantial Noise
Aug 18, 2022

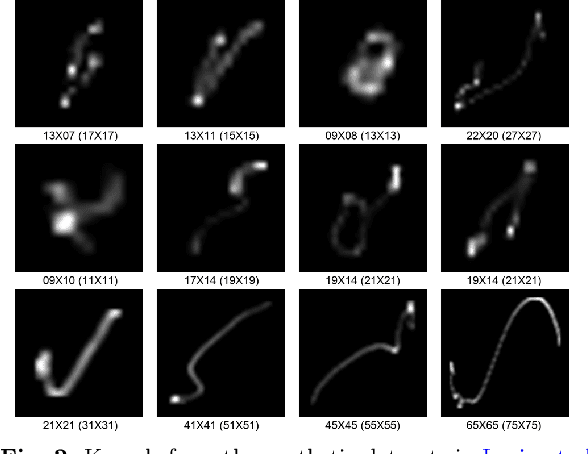

Blind image deblurring (BID) has been extensively studied in computer vision and adjacent fields. Modern methods for BID can be grouped into two categories: single-instance methods that deal with individual instances using statistical inference and numerical optimization, and data-driven methods that train deep-learning models to deblur future instances directly. Data-driven methods can be free from the difficulty in deriving accurate blur models, but are fundamentally limited by the diversity and quality of the training data -- collecting sufficiently expressive and realistic training data is a standing challenge. In this paper, we focus on single-instance methods that remain competitive and indispensable. However, most such methods do not prescribe how to deal with unknown kernel size and substantial noise, precluding practical deployment. Indeed, we show that several state-of-the-art (SOTA) single-instance methods are unstable when the kernel size is overspecified, and/or the noise level is high. On the positive side, we propose a practical BID method that is stable against both, the first of its kind. Our method builds on the recent ideas of solving inverse problems by integrating the physical models and structured deep neural networks, without extra training data. We introduce several crucial modifications to achieve the desired stability. Extensive empirical tests on standard synthetic datasets, as well as real-world NTIRE2020 and RealBlur datasets, show the superior effectiveness and practicality of our BID method compared to SOTA single-instance as well as data-driven methods. The code of our method is available at: \url{https://github.com/sun-umn/Blind-Image-Deblurring}.
Early Stopping for Deep Image Prior
Dec 11, 2021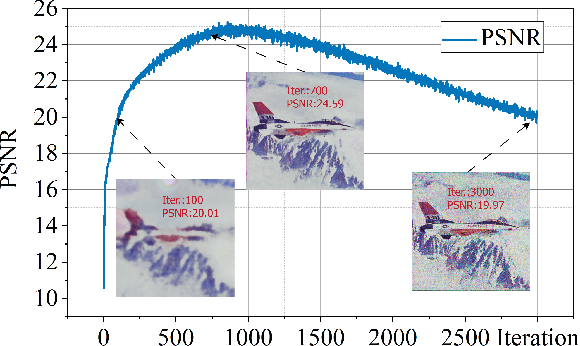

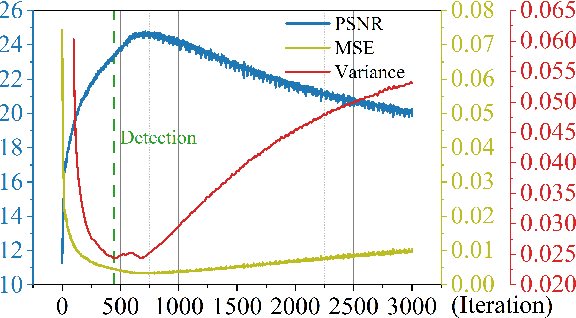
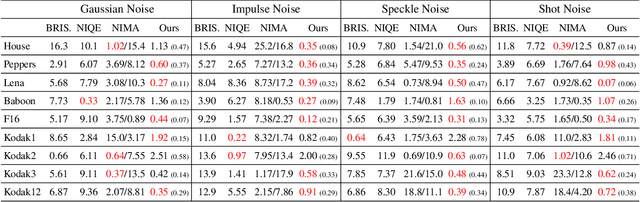
Deep image prior (DIP) and its variants have showed remarkable potential for solving inverse problems in computer vision, without any extra training data. Practical DIP models are often substantially overparameterized. During the fitting process, these models learn mostly the desired visual content first, and then pick up the potential modeling and observational noise, i.e., overfitting. Thus, the practicality of DIP often depends critically on good early stopping (ES) that captures the transition period. In this regard, the majority of DIP works for vision tasks only demonstrates the potential of the models -- reporting the peak performance against the ground truth, but provides no clue about how to operationally obtain near-peak performance without access to the groundtruth. In this paper, we set to break this practicality barrier of DIP, and propose an efficient ES strategy, which consistently detects near-peak performance across several vision tasks and DIP variants. Based on a simple measure of dispersion of consecutive DIP reconstructions, our ES method not only outpaces the existing ones -- which only work in very narrow domains, but also remains effective when combined with a number of methods that try to mitigate the overfitting. The code is available at https://github.com/sun-umn/Early_Stopping_for_DIP.
NCVX: A User-Friendly and Scalable Package for Nonconvex Optimization in Machine Learning
Nov 27, 2021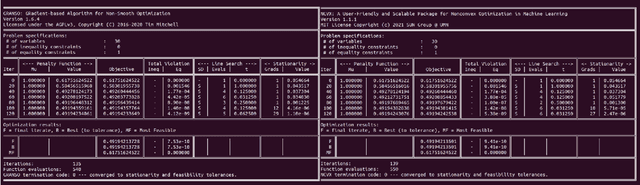
Optimizing nonconvex (NCVX) problems, especially those nonsmooth (NSMT) and constrained (CSTR), is an essential part of machine learning and deep learning. But it is hard to reliably solve this type of problems without optimization expertise. Existing general-purpose NCVX optimization packages are powerful, but typically cannot handle nonsmoothness. GRANSO is among the first packages targeting NCVX, NSMT, CSTR problems. However, it has several limitations such as the lack of auto-differentiation and GPU acceleration, which preclude the potential broad deployment by non-experts. To lower the technical barrier for the machine learning community, we revamp GRANSO into a user-friendly and scalable python package named NCVX, featuring auto-differentiation, GPU acceleration, tensor input, scalable QP solver, and zero dependency on proprietary packages. As a highlight, NCVX can solve general CSTR deep learning problems, the first of its kind. NCVX is available at https://ncvx.org, with detailed documentation and numerous examples from machine learning and other fields.