 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Lateral Views Help Automated Chest X-ray Predictions?
Apr 17, 2019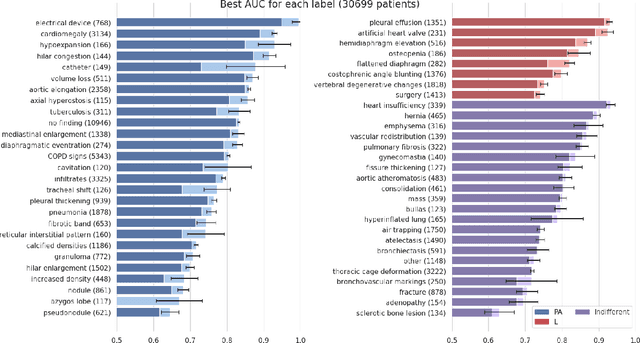
Most convolutional neural networks in chest radiology use only the frontal posteroanterior (PA) view to make a prediction. However the lateral view is known to help the diagnosis of certain diseases and conditions. The recently released PadChest dataset contains paired PA and lateral views, allowing us to study for which diseases and conditions the performance of a neural network improves when provided a lateral x-ray view as opposed to a frontal posteroanterior (PA) view. Using a simple DenseNet model, we find that using the lateral view increases the AUC of 8 of the 56 labels in our data and achieves the same performance as the PA view for 21 of the labels. We find that using the PA and lateral views jointly doesn't trivially lead to an increase in performance but suggest further investigation.
GradMask: Reduce Overfitting by Regularizing Saliency
Apr 16, 2019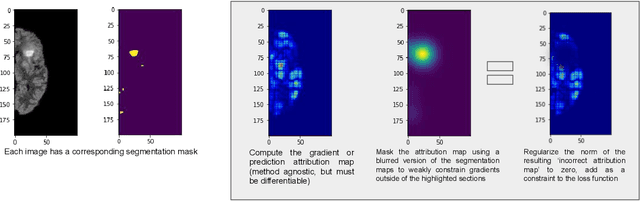
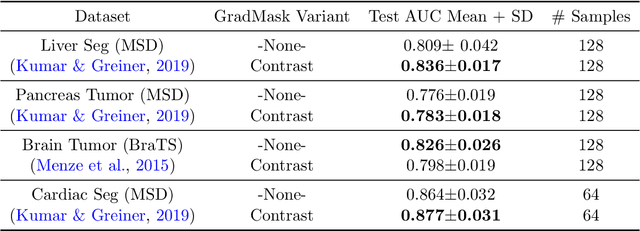
With too few samples or too many model parameters, overfitting can inhibit the ability to generalise predictions to new data. Within medical imaging, this can occur when features are incorrectly assigned importance such as distinct hospital specific artifacts, leading to poor performance on a new dataset from a different institution without those features, which is undesirable. Most regularization methods do not explicitly penalize the incorrect association of these features to the target class and hence fail to address this issue. We propose a regularization method, GradMask, which penalizes saliency maps inferred from the classifier gradients when they are not consistent with the lesion segmentation. This prevents non-tumor related features to contribute to the classification of unhealthy samples. We demonstrate that this method can improve test accuracy between 1-3% compared to the baseline without GradMask, showing that it has an impact on reducing overfitting.
Chester: A Web Delivered Locally Computed Chest X-Ray Disease Prediction System
Jan 31, 2019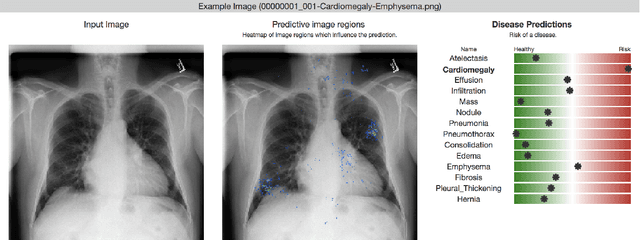
Deep learning has shown promise to augment radiologists and improve the standard of care globally. Two main issues that complicate deploying these systems are patient privacy and scaling to the global population. To deploy a system at scale with minimal computational cost while preserving privacy we present a web delivered (but locally run) system for diagnosing chest X-Rays. Code is delivered via a URL to a web browser (including cell phones) but the patient data remains on the users machine and all processing occurs locally. The system is designed to be used as a reference where a user can process an image to confirm or aid in their diagnosis. The system contains three main components: out-of-distribution detection, disease prediction, and prediction explanation. The system open source and freely available here: https://mlmed.org/tools/xray/
A Survey of Mobile Computing for the Visually Impaired
Nov 27, 2018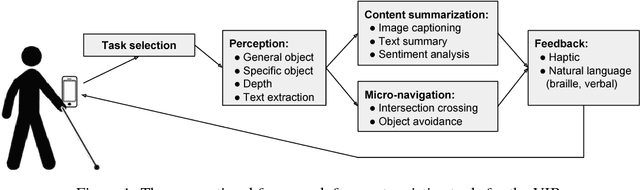
The number of visually impaired or blind (VIB) people in the world is estimated at several hundred million. Based on a series of interviews with the VIB and developers of assistive technology, this paper provides a survey of machine-learning based mobile applications and identifies the most relevant applications. We discuss the functionality of these apps, how they align with the needs and requirements of the VIB users, and how they can be improved with techniques such as federated learning and model compression. As a result of this study we identify promising future directions of research in mobile perception, micro-navigation, and content-summarization.
Towards the Latent Transcriptome
Oct 08, 2018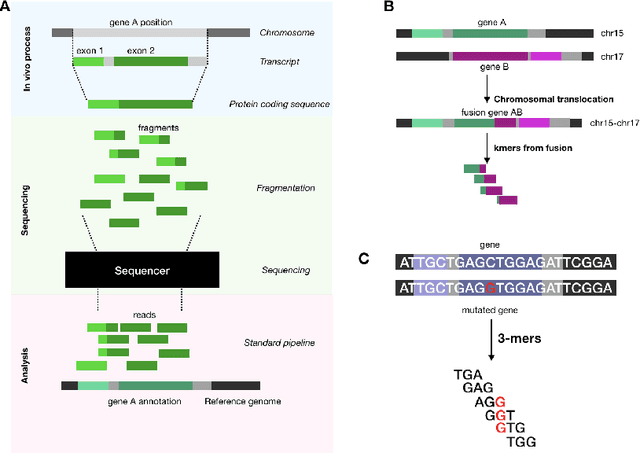

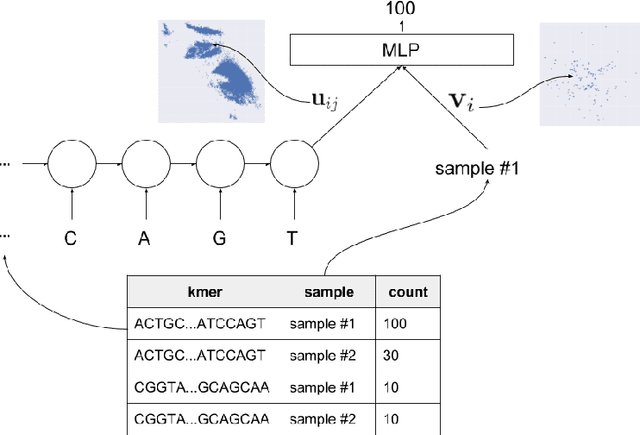
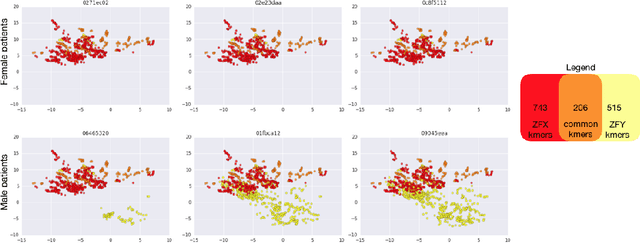
In this work we propose a method to compute continuous embeddings for kmers from raw RNA-seq data, in a reference-free fashion. We report that our model captures information of both DNA sequence similarity as well as DNA sequence abundance in the embedding latent space. We confirm the quality of these vectors by comparing them to known gene sub-structures and report that the latent space recovers exon information from raw RNA-Seq data from acute myeloid leukemia patients. Furthermore we show that this latent space allows the detection of genomic abnormalities such as translocations as well as patient-specific mutations, making this representation space both useful for visualization as well as analysis.
Distribution Matching Losses Can Hallucinate Features in Medical Image Translation
Oct 03, 2018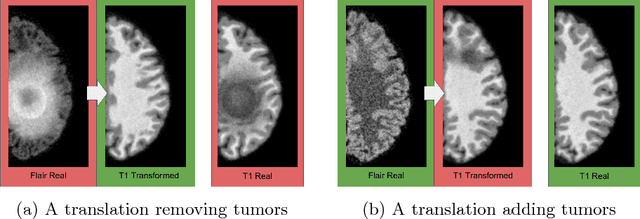
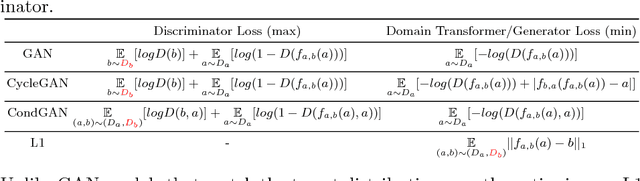
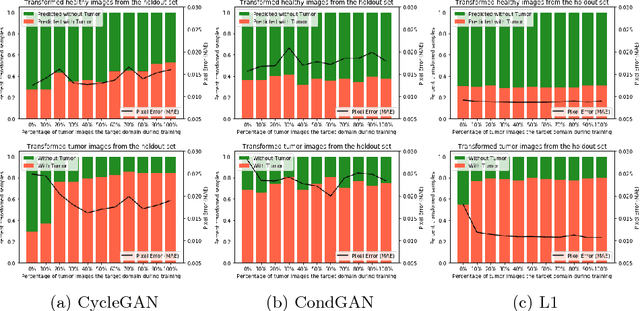

This paper discusses how distribution matching losses, such as those used in CycleGAN, when used to synthesize medical images can lead to mis-diagnosis of medical conditions. It seems appealing to use these new image synthesis methods for translating images from a source to a target domain because they can produce high quality images and some even do not require paired data. However, the basis of how these image translation models work is through matching the translation output to the distribution of the target domain. This can cause an issue when the data provided in the target domain has an over or under representation of some classes (e.g. healthy or sick). When the output of an algorithm is a transformed image there are uncertainties whether all known and unknown class labels have been preserved or changed. Therefore, we recommend that these translated images should not be used for direct interpretation (e.g. by doctors) because they may lead to misdiagnosis of patients based on hallucinated image features by an algorithm that matches a distribution. However there are many recent papers that seem as though this is the goal.
* Published at Medical Image Computing & Computer Assisted Intervention (MICCAI 2018). An abstract is published at the Medical Imaging with Deep Learning Conference (MIDL 2018) as "How to Cure Cancer (in images) with Unpaired Image Translation"
Towards Gene Expression Convolutions using Gene Interaction Graphs
Jun 18, 2018
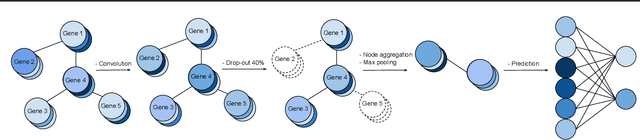
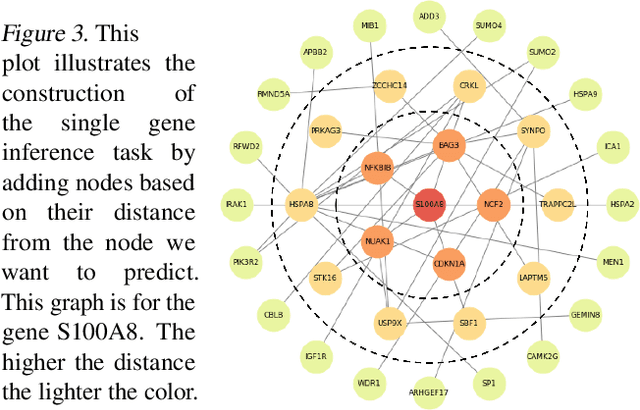
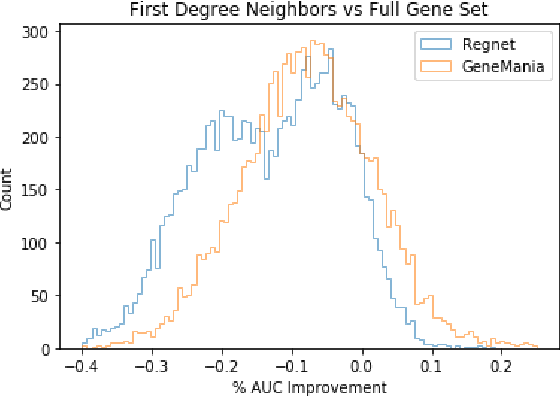
We study the challenges of applying deep learning to gene expression data. We find experimentally that there exists non-linear signal in the data, however is it not discovered automatically given the noise and low numbers of samples used in most research. We discuss how gene interaction graphs (same pathway, protein-protein, co-expression, or research paper text association) can be used to impose a bias on a deep model similar to the spatial bias imposed by convolutions on an image. We explore the usage of Graph Convolutional Neural Networks coupled with dropout and gene embeddings to utilize the graph information. We find this approach provides an advantage for particular tasks in a low data regime but is very dependent on the quality of the graph used. We conclude that more work should be done in this direction. We design experiments that show why existing methods fail to capture signal that is present in the data when features are added which clearly isolates the problem that needs to be addressed.
Learning to rank for censored survival data
Jun 08, 2018
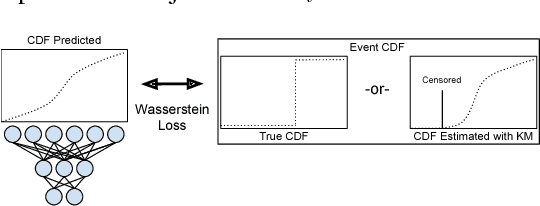
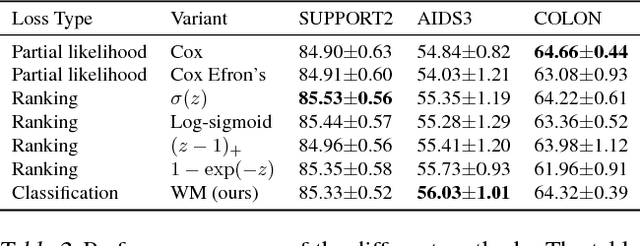
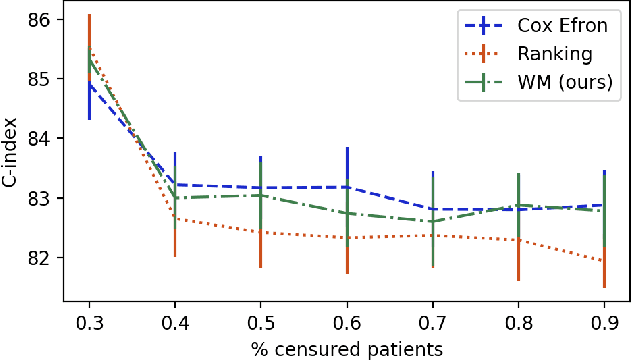
Survival analysis is a type of semi-supervised ranking task where the target output (the survival time) is often right-censored. Utilizing this information is a challenge because it is not obvious how to correctly incorporate these censored examples into a model. We study how three categories of loss functions, namely partial likelihood methods, rank methods, and our classification method based on a Wasserstein metric (WM) and the non-parametric Kaplan Meier estimate of the probability density to impute the labels of censored examples, can take advantage of this information. The proposed method allows us to have a model that predict the probability distribution of an event. If a clinician had access to the detailed probability of an event over time this would help in treatment planning. For example, determining if the risk of kidney graft rejection is constant or peaked after some time. Also, we demonstrate that this approach directly optimizes the expected C-index which is the most common evaluation metric for ranking survival models.
GibbsNet: Iterative Adversarial Inference for Deep Graphical Models
Dec 12, 2017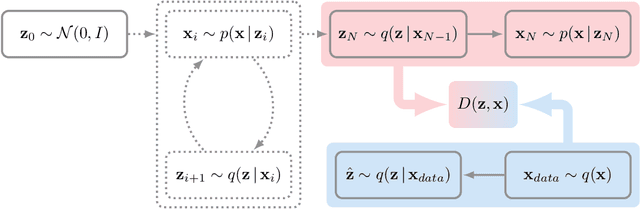

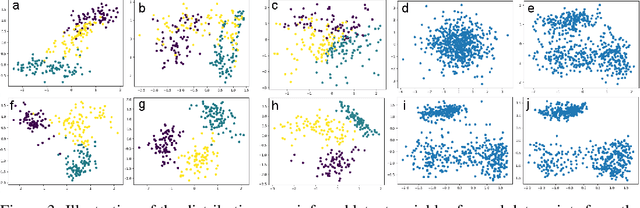
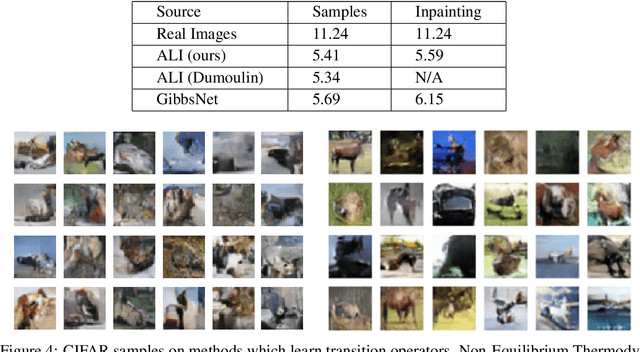
Directed latent variable models that formulate the joint distribution as $p(x,z) = p(z) p(x \mid z)$ have the advantage of fast and exact sampling. However, these models have the weakness of needing to specify $p(z)$, often with a simple fixed prior that limits the expressiveness of the model. Undirected latent variable models discard the requirement that $p(z)$ be specified with a prior, yet sampling from them generally requires an iterative procedure such as blocked Gibbs-sampling that may require many steps to draw samples from the joint distribution $p(x, z)$. We propose a novel approach to learning the joint distribution between the data and a latent code which uses an adversarially learned iterative procedure to gradually refine the joint distribution, $p(x, z)$, to better match with the data distribution on each step. GibbsNet is the best of both worlds both in theory and in practice. Achieving the speed and simplicity of a directed latent variable model, it is guaranteed (assuming the adversarial game reaches the virtual training criteria global minimum) to produce samples from $p(x, z)$ with only a few sampling iterations. Achieving the expressiveness and flexibility of an undirected latent variable model, GibbsNet does away with the need for an explicit $p(z)$ and has the ability to do attribute prediction, class-conditional generation, and joint image-attribute modeling in a single model which is not trained for any of these specific tasks. We show empirically that GibbsNet is able to learn a more complex $p(z)$ and show that this leads to improved inpainting and iterative refinement of $p(x, z)$ for dozens of steps and stable generation without collapse for thousands of steps, despite being trained on only a few steps.
Count-ception: Counting by Fully Convolutional Redundant Counting
Jul 23, 2017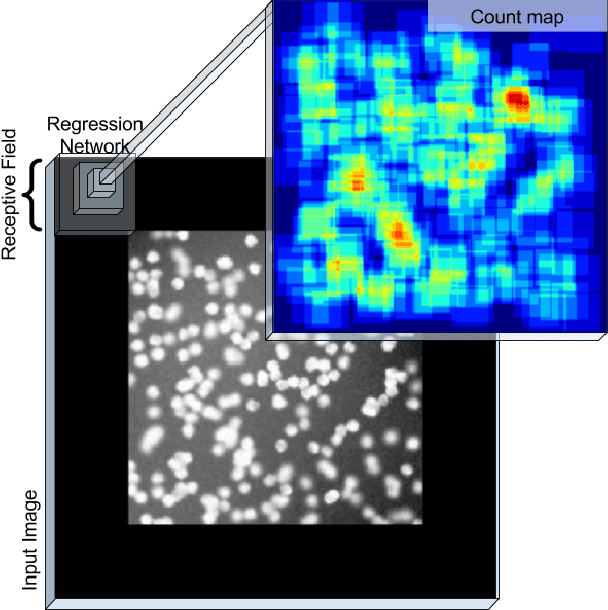
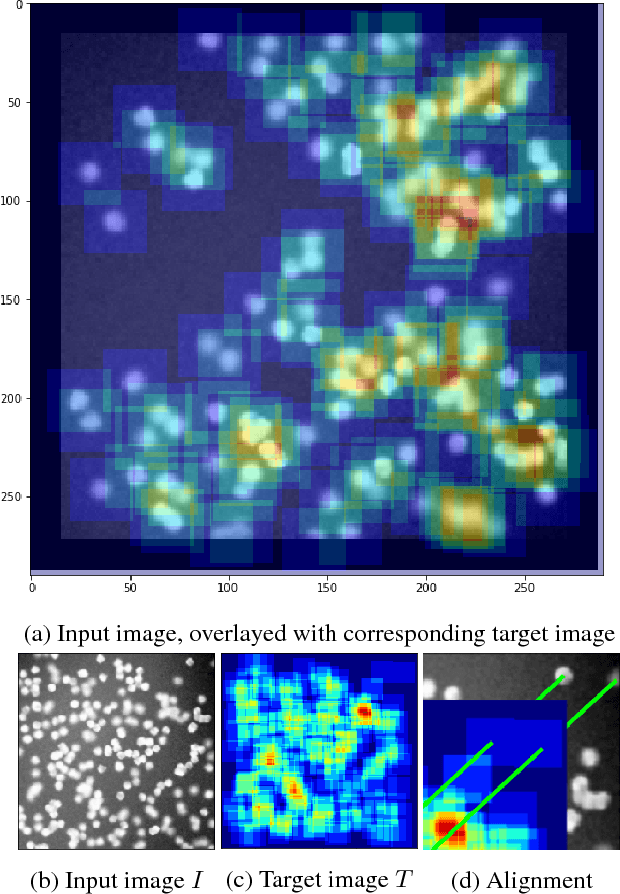
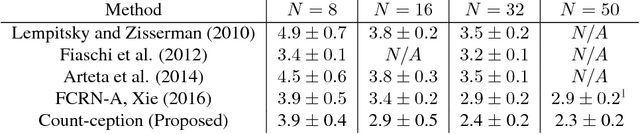
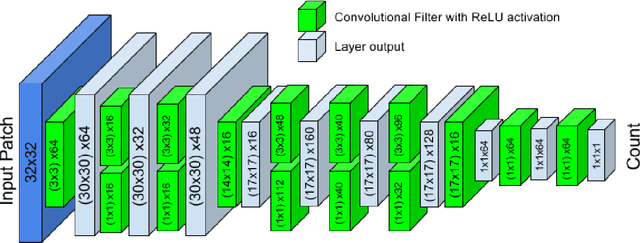
Counting objects in digital images is a process that should be replaced by machines. This tedious task is time consuming and prone to errors due to fatigue of human annotators. The goal is to have a system that takes as input an image and returns a count of the objects inside and justification for the prediction in the form of object localization. We repose a problem, originally posed by Lempitsky and Zisserman, to instead predict a count map which contains redundant counts based on the receptive field of a smaller regression network. The regression network predicts a count of the objects that exist inside this frame. By processing the image in a fully convolutional way each pixel is going to be accounted for some number of times, the number of windows which include it, which is the size of each window, (i.e., 32x32 = 1024). To recover the true count we take the average over the redundant predictions. Our contribution is redundant counting instead of predicting a density map in order to average over errors. We also propose a novel deep neural network architecture adapted from the Inception family of networks called the Count-ception network. Together our approach results in a 20% relative improvement (2.9 to 2.3 MAE) over the state of the art method by Xie, Noble, and Zisserman in 2016.