 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffine Non-negative Collaborative Representation Based Pattern Classification
Jul 10, 2020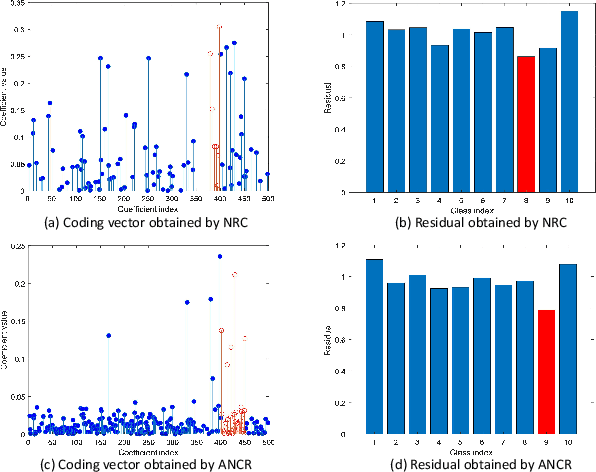



During the past decade, representation-based classification methods have received considerable attention in pattern recognition. In particular, the recently proposed non-negative representation based classification (NRC) method has been reported to achieve promising results in a wide range of classification tasks. However, NRC has two major drawbacks. First, there is no regularization term in the formulation of NRC, which may result in unstable solution and misclassification. Second, NRC ignores the fact that data usually lies in a union of multiple affine subspaces, rather than linear subspaces in practical applications. To address the above issues, this paper presents an affine non-negative collaborative representation (ANCR) model for pattern classification. To be more specific, ANCR imposes a regularization term on the coding vector. Moreover, ANCR introduces an affine constraint to better represent the data from affine subspaces. The experimental results on several benchmarking datasets demonstrate the merits of the proposed ANCR method. The source code of our ANCR is publicly available at https://github.com/yinhefeng/ANCR.
AFAT: Adaptive Failure-Aware Tracker for Robust Visual Object Tracking
May 27, 2020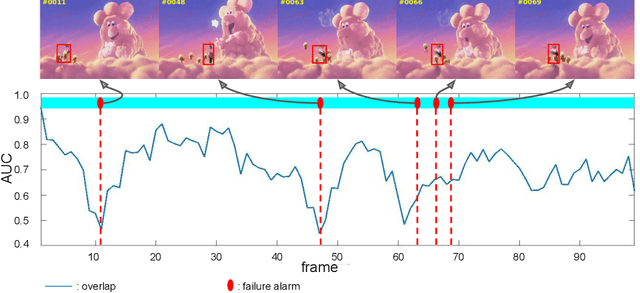
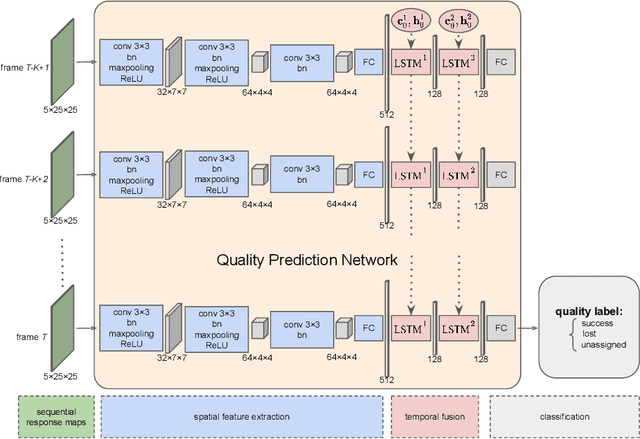
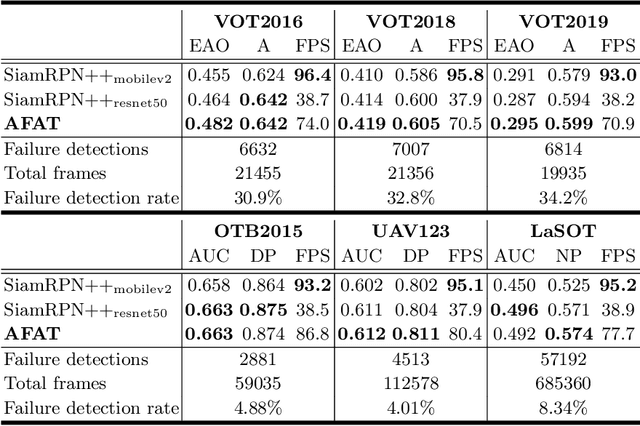
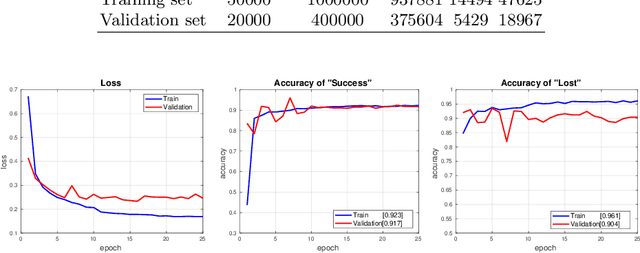
Siamese approaches have achieved promising performance in visual object tracking recently. The key to the success of Siamese trackers is to learn appearance-invariant feature embedding functions via pair-wise offline training on large-scale video datasets. However, the Siamese paradigm uses one-shot learning to model the online tracking task, which impedes online adaptation in the tracking process. Additionally, the uncertainty of an online tracking response is not measured, leading to the problem of ignoring potential failures. In this paper, we advocate online adaptation in the tracking stage. To this end, we propose a failure-aware system, realised by a Quality Prediction Network (QPN), based on convolutional and LSTM modules in the decision stage, enabling online reporting of potential tracking failures. Specifically, sequential response maps from previous successive frames as well as current frame are collected to predict the tracking confidence, realising spatio-temporal fusion in the decision level. In addition, we further provide an Adaptive Failure-Aware Tracker (AFAT) by combing the state-of-the-art Siamese trackers with our system. The experimental results obtained on standard benchmarking datasets demonstrate the effectiveness of the proposed failure-aware system and the merits of our AFAT tracker, with outstanding and balanced performance in both accuracy and speed.
A Convolutional Baseline for Person Re-Identification Using Vision and Language Descriptions
Feb 20, 2020

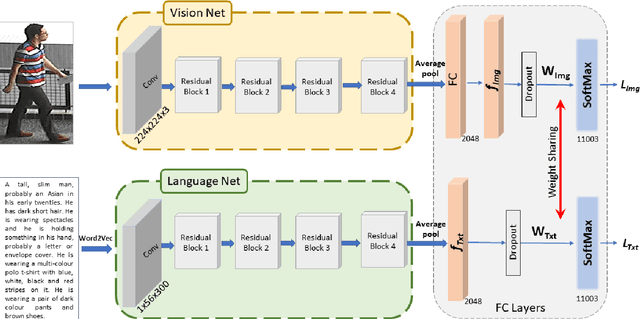

Classical person re-identification approaches assume that a person of interest has appeared across different cameras and can be queried by one of the existing images. However, in real-world surveillance scenarios, frequently no visual information will be available about the queried person. In such scenarios, a natural language description of the person by a witness will provide the only source of information for retrieval. In this work, person re-identification using both vision and language information is addressed under all possible gallery and query scenarios. A two stream deep convolutional neural network framework supervised by cross entropy loss is presented. The weights connecting the second last layer to the last layer with class probabilities, i.e., logits of softmax layer are shared in both networks. Canonical Correlation Analysis is performed to enhance the correlation between the two modalities in a joint latent embedding space. To investigate the benefits of the proposed approach, a new testing protocol under a multi modal ReID setting is proposed for the test split of the CUHK-PEDES and CUHK-SYSU benchmarks. The experimental results verify the merits of the proposed system. The learnt visual representations are more robust and perform 22\% better during retrieval as compared to a single modality system. The retrieval with a multi modal query greatly enhances the re-identification capability of the system quantitatively as well as qualitatively.
Adaptive Distraction Context Aware Tracking Based on Correlation Filter
Dec 24, 2019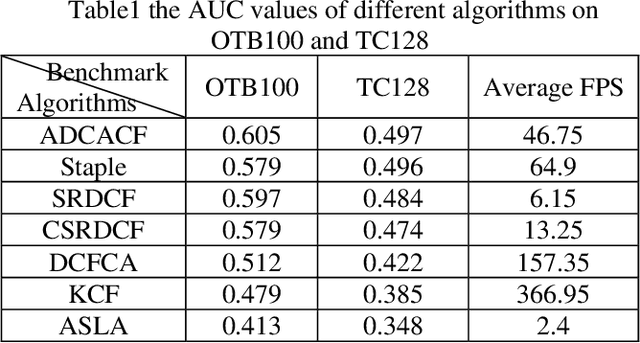
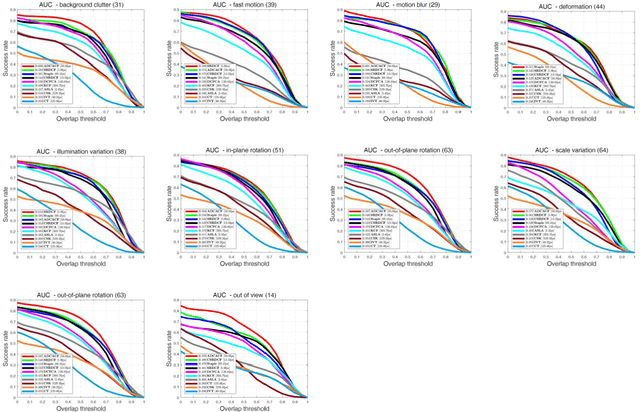

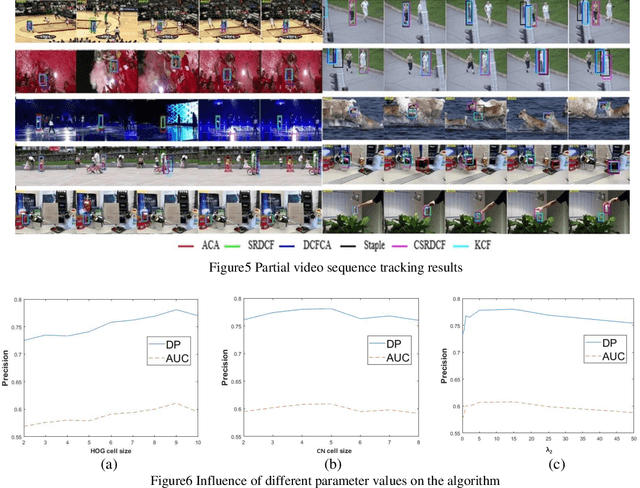
The Discriminative Correlation Filter (CF) uses a circulant convolution operation to provide several training samples for the design of a classifier that can distinguish the target from the background. The filter design may be interfered by objects close to the target during the tracking process, resulting in tracking failure. This paper proposes an adaptive distraction context aware tracking algorithm to solve this problem. In the response map obtained for the previous frame by the CF algorithm, we adaptively find the image blocks that are similar to the target and use them as negative samples. This diminishes the influence of similar image blocks on the classifier in the tracking process and its accuracy is improved. The tracking results on video sequences show that the algorithm can cope with rapid changes such as occlusion and rotation, and can adaptively use the distractive objects around the target as negative samples to improve the accuracy of target tracking.
Face Recognition via Locality Constrained Low Rank Representation and Dictionary Learning
Dec 06, 2019

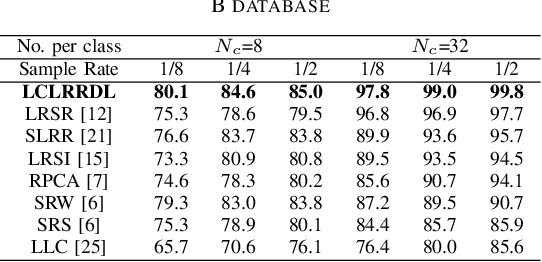
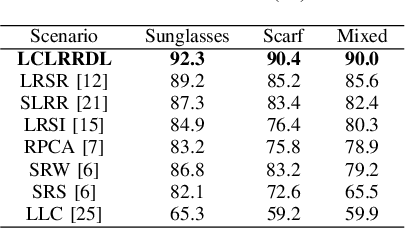
Face recognition has been widely studied due to its importance in smart cities applications. However, the case when both training and test images are corrupted is not well solved. To address such a problem, this paper proposes a locality constrained low rank representation and dictionary learning (LCLRRDL) algorithm for robust face recognition. In particular, we present three contributions in the proposed formulation. First, a low-rank representation is introduced to handle the possible contamination of the training as well as test data. Second, a locality constraint is incorporated to acknowledge the intrinsic manifold structure of training data. With the locality constraint term, our scheme induces similar samples to have similar representations. Third, a compact dictionary is learned to handle the problem of corrupted data. The experimental results on two public databases demonstrate the effectiveness of the proposed approach. Matlab code of our proposed LCLRRDL can be downloaded from https://github.com/yinhefeng/LCLRRDL.
An Accelerated Correlation Filter Tracker
Dec 05, 2019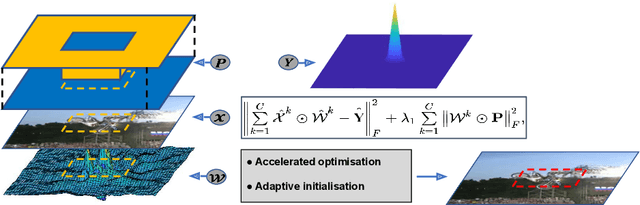
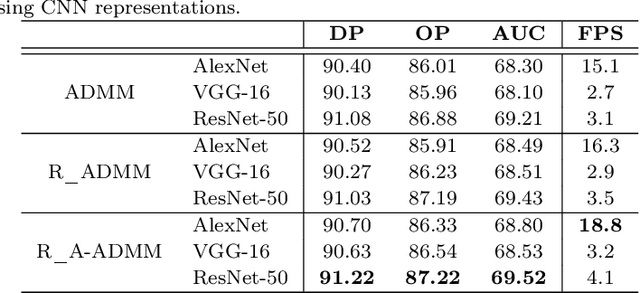
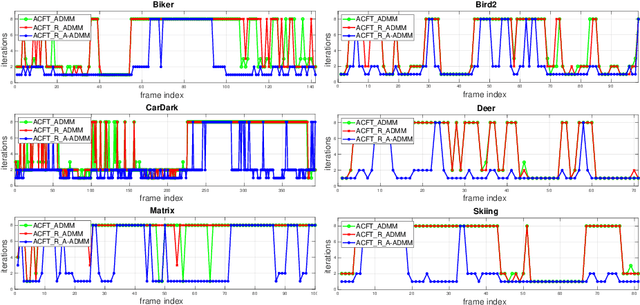
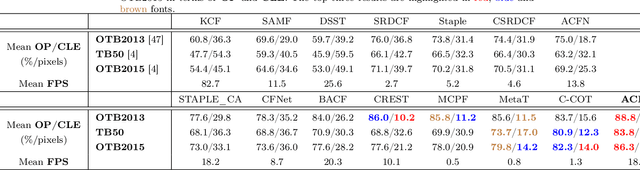
Recent visual object tracking methods have witnessed a continuous improvement in the state-of-the-art with the development of efficient discriminative correlation filters (DCF) and robust deep neural network features. Despite the outstanding performance achieved by the above combination, existing advanced trackers suffer from the burden of high computational complexity of the deep feature extraction and online model learning. We propose an accelerated ADMM optimisation method obtained by adding a momentum to the optimisation sequence iterates, and by relaxing the impact of the error between DCF parameters and their norm. The proposed optimisation method is applied to an innovative formulation of the DCF design, which seeks the most discriminative spatially regularised feature channels. A further speed up is achieved by an adaptive initialisation of the filter optimisation process. The significantly increased convergence of the DCF filter is demonstrated by establishing the optimisation process equivalence with a continuous dynamical system for which the convergence properties can readily be derived. The experimental results obtained on several well-known benchmarking datasets demonstrate the efficiency and robustness of the proposed ACFT method, with a tracking accuracy comparable to the start-of-the-art trackers.
Learning a Representation with the Block-Diagonal Structure for Pattern Classification
Nov 23, 2019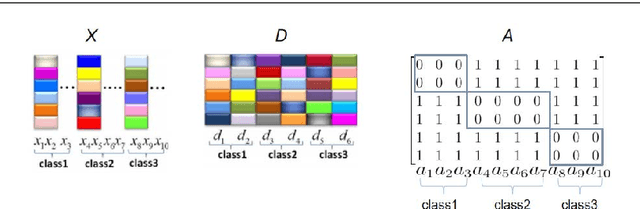
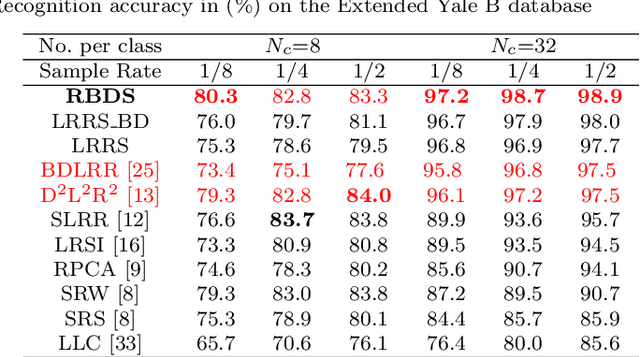

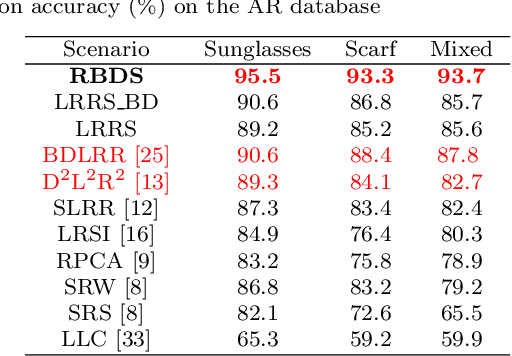
Sparse-representation-based classification (SRC) has been widely studied and developed for various practical signal classification applications. However, the performance of a SRC-based method is degraded when both the training and test data are corrupted. To counteract this problem, we propose an approach that learns Representation with Block-Diagonal Structure (RBDS) for robust image recognition. To be more specific, we first introduce a regularization term that captures the block-diagonal structure of the target representation matrix of the training data. The resulting problem is then solved by an optimizer. Last, based on the learned representation, a simple yet effective linear classifier is used for the classification task. The experimental results obtained on several benchmarking datasets demonstrate the efficacy of the proposed RBDS method.
More About Covariance Descriptors for Image Set Coding: Log-Euclidean Framework based Kernel Matrix Representation
Sep 26, 2019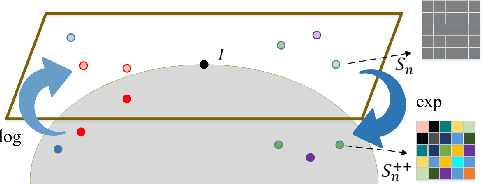
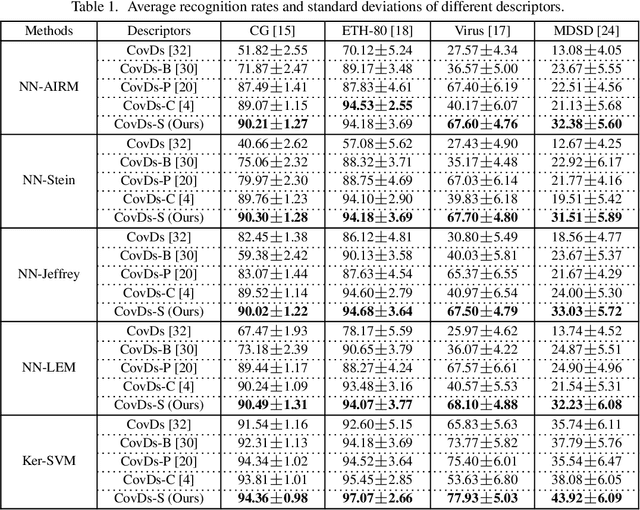
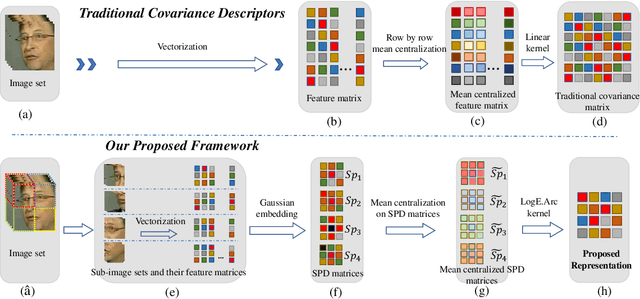
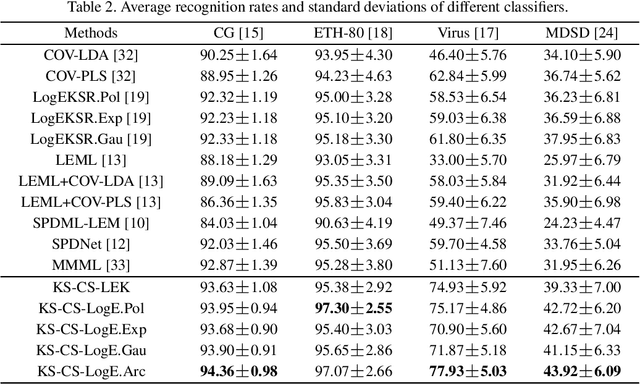
We consider a family of structural descriptors for visual data, namely covariance descriptors (CovDs) that lie on a non-linear symmetric positive definite (SPD) manifold, a special type of Riemannian manifolds. We propose an improved version of CovDs for image set coding by extending the traditional CovDs from Euclidean space to the SPD manifold. Specifically, the manifold of SPD matrices is a complete inner product space with the operations of logarithmic multiplication and scalar logarithmic multiplication defined in the Log-Euclidean framework. In this framework, we characterise covariance structure in terms of the arc-cosine kernel which satisfies Mercer's condition and propose the operation of mean centralization on SPD matrices. Furthermore, we combine arc-cosine kernels of different orders using mixing parameters learnt by kernel alignment in a supervised manner. Our proposed framework provides a lower-dimensional and more discriminative data representation for the task of image set classification. The experimental results demonstrate its superior performance, measured in terms of recognition accuracy, as compared with the state-of-the-art methods.
Dual Encoder-Decoder based Generative Adversarial Networks for Disentangled Facial Representation Learning
Sep 19, 2019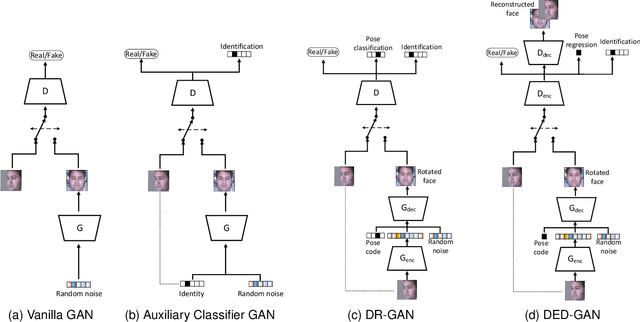
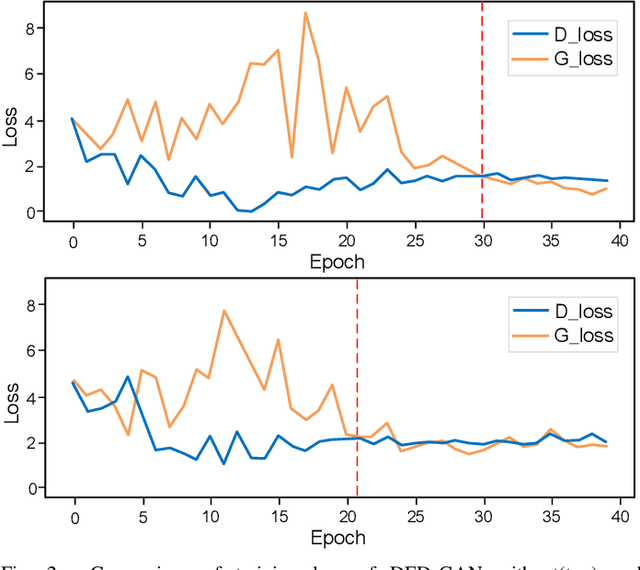
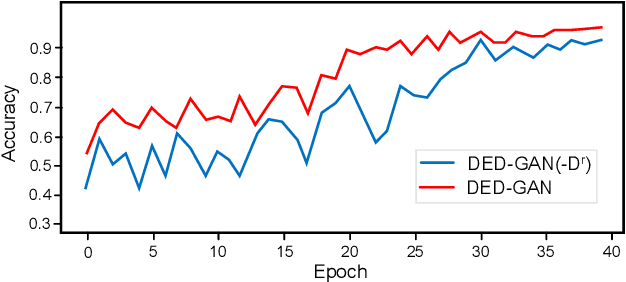
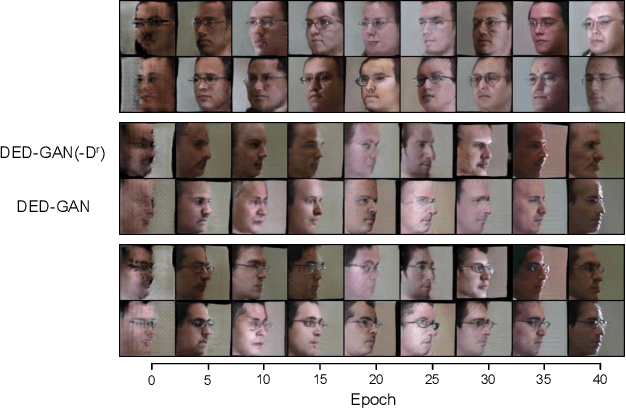
To learn disentangled representations of facial images, we present a Dual Encoder-Decoder based Generative Adversarial Network (DED-GAN). In the proposed method, both the generator and discriminator are designed with deep encoder-decoder architectures as their backbones. To be more specific, the encoder-decoder structured generator is used to learn a pose disentangled face representation, and the encoder-decoder structured discriminator is tasked to perform real/fake classification, face reconstruction, determining identity and estimating face pose. We further improve the proposed network architecture by minimising the additional pixel-wise loss defined by the Wasserstein distance at the output of the discriminator so that the adversarial framework can be better trained. Additionally, we consider face pose variation to be continuous, rather than discrete in existing literature, to inject richer pose information into our model. The pose estimation task is formulated as a regression problem, which helps to disentangle identity information from pose variations. The proposed network is evaluated on the tasks of pose-invariant face recognition (PIFR) and face synthesis across poses. An extensive quantitative and qualitative evaluation carried out on several controlled and in-the-wild benchmarking datasets demonstrates the superiority of the proposed DED-GAN method over the state-of-the-art approaches.
Multiple Riemannian Manifold-valued Descriptors based Image Set Classification with Multi-Kernel Metric Learning
Aug 06, 2019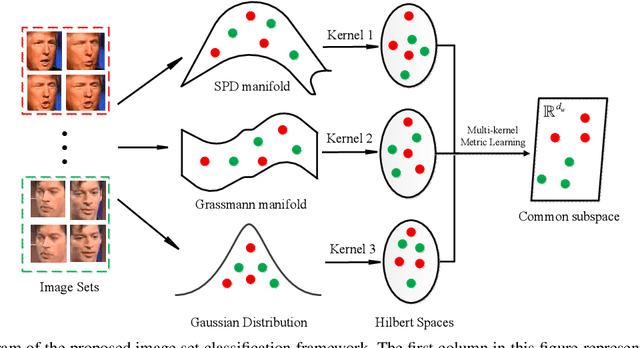



The importance of wild video based image set recognition is becoming monotonically increasing. However, the contents of these collected videos are often complicated, and how to efficiently perform set modeling and feature extraction is a big challenge for set-based classification algorithms. In recent years, some proposed image set classification methods have made a considerable advance by modeling the original image set with covariance matrix, linear subspace, or Gaussian distribution. As a matter of fact, most of them just adopt a single geometric model to describe each given image set, which may lose some other useful information for classification. To tackle this problem, we propose a novel algorithm to model each image set from a multi-geometric perspective. Specifically, the covariance matrix, linear subspace, and Gaussian distribution are applied for set representation simultaneously. In order to fuse these multiple heterogeneous Riemannian manifoldvalued features, the well-equipped Riemannian kernel functions are first utilized to map them into high dimensional Hilbert spaces. Then, a multi-kernel metric learning framework is devised to embed the learned hybrid kernels into a lower dimensional common subspace for classification. We conduct experiments on four widely used datasets corresponding to four different classification tasks: video-based face recognition, set-based object categorization, video-based emotion recognition, and dynamic scene classification, to evaluate the classification performance of the proposed algorithm. Extensive experimental results justify its superiority over the state-of-the-art.