 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Information-Theoretic Approach for Automatically Determining the Number of States when Aggregating Markov Chains
Jul 05, 2021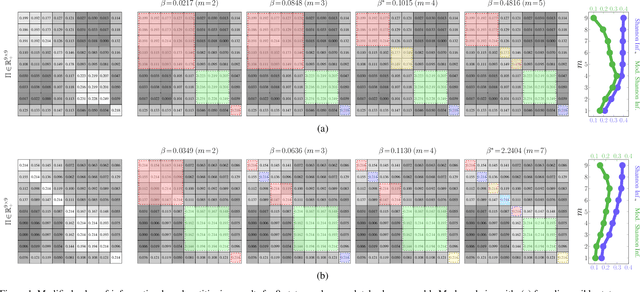
A fundamental problem when aggregating Markov chains is the specification of the number of state groups. Too few state groups may fail to sufficiently capture the pertinent dynamics of the original, high-order Markov chain. Too many state groups may lead to a non-parsimonious, reduced-order Markov chain whose complexity rivals that of the original. In this paper, we show that an augmented value-of-information-based approach to aggregating Markov chains facilitates the determination of the number of state groups. The optimal state-group count coincides with the case where the complexity of the reduced-order chain is balanced against the mutual dependence between the original- and reduced-order chain dynamics.
Labels, Information, and Computation: Efficient, Privacy-Preserving Learning Using Sufficient Labels
Apr 19, 2021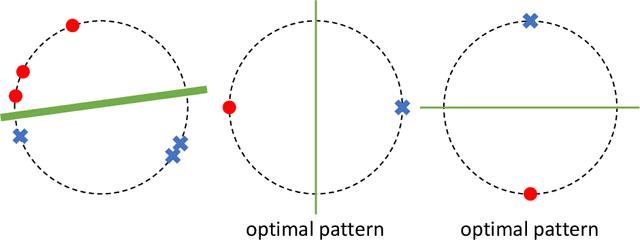
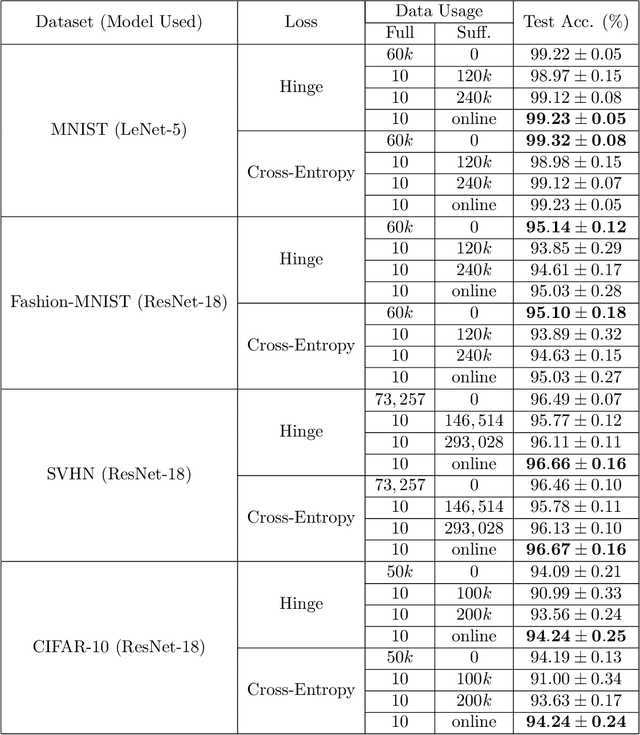
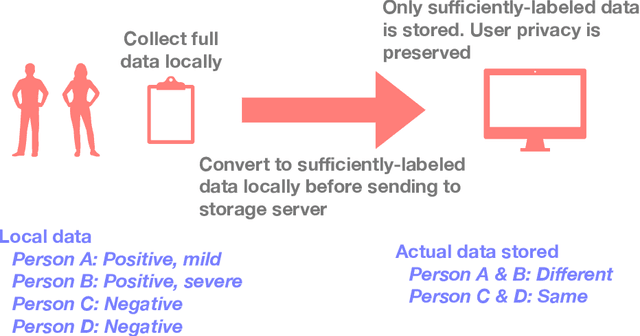
In supervised learning, obtaining a large set of fully-labeled training data is expensive. We show that we do not always need full label information on every single training example to train a competent classifier. Specifically, inspired by the principle of sufficiency in statistics, we present a statistic (a summary) of the fully-labeled training set that captures almost all the relevant information for classification but at the same time is easier to obtain directly. We call this statistic "sufficiently-labeled data" and prove its sufficiency and efficiency for finding the optimal hidden representations, on which competent classifier heads can be trained using as few as a single randomly-chosen fully-labeled example per class. Sufficiently-labeled data can be obtained from annotators directly without collecting the fully-labeled data first. And we prove that it is easier to directly obtain sufficiently-labeled data than obtaining fully-labeled data. Furthermore, sufficiently-labeled data naturally preserves user privacy by storing relative, instead of absolute, information. Extensive experimental results are provided to support our theory.
A Kernel Framework to Quantify a Model's Local Predictive Uncertainty under Data Distributional Shifts
Mar 02, 2021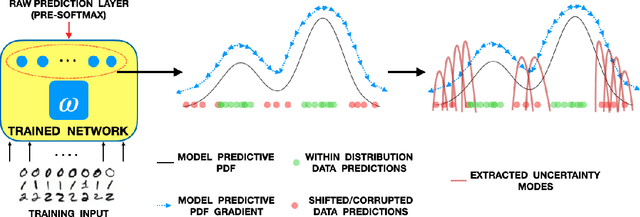
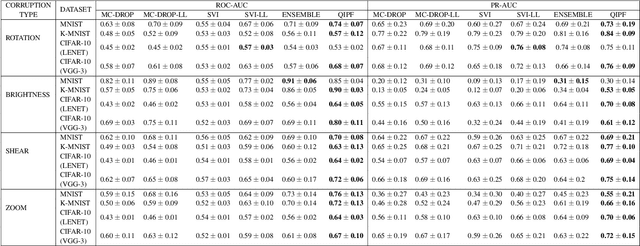
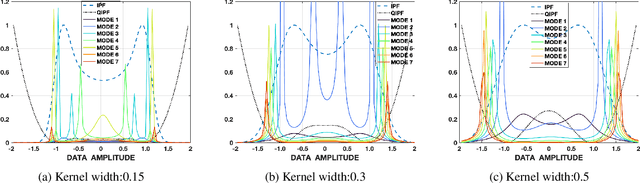
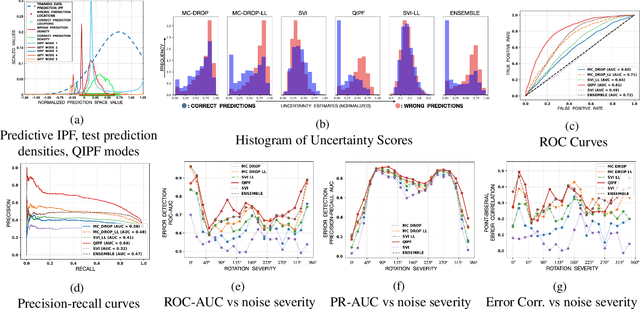
Traditional Bayesian approaches for model uncertainty quantification rely on notoriously difficult processes of marginalization over each network parameter to estimate its probability density function (PDF). Our hypothesis is that internal layer outputs of a trained neural network contain all of the information related to both its mapping function (quantified by its weights) as well as the input data distribution. We therefore propose a framework for predictive uncertainty quantification of a trained neural network that explicitly estimates the PDF of its raw prediction space (before activation), p(y'|x,w), which we refer to as the model PDF, in a Gaussian reproducing kernel Hilbert space (RKHS). The Gaussian RKHS provides a localized density estimate of p(y'|x,w), which further enables us to utilize gradient based formulations of quantum physics to decompose the model PDF in terms of multiple local uncertainty moments that provide much greater resolution of the PDF than the central moments characterized by Bayesian methods. This provides the framework with a better ability to detect distributional shifts in test data away from the training data PDF learned by the model. We evaluate the framework against existing uncertainty quantification methods on benchmark datasets that have been corrupted using common perturbation techniques. The kernel framework is observed to provide model uncertainty estimates with much greater precision based on the ability to detect model prediction errors.
Annotating Motion Primitives for Simplifying Action Search in Reinforcement Learning
Feb 24, 2021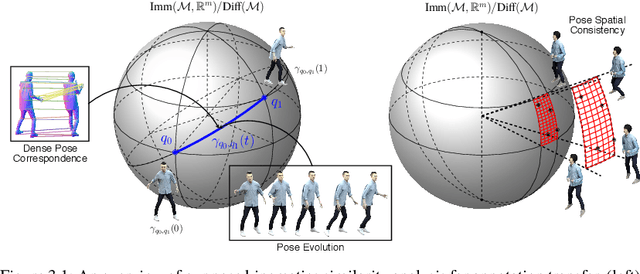
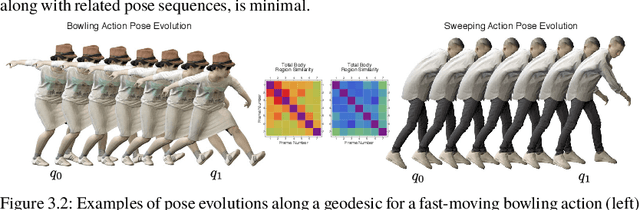
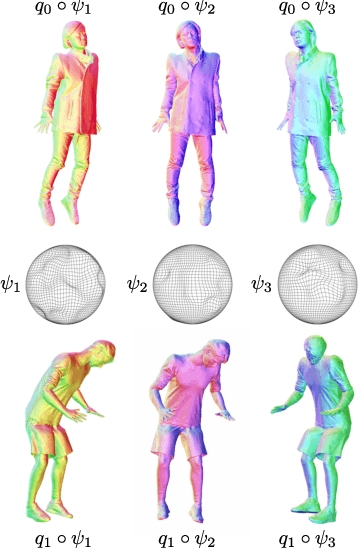
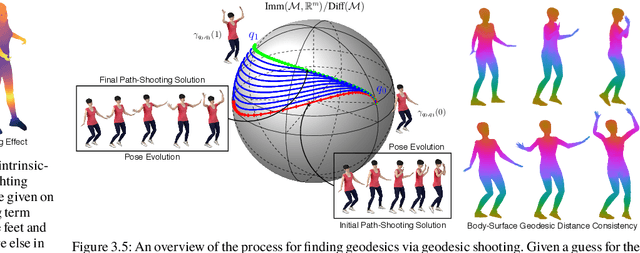
Reinforcement learning in large-scale environments is challenging due to the many possible actions that can be taken in specific situations. We have previously developed a means of constraining, and hence speeding up, the search process through the use of motion primitives; motion primitives are sequences of pre-specified actions taken across a state series. As a byproduct of this work, we have found that if the motion primitives' motions and actions are labeled, then the search can be sped up further. Since motion primitives may initially lack such details, we propose a theoretically viewpoint-insensitive and speed-insensitive means of automatically annotating the underlying motions and actions. We do this through a differential-geometric, spatio-temporal kinematics descriptor, which analyzes how the poses of entities in two motion sequences change over time. We use this descriptor in conjunction with a weighted-nearest-neighbor classifier to label the primitives using a limited set of training examples. In our experiments, we achieve high motion and action annotation rates for human-action-derived primitives with as few as one training sample. We also demonstrate that reinforcement learning using accurately labeled trajectories leads to high-performing policies more quickly than standard reinforcement learning techniques. This is partly because motion primitives encode prior domain knowledge and preempt the need to re-discover that knowledge during training. It is also because agents can leverage the labels to systematically ignore action classes that do not facilitate task objectives, thereby reducing the action space.
Faster Convergence in Deep-Predictive-Coding Networks to Learn Deeper Representations
Feb 05, 2021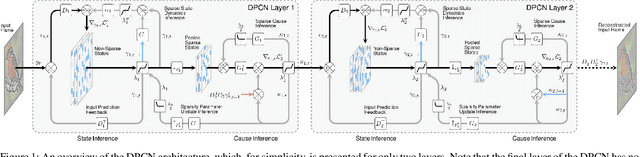
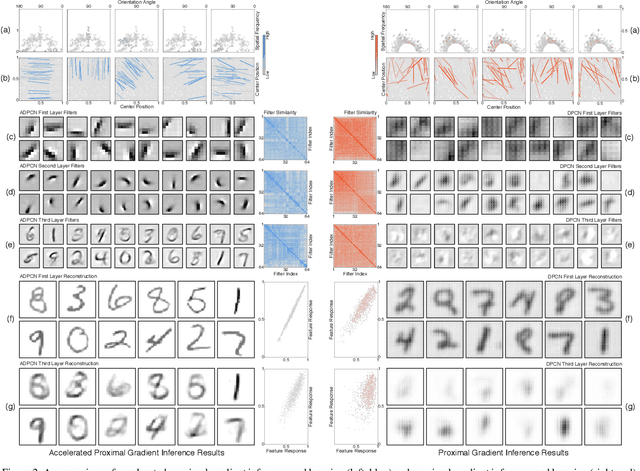


Deep-predictive-coding networks (DPCNs) are hierarchical, generative models that rely on feed-forward and feed-back connections to modulate latent feature representations of stimuli in a dynamic and context-sensitive manner. A crucial element of DPCNs is a forward-backward inference procedure to uncover sparse states of a dynamic model, which are used for invariant feature extraction. However, this inference and the corresponding backwards network parameter updating are major computational bottlenecks. They severely limit the network depths that can be reasonably implemented and easily trained. We therefore propose an optimization strategy, with better empirical and theoretical convergence, based on accelerated proximal gradients. We demonstrate that the ability to construct deeper DPCNs leads to receptive fields that capture well the entire notions of objects on which the networks are trained. This improves the feature representations. It yields completely unsupervised classifiers that surpass convolutional and convolutional-recurrent autoencoders and are on par with convolutional networks trained in a supervised manner. This is despite the DPCNs having orders of magnitude fewer parameters.
Deep Deterministic Information Bottleneck with Matrix-based Entropy Functional
Jan 31, 2021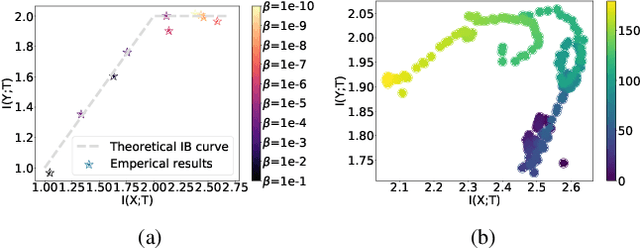



We introduce the matrix-based Renyi's $\alpha$-order entropy functional to parameterize Tishby et al. information bottleneck (IB) principle with a neural network. We term our methodology Deep Deterministic Information Bottleneck (DIB), as it avoids variational inference and distribution assumption. We show that deep neural networks trained with DIB outperform the variational objective counterpart and those that are trained with other forms of regularization, in terms of generalization performance and robustness to adversarial attack.Code available at https://github.com/yuxi120407/DIB
Measuring Dependence with Matrix-based Entropy Functional
Jan 25, 2021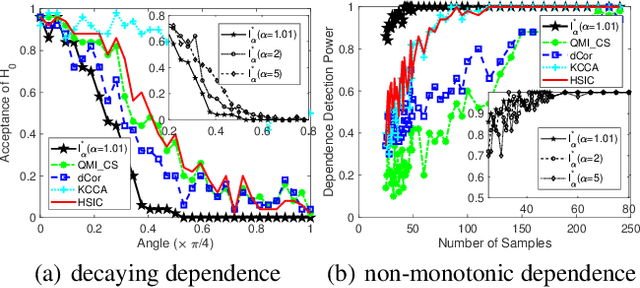

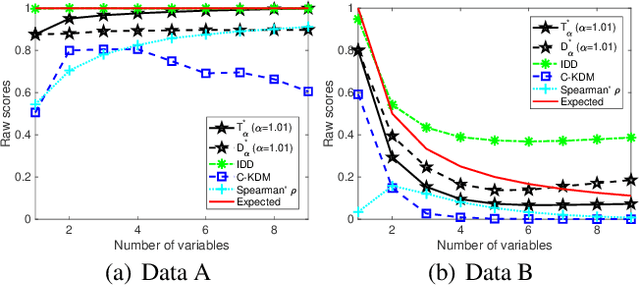
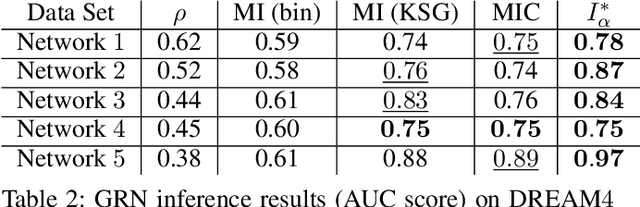
Measuring the dependence of data plays a central role in statistics and machine learning. In this work, we summarize and generalize the main idea of existing information-theoretic dependence measures into a higher-level perspective by the Shearer's inequality. Based on our generalization, we then propose two measures, namely the matrix-based normalized total correlation ($T_\alpha^*$) and the matrix-based normalized dual total correlation ($D_\alpha^*$), to quantify the dependence of multiple variables in arbitrary dimensional space, without explicit estimation of the underlying data distributions. We show that our measures are differentiable and statistically more powerful than prevalent ones. We also show the impact of our measures in four different machine learning problems, namely the gene regulatory network inference, the robust machine learning under covariate shift and non-Gaussian noises, the subspace outlier detection, and the understanding of the learning dynamics of convolutional neural networks (CNNs), to demonstrate their utilities, advantages, as well as implications to those problems. Code of our dependence measure is available at: https://bit.ly/AAAI-dependence
Target Detection and Segmentation in Circular-Scan Synthetic-Aperture-Sonar Images using Semi-Supervised Convolutional Encoder-Decoders
Jan 10, 2021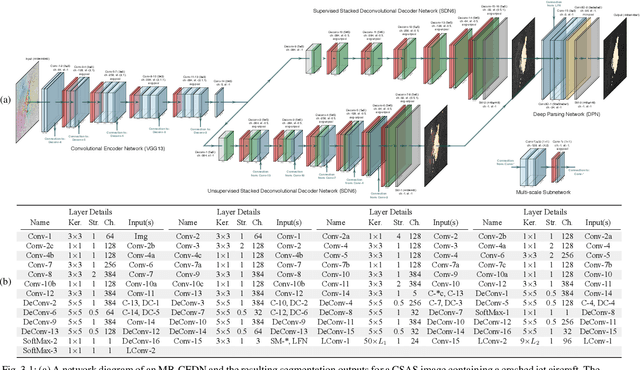
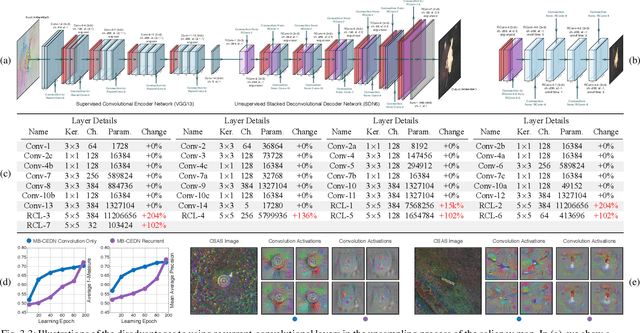
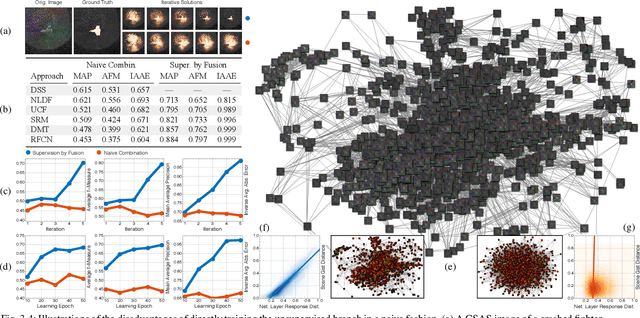
We propose a saliency-based, multi-target detection and segmentation framework for multi-aspect, semi-coherent imagery formed from circular-scan, synthetic-aperture sonar (CSAS). Our framework relies on a multi-branch, convolutional encoder-decoder network (MB-CEDN). The encoder portion extracts features from one or more CSAS images of the targets. These features are then split off and fed into multiple decoders that perform pixel-level classification on the extracted features to roughly mask the target in an unsupervised-trained manner and detect foreground and background pixels in a supervised-trained manner. Each of these target-detection estimates provide different perspectives as to what constitute a target. These opinions are cascaded into a deep-parsing network to model contextual and spatial constraints that help isolate targets better than either solution estimate alone. We evaluate our framework using real-world CSAS data with five broad target classes. Since we are the first to consider both CSAS target detection and segmentation, we adapt existing image and video-processing network topologies from the literature for comparative purposes. We show that our framework outperforms supervised deep networks. It greatly outperforms state-of-the-art unsupervised approaches for diverse target and seafloor types.
Training Deep Architectures Without End-to-End Backpropagation: A Brief Survey
Jan 09, 2021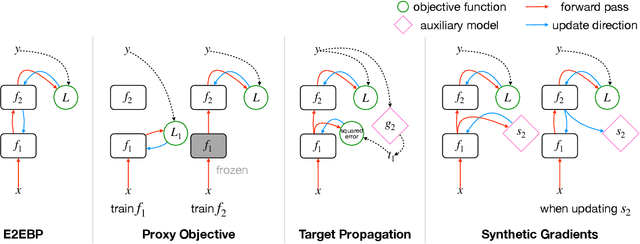

This tutorial paper surveys training alternatives to end-to-end backpropagation (E2EBP) -- the de facto standard for training deep architectures. Modular training refers to strictly local training without both the forward and the backward pass, i.e., dividing a deep architecture into several nonoverlapping modules and training them separately without any end-to-end operation. Between the fully global E2EBP and the strictly local modular training, there are "weakly modular" hybrids performing training without the backward pass only. These alternatives can match or surpass the performance of E2EBP on challenging datasets such as ImageNet, and are gaining increased attention primarily because they offer practical advantages over E2EBP, which will be enumerated herein. In particular, they allow for greater modularity and transparency in deep learning workflows, aligning deep learning with the mainstream computer science engineering that heavily exploits modularization for scalability. Modular training has also revealed novel insights about learning and may have further implications on other important research domains. Specifically, it induces natural and effective solutions to some important practical problems such as data efficiency and transferability estimation.
Unsupervised Foveal Vision Neural Networks with Top-Down Attention
Oct 18, 2020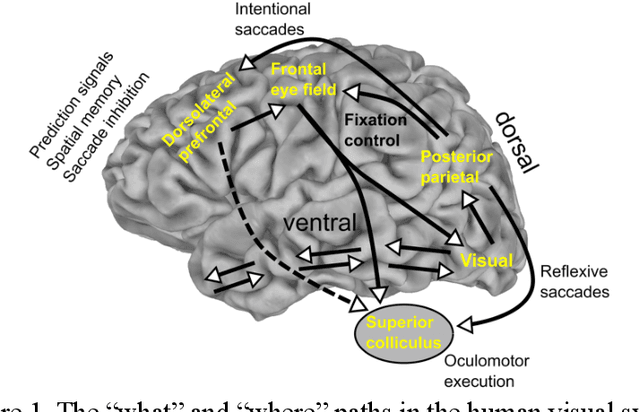
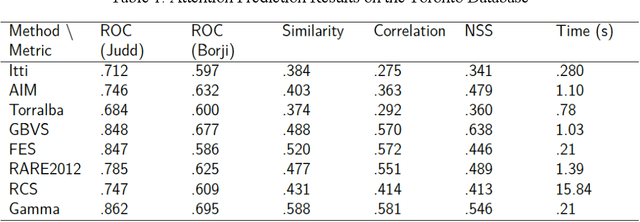
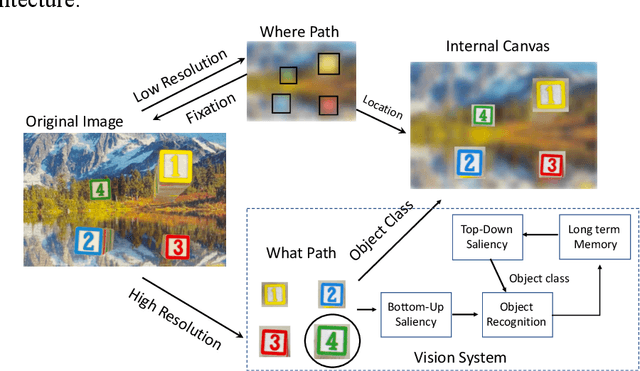

Deep learning architectures are an extremely powerful tool for recognizing and classifying images. However, they require supervised learning and normally work on vectors the size of image pixels and produce the best results when trained on millions of object images. To help mitigate these issues, we propose the fusion of bottom-up saliency and top-down attention employing only unsupervised learning techniques, which helps the object recognition module to focus on relevant data and learn important features that can later be fine-tuned for a specific task. In addition, by utilizing only relevant portions of the data, the training speed can be greatly improved. We test the performance of the proposed Gamma saliency technique on the Toronto and CAT2000 databases, and the foveated vision in the Street View House Numbers (SVHN) database. The results in foveated vision show that Gamma saliency is comparable to the best and computationally faster. The results in SVHN show that our unsupervised cognitive architecture is comparable to fully supervised methods and that the Gamma saliency also improves CNN performance if desired. We also develop a topdown attention mechanism based on the Gamma saliency applied to the top layer of CNNs to improve scene understanding in multi-object images or images with strong background clutter. When we compare the results with human observers in an image dataset of animals occluded in natural scenes, we show that topdown attention is capable of disambiguating object from background and improves system performance beyond the level of human observers.