 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAB: Specification-driven Testing for Algorithmic Bottlenecks
May 27, 2026Evaluating the efficiency of algorithmic code requires test cases that expose runtime bottlenecks. Previous methods generate efficiency test cases either by increasing input size or by generating code-specific inputs that make the given implementation run slowly. Consequently, they do not address the structural input conditions that drive the algorithmic worst case. We introduce STAB, a specification-driven pipeline that generates test cases that expose algorithmic bottlenecks from a natural-language problem specification alone. STAB separates the task into constraint-bound maximization and adversarial structure injection. (i) The constraint saturator extracts constraints and resolves large admissible size assignments using rule-based saturation and CP-SAT optimization over related variables. (ii) The adversarial scenario injector retrieves implementation-level adversarial construction principles from a curated scenario catalog using keyword matching and K-nearest neighbors (KNN). STAB encodes the problem specification, resolved boundary, and retrieved construction principles into a structured generation specification, from which the LLM synthesizes a Python test case generator. On CodeContests, STAB raises the rate of generated test cases that expose algorithmic bottlenecks from 50.43% to 73.45% on average across open-source LLMs and from 57.45% to 71.85% on average across closed-source LLMs, with consistent gains across Python, Java, and C++. Our code is available at https://github.com/suhanmen/STAB.
AmpleHate: Amplifying the Attention for Versatile Implicit Hate Detection
May 26, 2025Implicit hate speech detection is challenging due to its subtlety and reliance on contextual interpretation rather than explicit offensive words. Current approaches rely on contrastive learning, which are shown to be effective on distinguishing hate and non-hate sentences. Humans, however, detect implicit hate speech by first identifying specific targets within the text and subsequently interpreting how these target relate to their surrounding context. Motivated by this reasoning process, we propose AmpleHate, a novel approach designed to mirror human inference for implicit hate detection. AmpleHate identifies explicit target using a pretrained Named Entity Recognition model and capture implicit target information via [CLS] tokens. It computes attention-based relationships between explicit, implicit targets and sentence context and then, directly injects these relational vectors into the final sentence representation. This amplifies the critical signals of target-context relations for determining implicit hate. Experiments demonstrate that AmpleHate achieves state-of-the-art performance, outperforming contrastive learning baselines by an average of 82.14% and achieve faster convergence. Qualitative analyses further reveal that attention patterns produced by AmpleHate closely align with human judgement, underscoring its interpretability and robustness.
URECA: The Chain of Two Minimum Set Cover Problems exists behind Adaptation to Shifts in Semantic Code Search
Feb 11, 2025

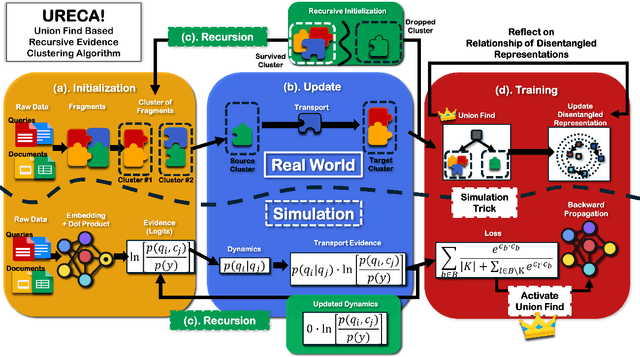

Adaptation is to make model learn the patterns shifted from the training distribution. In general, this adaptation is formulated as the minimum entropy problem. However, the minimum entropy problem has inherent limitation -- shifted initialization cascade phenomenon. We extend the relationship between the minimum entropy problem and the minimum set cover problem via Lebesgue integral. This extension reveals that internal mechanism of the minimum entropy problem ignores the relationship between disentangled representations, which leads to shifted initialization cascade. From the analysis, we introduce a new clustering algorithm, Union-find based Recursive Clustering Algorithm~(URECA). URECA is an efficient clustering algorithm for the leverage of the relationships between disentangled representations. The update rule of URECA depends on Thresholdly-Updatable Stationary Assumption to dynamics as a released version of Stationary Assumption. This assumption helps URECA to transport disentangled representations with no errors based on the relationships between disentangled representations. URECA also utilize simulation trick to efficiently cluster disentangled representations. The wide range of evaluations show that URECA achieves consistent performance gains for the few-shot adaptation to diverse types of shifts along with advancement to State-of-The-Art performance in CoSQA in the scenario of query shift.
ATHENA: Mathematical Reasoning with Thought Expansion
Nov 02, 2023Solving math word problems depends on how to articulate the problems, the lens through which models view human linguistic expressions. Real-world settings count on such a method even more due to the diverse practices of the same mathematical operations. Earlier works constrain available thinking processes by limited prediction strategies without considering their significance in acquiring mathematical knowledge. We introduce Attention-based THought Expansion Network Architecture (ATHENA) to tackle the challenges of real-world practices by mimicking human thought expansion mechanisms in the form of neural network propagation. A thought expansion recurrently generates the candidates carrying the thoughts of possible math expressions driven from the previous step and yields reasonable thoughts by selecting the valid pathways to the goal. Our experiments show that ATHENA achieves a new state-of-the-art stage toward the ideal model that is compelling in variant questions even when the informativeness in training examples is restricted.