 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXMem++: Production-level Video Segmentation From Few Annotated Frames
Aug 15, 2023



Despite advancements in user-guided video segmentation, extracting complex objects consistently for highly complex scenes is still a labor-intensive task, especially for production. It is not uncommon that a majority of frames need to be annotated. We introduce a novel semi-supervised video object segmentation (SSVOS) model, XMem++, that improves existing memory-based models, with a permanent memory module. Most existing methods focus on single frame annotations, while our approach can effectively handle multiple user-selected frames with varying appearances of the same object or region. Our method can extract highly consistent results while keeping the required number of frame annotations low. We further introduce an iterative and attention-based frame suggestion mechanism, which computes the next best frame for annotation. Our method is real-time and does not require retraining after each user input. We also introduce a new dataset, PUMaVOS, which covers new challenging use cases not found in previous benchmarks. We demonstrate SOTA performance on challenging (partial and multi-class) segmentation scenarios as well as long videos, while ensuring significantly fewer frame annotations than any existing method. Project page: https://max810.github.io/xmem2-project-page/
INVE: Interactive Neural Video Editing
Jul 15, 2023We present Interactive Neural Video Editing (INVE), a real-time video editing solution, which can assist the video editing process by consistently propagating sparse frame edits to the entire video clip. Our method is inspired by the recent work on Layered Neural Atlas (LNA). LNA, however, suffers from two major drawbacks: (1) the method is too slow for interactive editing, and (2) it offers insufficient support for some editing use cases, including direct frame editing and rigid texture tracking. To address these challenges we leverage and adopt highly efficient network architectures, powered by hash-grids encoding, to substantially improve processing speed. In addition, we learn bi-directional functions between image-atlas and introduce vectorized editing, which collectively enables a much greater variety of edits in both the atlas and the frames directly. Compared to LNA, our INVE reduces the learning and inference time by a factor of 5, and supports various video editing operations that LNA cannot. We showcase the superiority of INVE over LNA in interactive video editing through a comprehensive quantitative and qualitative analysis, highlighting its numerous advantages and improved performance. For video results, please see https://gabriel-huang.github.io/inve/
Tracking by Associating Clips
Dec 20, 2022The tracking-by-detection paradigm today has become the dominant method for multi-object tracking and works by detecting objects in each frame and then performing data association across frames. However, its sequential frame-wise matching property fundamentally suffers from the intermediate interruptions in a video, such as object occlusions, fast camera movements, and abrupt light changes. Moreover, it typically overlooks temporal information beyond the two frames for matching. In this paper, we investigate an alternative by treating object association as clip-wise matching. Our new perspective views a single long video sequence as multiple short clips, and then the tracking is performed both within and between the clips. The benefits of this new approach are two folds. First, our method is robust to tracking error accumulation or propagation, as the video chunking allows bypassing the interrupted frames, and the short clip tracking avoids the conventional error-prone long-term track memory management. Second, the multiple frame information is aggregated during the clip-wise matching, resulting in a more accurate long-range track association than the current frame-wise matching. Given the state-of-the-art tracking-by-detection tracker, QDTrack, we showcase how the tracking performance improves with our new tracking formulation. We evaluate our proposals on two tracking benchmarks, TAO and MOT17 that have complementary characteristics and challenges each other.
Bridging Images and Videos: A Simple Learning Framework for Large Vocabulary Video Object Detection
Dec 20, 2022Scaling object taxonomies is one of the important steps toward a robust real-world deployment of recognition systems. We have faced remarkable progress in images since the introduction of the LVIS benchmark. To continue this success in videos, a new video benchmark, TAO, was recently presented. Given the recent encouraging results from both detection and tracking communities, we are interested in marrying those two advances and building a strong large vocabulary video tracker. However, supervisions in LVIS and TAO are inherently sparse or even missing, posing two new challenges for training the large vocabulary trackers. First, no tracking supervisions are in LVIS, which leads to inconsistent learning of detection (with LVIS and TAO) and tracking (only with TAO). Second, the detection supervisions in TAO are partial, which results in catastrophic forgetting of absent LVIS categories during video fine-tuning. To resolve these challenges, we present a simple but effective learning framework that takes full advantage of all available training data to learn detection and tracking while not losing any LVIS categories to recognize. With this new learning scheme, we show that consistent improvements of various large vocabulary trackers are capable, setting strong baseline results on the challenging TAO benchmarks.
VideoMap: Video Editing in Latent Space
Nov 22, 2022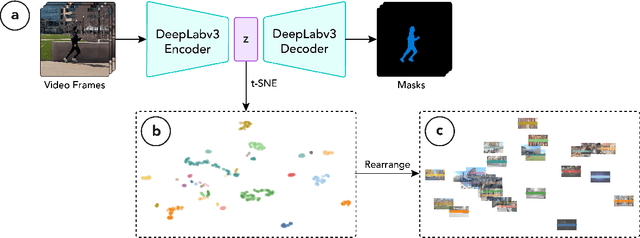
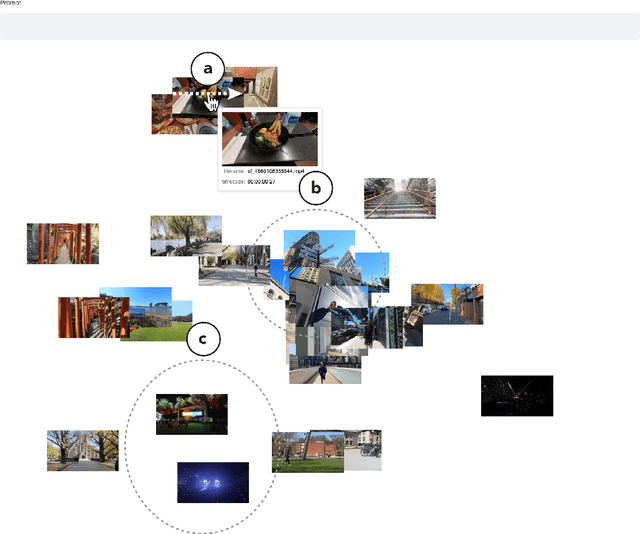
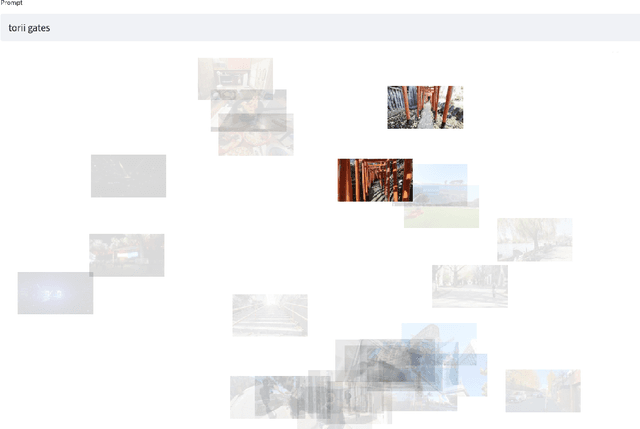
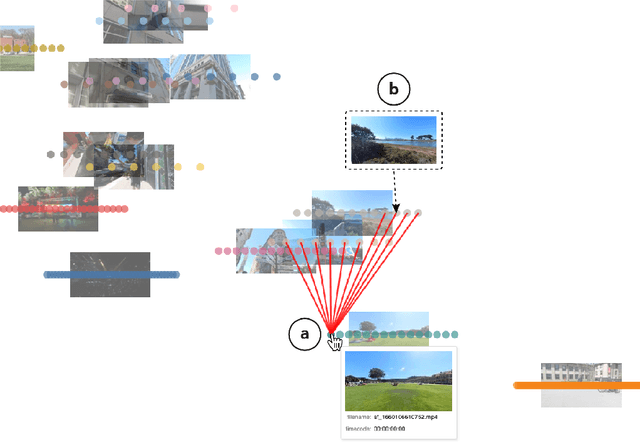
Video has become a dominant form of media. However, video editing interfaces have remained largely unchanged over the past two decades. Such interfaces typically consist of a grid-like asset management panel and a linear editing timeline. When working with a large number of video clips, it can be difficult to sort through them all and identify patterns within (e.g. opportunities for smooth transitions and storytelling). In this work, we imagine a new paradigm for video editing by mapping videos into a 2D latent space and building a proof-of-concept interface.
Videogenic: Video Highlights via Photogenic Moments
Nov 22, 2022This paper investigates the challenge of extracting highlight moments from videos. To perform this task, a system needs to understand what constitutes a highlight for arbitrary video domains while at the same time being able to scale across different domains. Our key insight is that photographs taken by photographers tend to capture the most remarkable or photogenic moments of an activity. Drawing on this insight, we present Videogenic, a system capable of creating domain-specific highlight videos for a wide range of domains. In a human evaluation study (N=50), we show that a high-quality photograph collection combined with CLIP-based retrieval (which uses a neural network with semantic knowledge of images) can serve as an excellent prior for finding video highlights. In a within-subjects expert study (N=12), we demonstrate the usefulness of Videogenic in helping video editors create highlight videos with lighter workload, shorter task completion time, and better usability.
A Generalized Framework for Video Instance Segmentation
Nov 16, 2022



Recently, handling long videos of complex and occluded sequences has emerged as a new challenge in the video instance segmentation (VIS) community. However, existing methods show limitations in addressing the challenge. We argue that the biggest bottleneck in current approaches is the discrepancy between the training and the inference. To effectively bridge the gap, we propose a \textbf{Gen}eralized framework for \textbf{VIS}, namely \textbf{GenVIS}, that achieves the state-of-the-art performance on challenging benchmarks without designing complicated architectures or extra post-processing. The key contribution of GenVIS is the learning strategy. Specifically, we propose a query-based training pipeline for sequential learning, using a novel target label assignment strategy. To further fill the remaining gaps, we introduce a memory that effectively acquires information from previous states. Thanks to the new perspective, which focuses on building relationships between separate frames or clips, GenVIS can be flexibly executed in both online and semi-online manner. We evaluate our methods on popular VIS benchmarks, YouTube-VIS 2019/2021/2022 and Occluded VIS (OVIS), achieving state-of-the-art results. Notably, we greatly outperform the state-of-the-art on the long VIS benchmark (OVIS), improving 5.6 AP with ResNet-50 backbone. Code will be available at https://github.com/miranheo/GenVIS.
Per-Clip Video Object Segmentation
Aug 03, 2022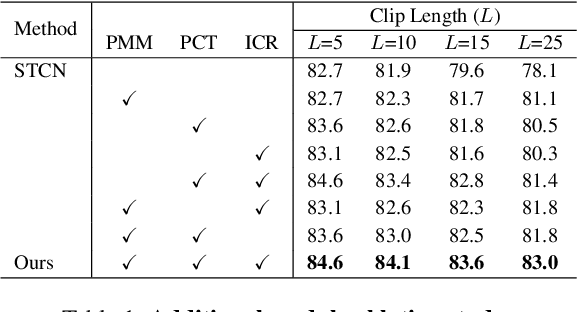
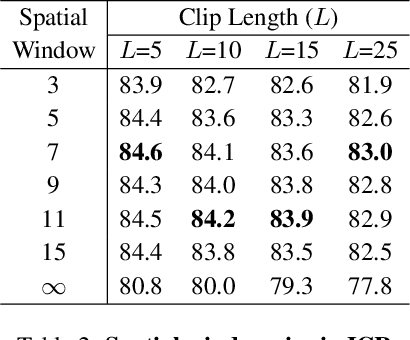
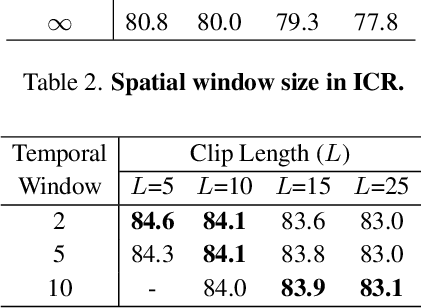

Recently, memory-based approaches show promising results on semi-supervised video object segmentation. These methods predict object masks frame-by-frame with the help of frequently updated memory of the previous mask. Different from this per-frame inference, we investigate an alternative perspective by treating video object segmentation as clip-wise mask propagation. In this per-clip inference scheme, we update the memory with an interval and simultaneously process a set of consecutive frames (i.e. clip) between the memory updates. The scheme provides two potential benefits: accuracy gain by clip-level optimization and efficiency gain by parallel computation of multiple frames. To this end, we propose a new method tailored for the per-clip inference. Specifically, we first introduce a clip-wise operation to refine the features based on intra-clip correlation. In addition, we employ a progressive matching mechanism for efficient information-passing within a clip. With the synergy of two modules and a newly proposed per-clip based training, our network achieves state-of-the-art performance on Youtube-VOS 2018/2019 val (84.6% and 84.6%) and DAVIS 2016/2017 val (91.9% and 86.1%). Furthermore, our model shows a great speed-accuracy trade-off with varying memory update intervals, which leads to huge flexibility.
One-Trimap Video Matting
Jul 27, 2022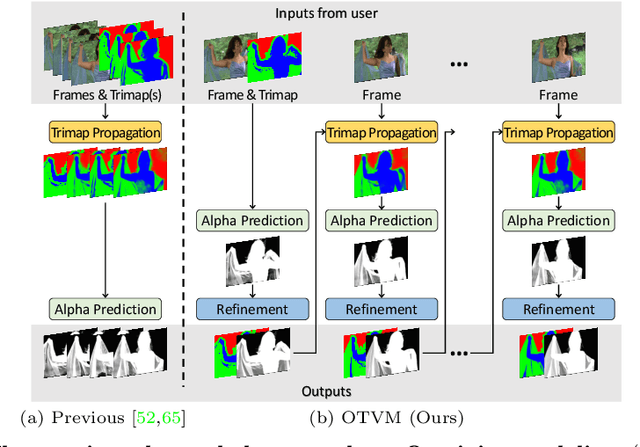
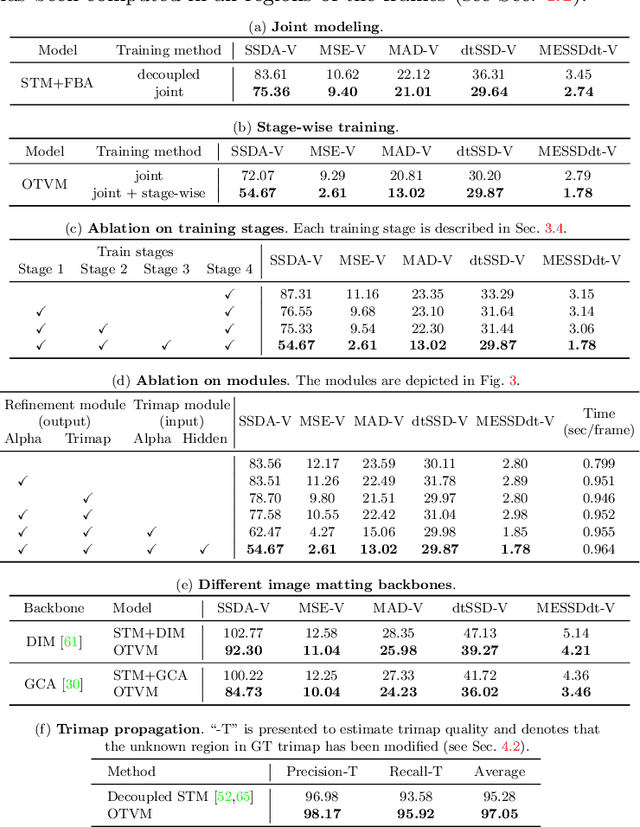
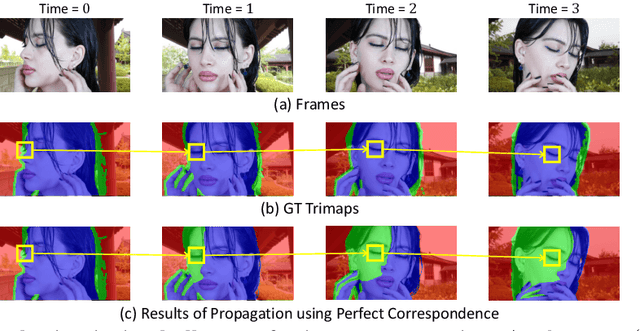
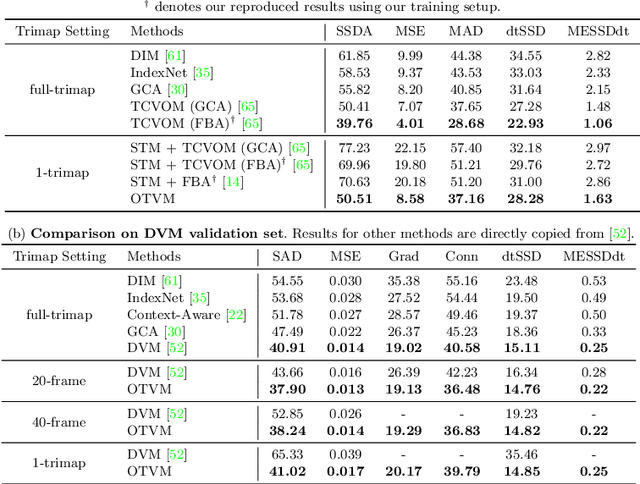
Recent studies made great progress in video matting by extending the success of trimap-based image matting to the video domain. In this paper, we push this task toward a more practical setting and propose One-Trimap Video Matting network (OTVM) that performs video matting robustly using only one user-annotated trimap. A key of OTVM is the joint modeling of trimap propagation and alpha prediction. Starting from baseline trimap propagation and alpha prediction networks, our OTVM combines the two networks with an alpha-trimap refinement module to facilitate information flow. We also present an end-to-end training strategy to take full advantage of the joint model. Our joint modeling greatly improves the temporal stability of trimap propagation compared to the previous decoupled methods. We evaluate our model on two latest video matting benchmarks, Deep Video Matting and VideoMatting108, and outperform state-of-the-art by significant margins (MSE improvements of 56.4% and 56.7%, respectively). The source code and model are available online: https://github.com/Hongje/OTVM.
The Anatomy of Video Editing: A Dataset and Benchmark Suite for AI-Assisted Video Editing
Jul 21, 2022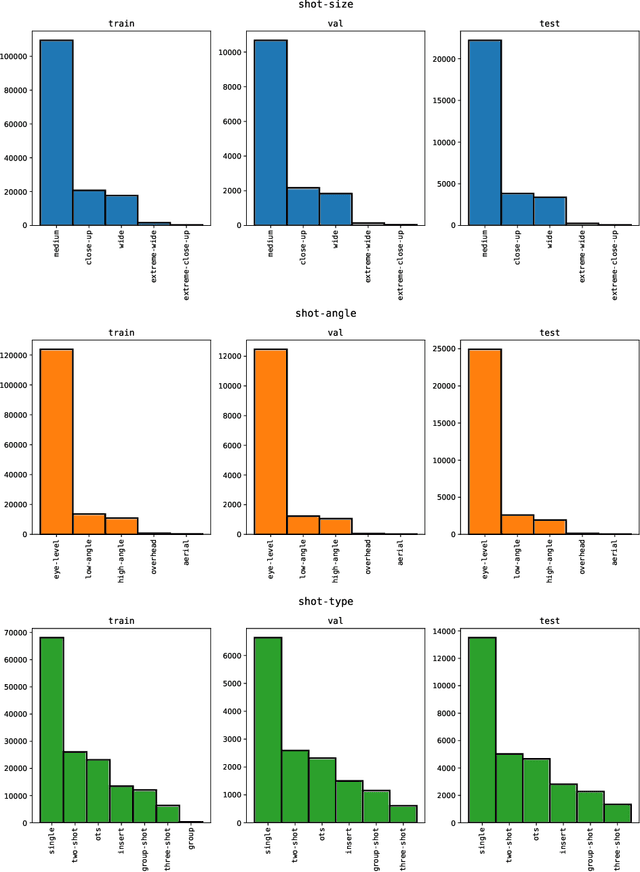
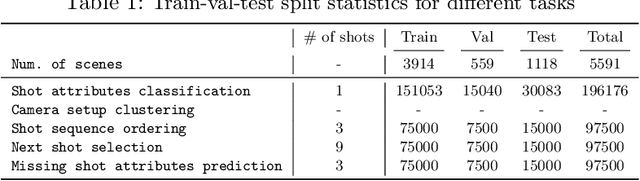
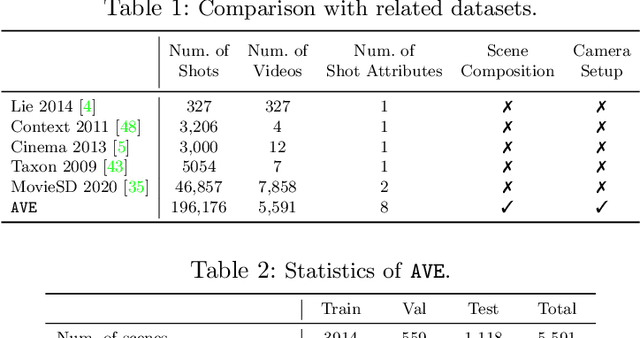
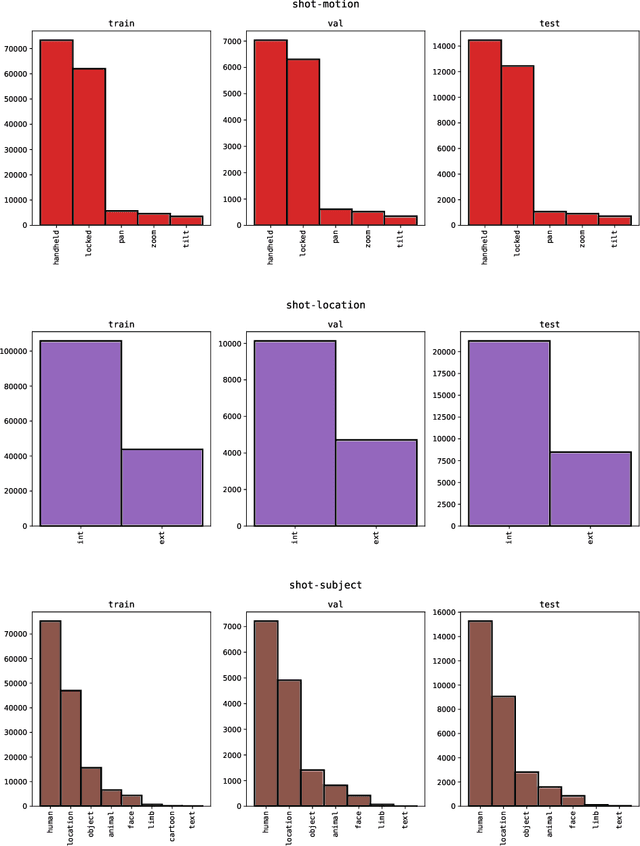
Machine learning is transforming the video editing industry. Recent advances in computer vision have leveled-up video editing tasks such as intelligent reframing, rotoscoping, color grading, or applying digital makeups. However, most of the solutions have focused on video manipulation and VFX. This work introduces the Anatomy of Video Editing, a dataset, and benchmark, to foster research in AI-assisted video editing. Our benchmark suite focuses on video editing tasks, beyond visual effects, such as automatic footage organization and assisted video assembling. To enable research on these fronts, we annotate more than 1.5M tags, with relevant concepts to cinematography, from 196176 shots sampled from movie scenes. We establish competitive baseline methods and detailed analyses for each of the tasks. We hope our work sparks innovative research towards underexplored areas of AI-assisted video editing.