 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Action Chunking via Multi-Chunk Q Value Estimation
May 11, 2026Action chunking emerged as a pivotal technique in imitation learning, enabling policies to predict cohesive action sequences rather than single actions. Recently, this approach has expanded to reinforcement learning (RL), enhancing behavioral consistency and reducing bootstrapping errors in value function estimation. However, existing methods rely on a fixed chunk length, creating a performance bottleneck as the optimal length varies across states and tasks. In this paper, we propose Adaptive Action CHunking (ACH), a novel offline-to-online RL algorithm that dynamically modulates chunk length during both training and inference. To find the optimal chunk length for a dynamically varying current state, we simultaneously estimate action-values for all candidate chunk lengths in a single forward pass, using a Transformer-based architecture. Our mechanism allows the agent to select the most effective chunk length adaptively based on the current state. Evaluated on 34 challenging tasks, ACH consistently outperforms fixed-length baselines, demonstrating superior generalization and learning efficiency in complex environments.
Domain Adaptive Imitation Learning with Visual Observation
Dec 01, 2023In this paper, we consider domain-adaptive imitation learning with visual observation, where an agent in a target domain learns to perform a task by observing expert demonstrations in a source domain. Domain adaptive imitation learning arises in practical scenarios where a robot, receiving visual sensory data, needs to mimic movements by visually observing other robots from different angles or observing robots of different shapes. To overcome the domain shift in cross-domain imitation learning with visual observation, we propose a novel framework for extracting domain-independent behavioral features from input observations that can be used to train the learner, based on dual feature extraction and image reconstruction. Empirical results demonstrate that our approach outperforms previous algorithms for imitation learning from visual observation with domain shift.
Robust Imitation Learning against Variations in Environment Dynamics
Jun 19, 2022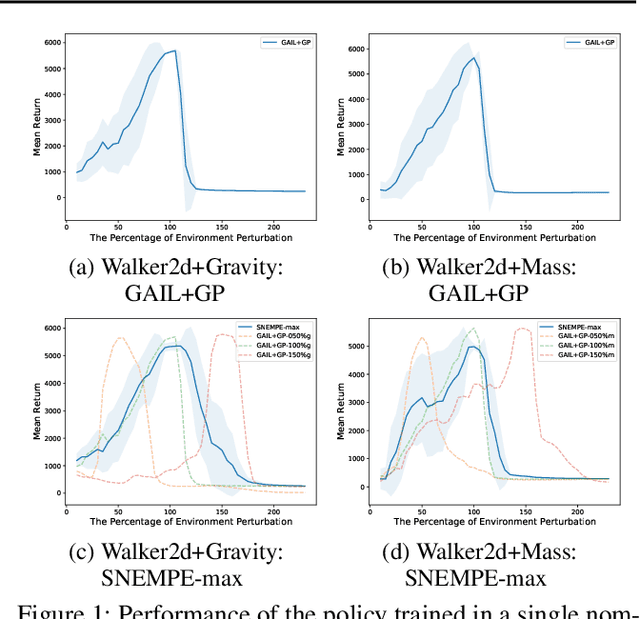
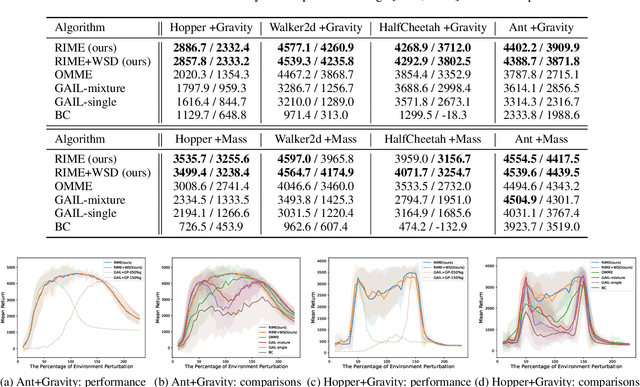
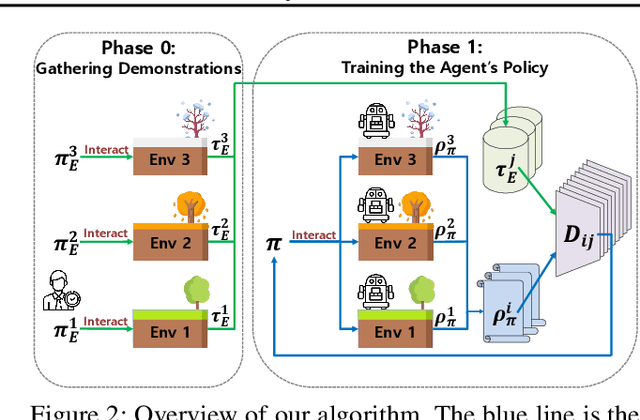
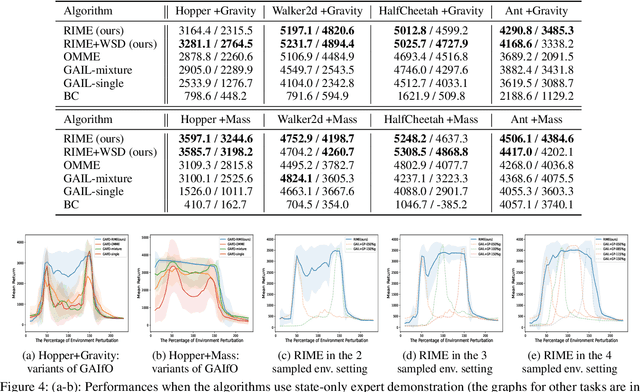
In this paper, we propose a robust imitation learning (IL) framework that improves the robustness of IL when environment dynamics are perturbed. The existing IL framework trained in a single environment can catastrophically fail with perturbations in environment dynamics because it does not capture the situation that underlying environment dynamics can be changed. Our framework effectively deals with environments with varying dynamics by imitating multiple experts in sampled environment dynamics to enhance the robustness in general variations in environment dynamics. In order to robustly imitate the multiple sample experts, we minimize the risk with respect to the Jensen-Shannon divergence between the agent's policy and each of the sample experts. Numerical results show that our algorithm significantly improves robustness against dynamics perturbations compared to conventional IL baselines.