 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised 3D Object Detection from Monocular Pseudo-LiDAR
Sep 20, 2022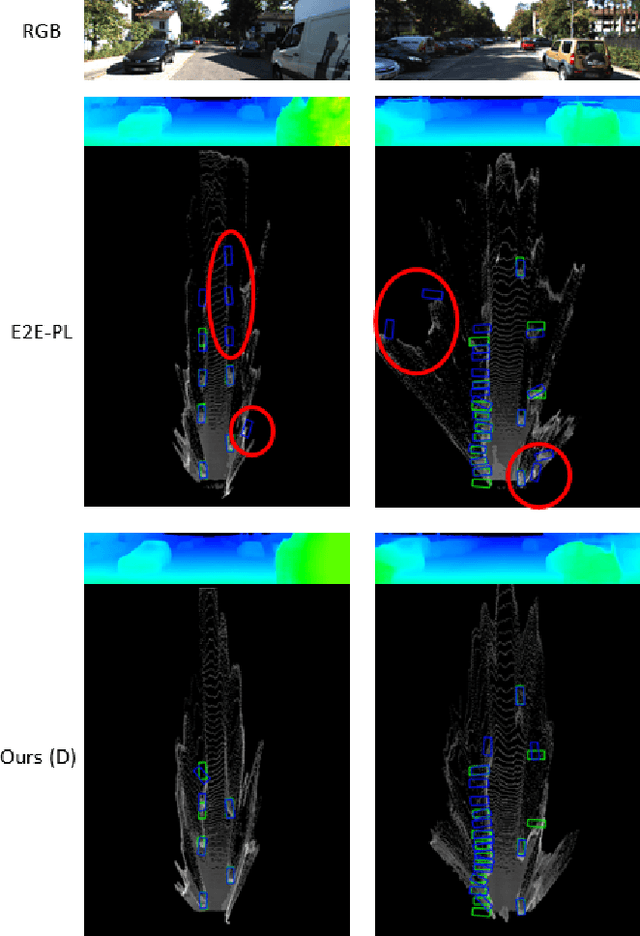
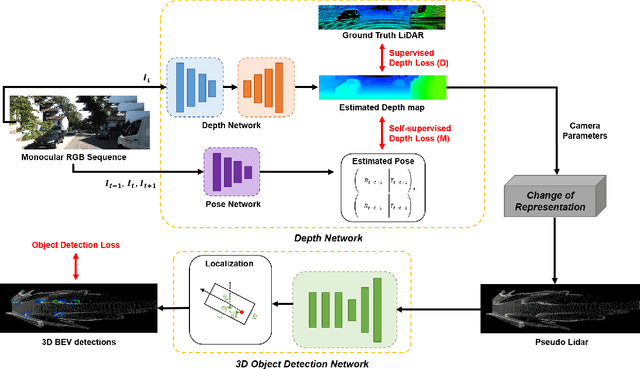

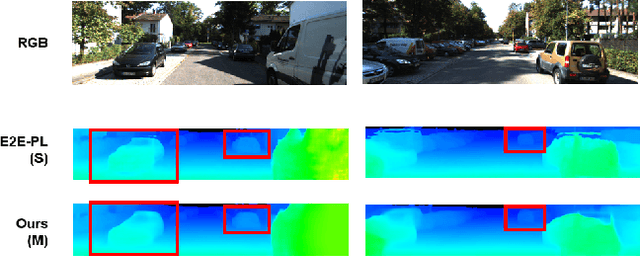
There have been attempts to detect 3D objects by fusion of stereo camera images and LiDAR sensor data or using LiDAR for pre-training and only monocular images for testing, but there have been less attempts to use only monocular image sequences due to low accuracy. In addition, when depth prediction using only monocular images, only scale-inconsistent depth can be predicted, which is the reason why researchers are reluctant to use monocular images alone. Therefore, we propose a method for predicting absolute depth and detecting 3D objects using only monocular image sequences by enabling end-to-end learning of detection networks and depth prediction networks. As a result, the proposed method surpasses other existing methods in performance on the KITTI 3D dataset. Even when monocular image and 3D LiDAR are used together during training in an attempt to improve performance, ours exhibit is the best performance compared to other methods using the same input. In addition, end-to-end learning not only improves depth prediction performance, but also enables absolute depth prediction, because our network utilizes the fact that the size of a 3D object such as a car is determined by the approximate size.
Writing in The Air: Unconstrained Text Recognition from Finger Movement Using Spatio-Temporal Convolution
Apr 19, 2021
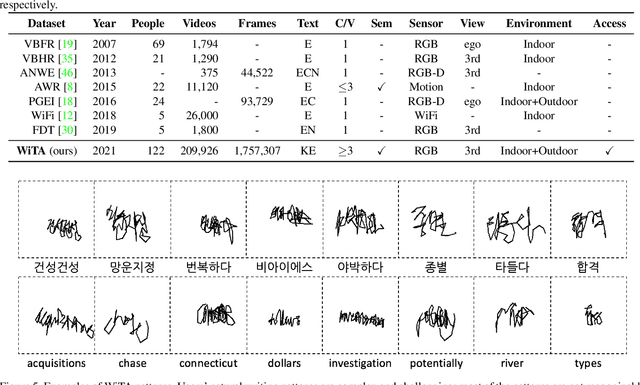

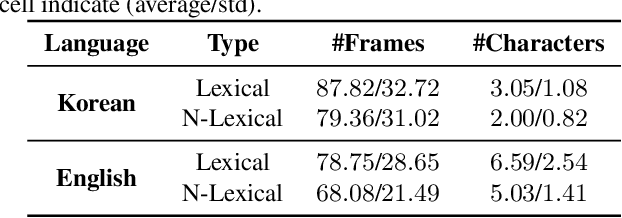
In this paper, we introduce a new benchmark dataset for the challenging writing in the air (WiTA) task -- an elaborate task bridging vision and NLP. WiTA implements an intuitive and natural writing method with finger movement for human-computer interaction (HCI). Our WiTA dataset will facilitate the development of data-driven WiTA systems which thus far have displayed unsatisfactory performance -- due to lack of dataset as well as traditional statistical models they have adopted. Our dataset consists of five sub-datasets in two languages (Korean and English) and amounts to 209,926 video instances from 122 participants. We capture finger movement for WiTA with RGB cameras to ensure wide accessibility and cost-efficiency. Next, we propose spatio-temporal residual network architectures inspired by 3D ResNet. These models perform unconstrained text recognition from finger movement, guarantee a real-time operation by processing 435 and 697 decoding frames-per-second for Korean and English, respectively, and will serve as an evaluation standard. Our dataset and the source codes are available at https://github.com/Uehwan/WiTA.
GSECnet: Ground Segmentation of Point Clouds for Edge Computing
Apr 05, 2021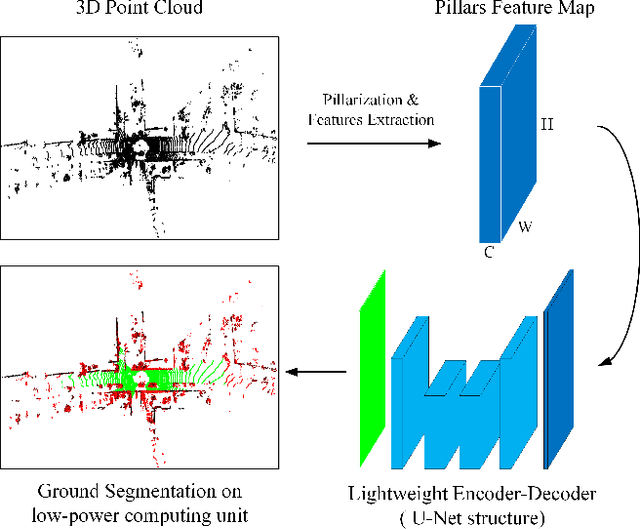
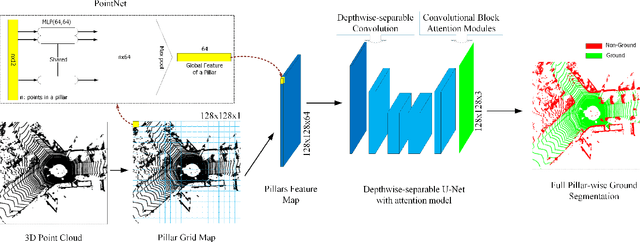

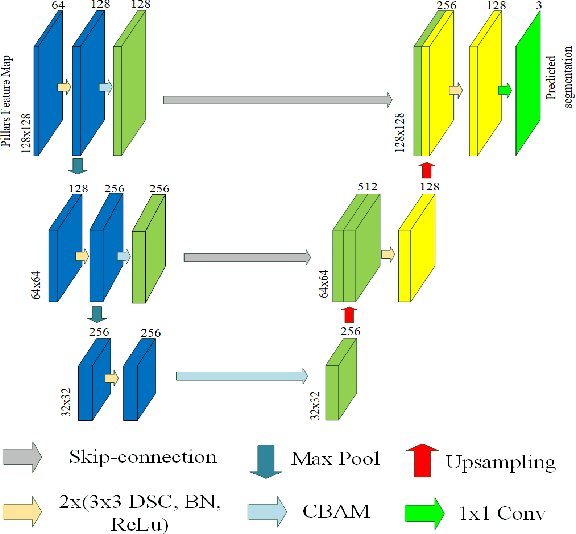
Ground segmentation of point clouds remains challenging because of the sparse and unordered data structure. This paper proposes the GSECnet - Ground Segmentation network for Edge Computing, an efficient ground segmentation framework of point clouds specifically designed to be deployable on a low-power edge computing unit. First, raw point clouds are converted into a discretization representation by pillarization. Afterward, features of points within pillars are fed into PointNet to get the corresponding pillars feature map. Then, a depthwise-separable U-Net with the attention module learns the classification from the pillars feature map with an enormously diminished model parameter size. Our proposed framework is evaluated on SemanticKITTI against both point-based and discretization-based state-of-the-art learning approaches, and achieves an excellent balance between high accuracy and low computing complexity. Remarkably, our framework achieves the inference runtime of 135.2 Hz on a desktop platform. Moreover, experiments verify that it is deployable on a low-power edge computing unit powered 10 watts only.
Revisiting Self-Supervised Monocular Depth Estimation
Mar 23, 2021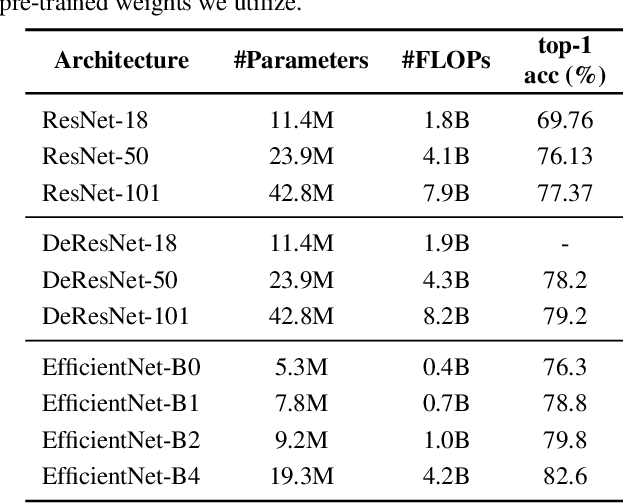
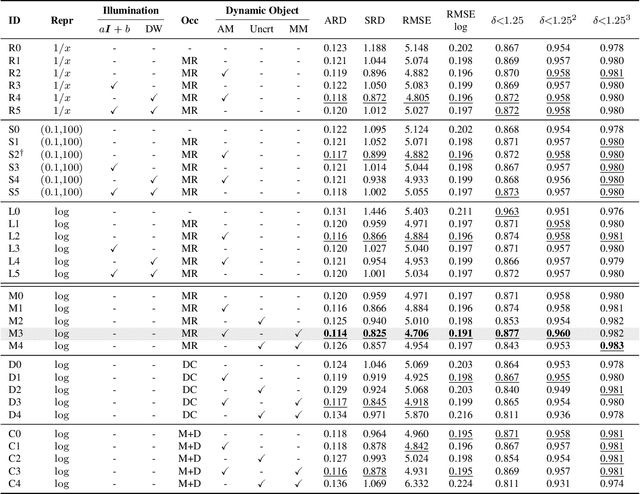

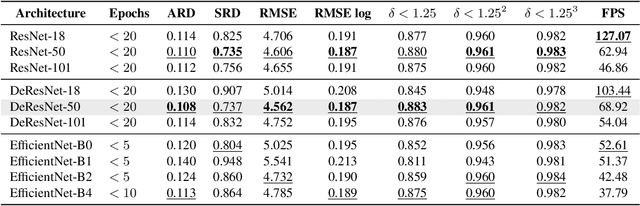
Self-supervised learning of depth map prediction and motion estimation from monocular video sequences is of vital importance -- since it realizes a broad range of tasks in robotics and autonomous vehicles. A large number of research efforts have enhanced the performance by tackling illumination variation, occlusions, and dynamic objects, to name a few. However, each of those efforts targets individual goals and endures as separate works. Moreover, most of previous works have adopted the same CNN architecture, not reaping architectural benefits. Therefore, the need to investigate the inter-dependency of the previous methods and the effect of architectural factors remains. To achieve these objectives, we revisit numerous previously proposed self-supervised methods for joint learning of depth and motion, perform a comprehensive empirical study, and unveil multiple crucial insights. Furthermore, we remarkably enhance the performance as a result of our study -- outperforming previous state-of-the-art performance.
ChangeSim: Towards End-to-End Online Scene Change Detection in Industrial Indoor Environments
Mar 09, 2021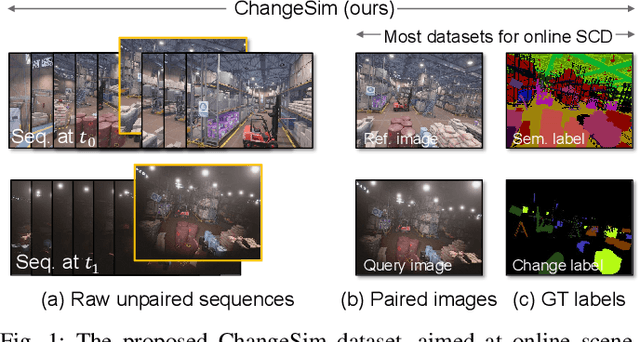

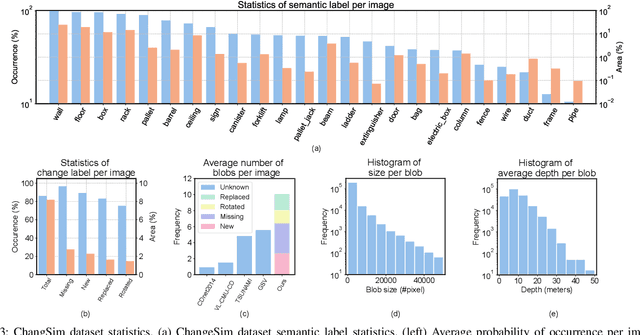

We present a challenging dataset, ChangeSim, aimed at online scene change detection (SCD) and more. The data is collected in photo-realistic simulation environments with the presence of environmental non-targeted variations, such as air turbidity and light condition changes, as well as targeted object changes in industrial indoor environments. By collecting data in simulations, multi-modal sensor data and precise ground truth labels are obtainable such as the RGB image, depth image, semantic segmentation, change segmentation, camera poses, and 3D reconstructions. While the previous online SCD datasets evaluate models given well-aligned image pairs, ChangeSim also provides raw unpaired sequences that present an opportunity to develop an online SCD model in an end-to-end manner, considering both pairing and detection. Experiments show that even the latest pair-based SCD models suffer from the bottleneck of the pairing process, and it gets worse when the environment contains the non-targeted variations. Our dataset is available at http://sammica.github.io/ChangeSim/.
RDIS: Random Drop Imputation with Self-Training for Incomplete Time Series Data
Oct 20, 2020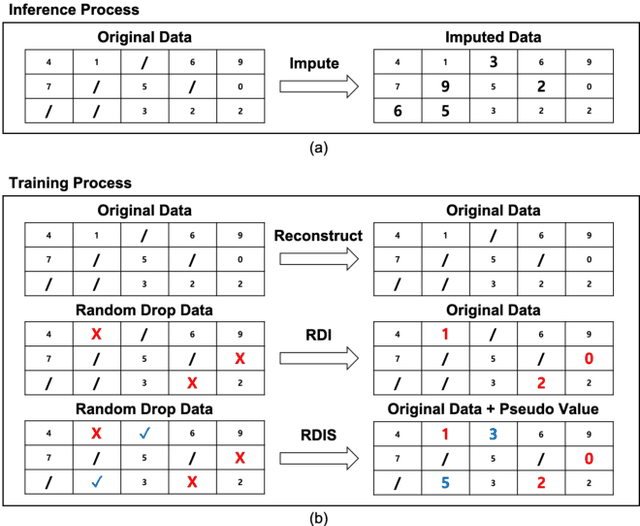
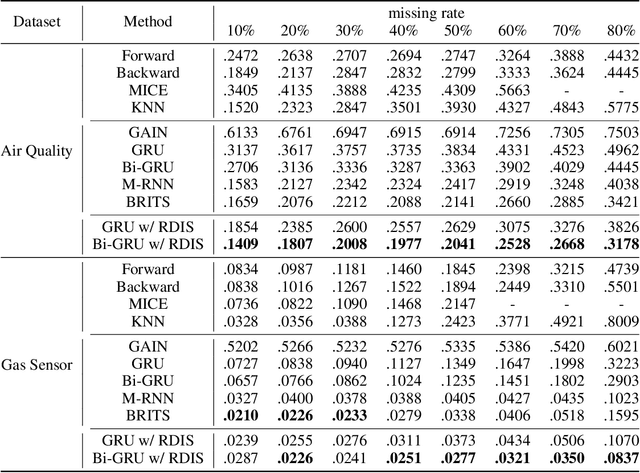
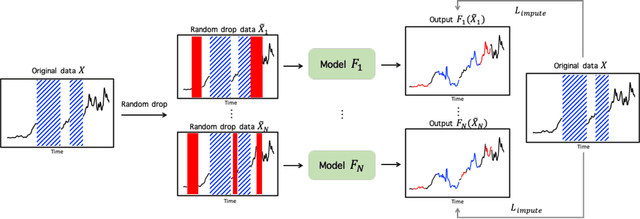

It is common that time-series data with missing values are encountered in many fields such as in finance, meteorology, and robotics. Imputation is an intrinsic method to handle such missing values. In the previous research, most of imputation networks were trained implicitly for the incomplete time series data because missing values have no ground truth. This paper proposes Random Drop Imputation with Self-training (RDIS), a novel training method for imputation networks for the incomplete time-series data. In RDIS, there are extra missing values by applying a random drop on the given incomplete data such that the imputation network can explicitly learn by imputing the random drop values. Also, self-training is introduced to exploit the original missing values without ground truth. To verify the effectiveness of our RDIS on imputation tasks, we graft RDIS to a bidirectional GRU and achieve state-of-the-art results on two real-world datasets, an air quality dataset and a gas sensor dataset with 7.9% and 5.8% margin, respectively.
Continual Unsupervised Domain Adaptation with Adversarial Learning
Oct 19, 2020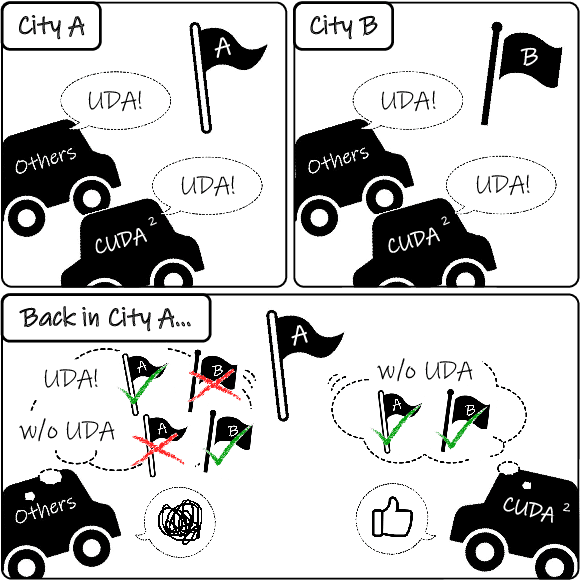
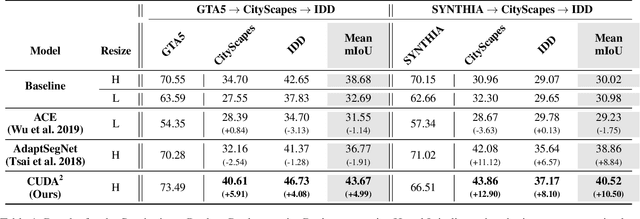
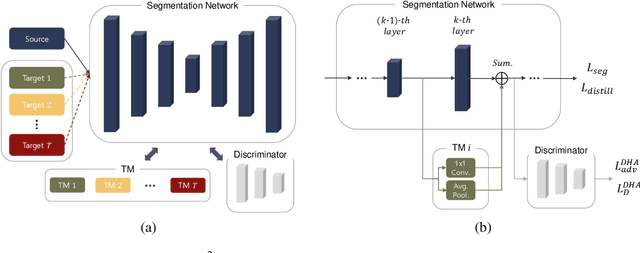
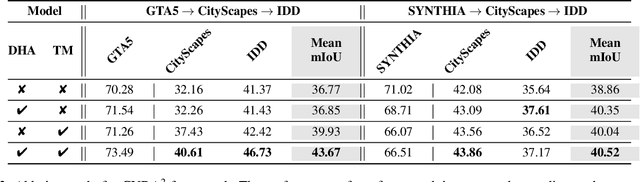
Unsupervised Domain Adaptation (UDA) is essential for autonomous driving due to a lack of labeled real-world road images. Most of the existing UDA methods, however, have focused on a single-step domain adaptation (Synthetic-to-Real). These methods overlook a change in environments in the real world as time goes by. Thus, developing a domain adaptation method for sequentially changing target domains without catastrophic forgetting is required for real-world applications. To deal with the problem above, we propose Continual Unsupervised Domain Adaptation with Adversarial learning (CUDA^2) framework, which can generally be applicable to other UDA methods conducting adversarial learning. CUDA^2 framework generates a sub-memory, called Target-specific Memory (TM) for each new target domain guided by Double Hinge Adversarial (DHA) loss. TM prevents catastrophic forgetting by storing target-specific information, and DHA loss induces a synergy between the existing network and the expanded TM. To the best of our knowledge, we consider realistic autonomous driving scenarios (Synthetic-to-Real-to-Real) in UDA research for the first time. The model with our framework outperforms other state-of-the-art models under the same settings. Besides, extensive experiments are conducted as ablation studies for in-depth analysis.
A Real-time Vision Framework for Pedestrian Behavior Recognition and Intention Prediction at Intersections Using 3D Pose Estimation
Sep 23, 2020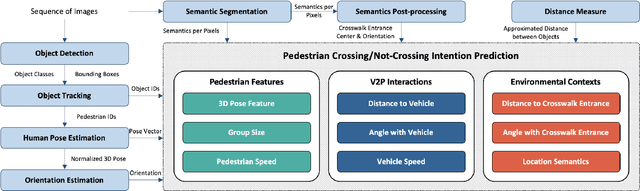
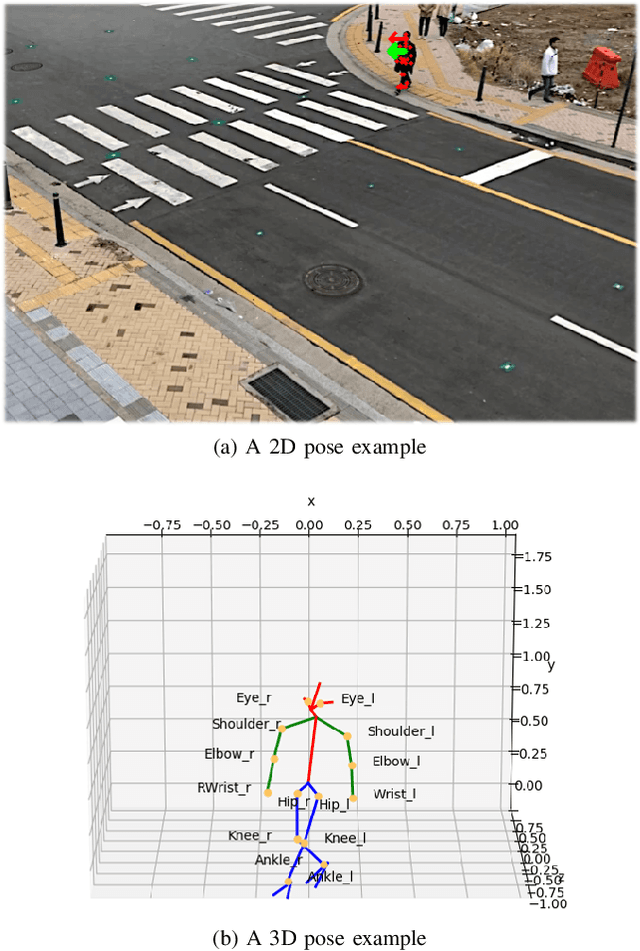
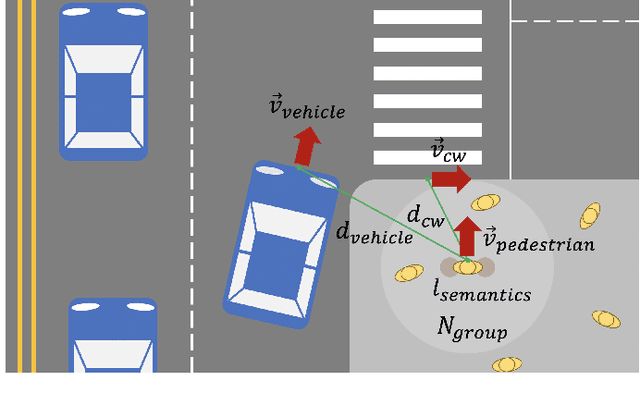

Minimizing traffic accidents between vehicles and pedestrians is one of the primary research goals in intelligent transportation systems. To achieve the goal, pedestrian behavior recognition and prediction of pedestrian's crossing or not-crossing intention play a central role. Contemporary approaches do not guarantee satisfactory performance due to lack of generalization, the requirement of manual data labeling, and high computational complexity. To overcome these limitations, we propose a real-time vision framework for two tasks: pedestrian behavior recognition (100.53 FPS) and intention prediction (35.76 FPS). Our framework obtains satisfying generalization over multiple sites because of the proposed site-independent features. At the center of the feature extraction lies 3D pose estimation. The 3D pose analysis enables robust and accurate recognition of pedestrian behaviors and prediction of intentions over multiple sites. The proposed vision framework realizes 89.3% accuracy in the behavior recognition task on the TUD dataset without any training process and 91.28% accuracy in intention prediction on our dataset achieving new state-of-the-art performance. To contribute to the corresponding research community, we make our source codes public which are available at https://github.com/Uehwan/VisionForPedestrian
SimVODIS: Simultaneous Visual Odometry, Object Detection, and Instance Segmentation
Nov 16, 2019
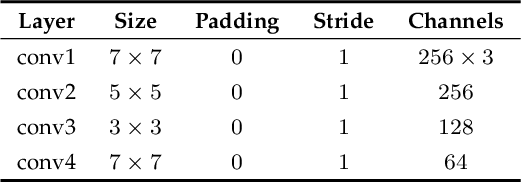


Intelligent agents need to understand the surrounding environment to provide meaningful services to or interact intelligently with humans. The agents should perceive geometric features as well as semantic entities inherent in the environment. Contemporary methods in general provide one type of information regarding the environment at a time, making it difficult to conduct high-level tasks. Moreover, running two types of methods and associating two resultant information requires a lot of computation and complicates the software architecture. To overcome these limitations, we propose a neural architecture that simultaneously performs both geometric and semantic tasks in a single thread: simultaneous visual odometry, object detection, and instance segmentation (SimVODIS). Training SimVODIS requires unlabeled video sequences and the photometric consistency between input image frames generates self-supervision signals. The performance of SimVODIS outperforms or matches the state-of-the-art performance in pose estimation, depth map prediction, object detection, and instance segmentation tasks while completing all the tasks in a single thread. We expect SimVODIS would enhance the autonomy of intelligent agents and let the agents provide effective services to humans.
Convolutional Recurrent Reconstructive Network for Spatiotemporal Anomaly Detection in Solder Paste Inspection
Aug 22, 2019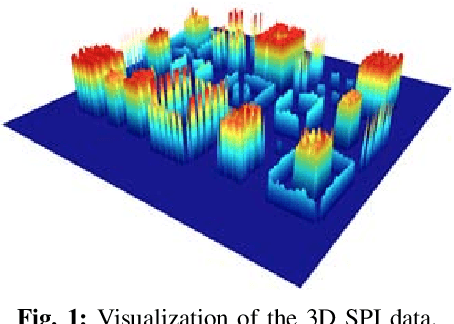
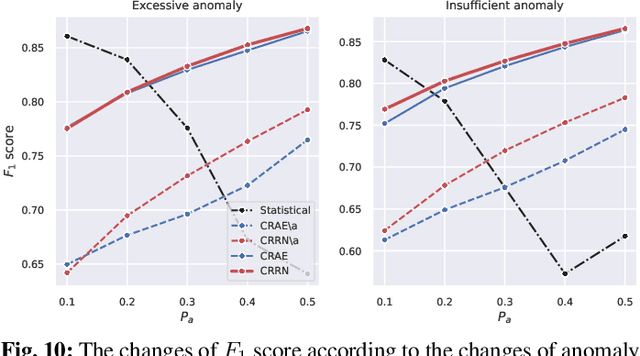
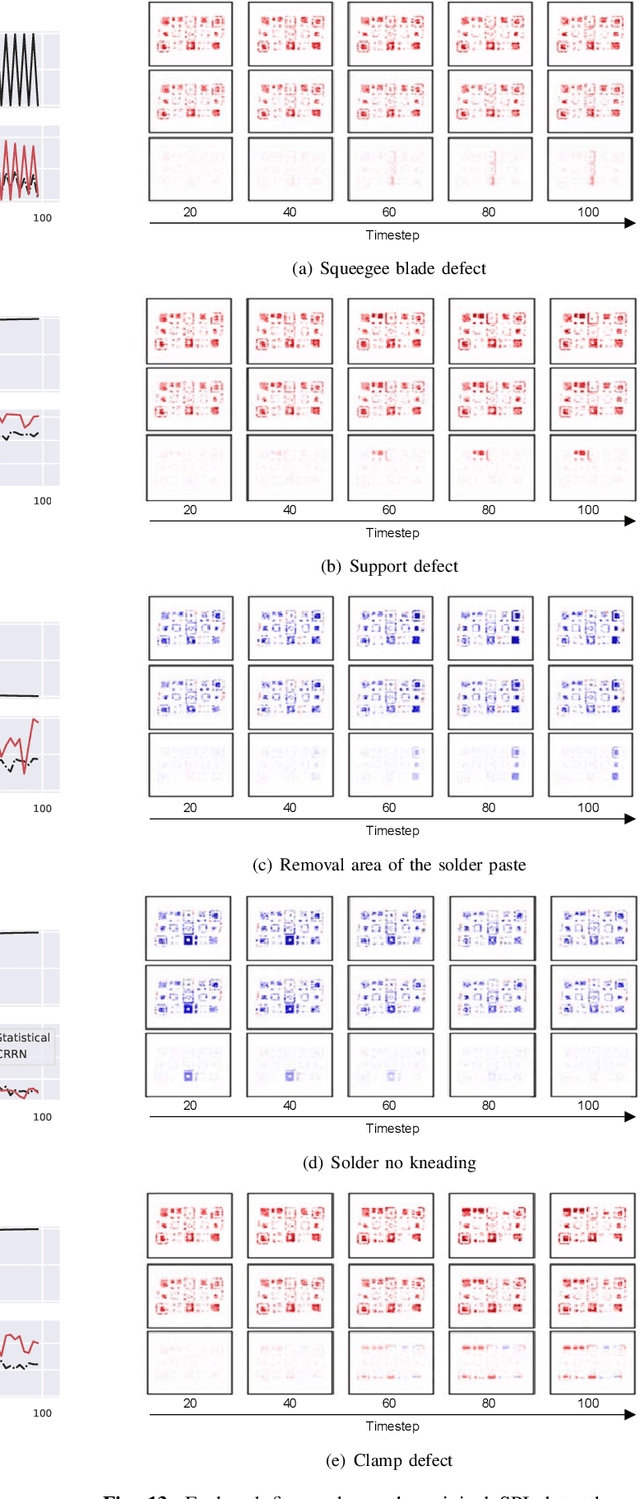
Surface mount technology (SMT) is a process for producing printed circuit boards. Solder paste printer (SPP), package mounter, and solder reflow oven are used for SMT. The board on which the solder paste is deposited from the SPP is monitored by solder paste inspector (SPI). If SPP malfunctions due to the printer defects, the SPP produces defective products, and then abnormal patterns are detected by SPI. In this paper, we propose a convolutional recurrent reconstructive network (CRRN), which decomposes the anomaly patterns generated by the printer defects, from SPI data. CRRN learns only normal data and detects anomaly pattern through reconstruction error. CRRN consists of a spatial encoder (S-Encoder), a spatiotemporal encoder and decoder (ST-Encoder-Decoder), and a spatial decoder (S-Decoder). The ST-Encoder-Decoder consists of multiple convolutional spatiotemporal memories (CSTMs) with ST-Attention mechanism. CSTM is developed to extract spatiotemporal patterns efficiently. Additionally, a spatiotemporal attention (ST-Attention) mechanism is designed to facilitate transmitting information from the ST-Encoder to the ST-Decoder, which can solve the long-term dependency problem. We demonstrate the proposed CRRN outperforms the other conventional models in anomaly detection. Moreover, we show the discriminative power of the anomaly map decomposed by the proposed CRRN through the printer defect classification.