 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tutorial on Independent Component Analysis
Apr 11, 2014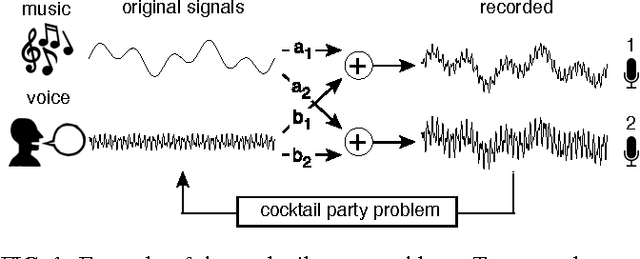

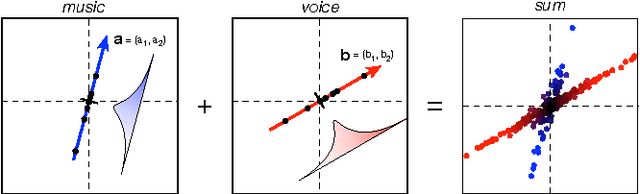
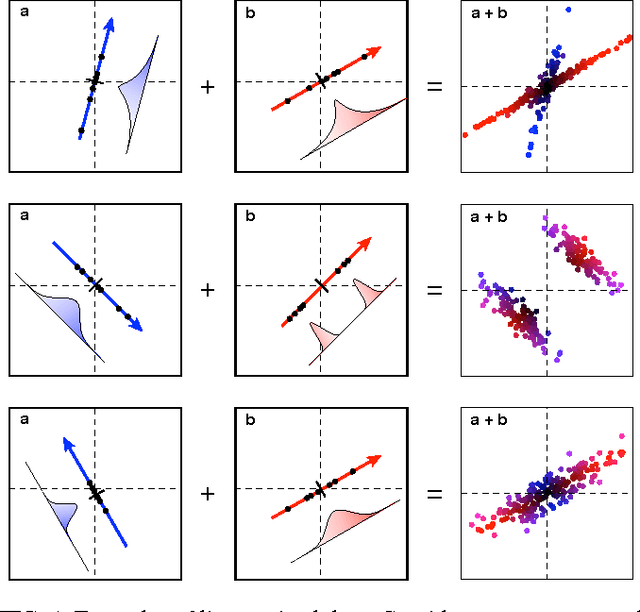
Independent component analysis (ICA) has become a standard data analysis technique applied to an array of problems in signal processing and machine learning. This tutorial provides an introduction to ICA based on linear algebra formulating an intuition for ICA from first principles. The goal of this tutorial is to provide a solid foundation on this advanced topic so that one might learn the motivation behind ICA, learn why and when to apply this technique and in the process gain an introduction to this exciting field of active research.
Notes on Generalized Linear Models of Neurons
Apr 08, 2014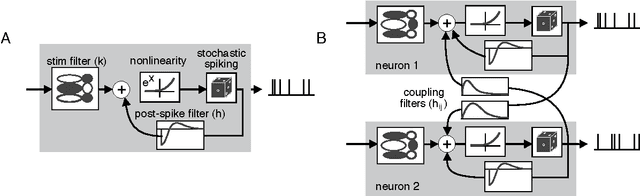
Experimental neuroscience increasingly requires tractable models for analyzing and predicting the behavior of neurons and networks. The generalized linear model (GLM) is an increasingly popular statistical framework for analyzing neural data that is flexible, exhibits rich dynamic behavior and is computationally tractable (Paninski, 2004; Pillow et al., 2008; Truccolo et al., 2005). What follows is a brief summary of the primary equations governing the application of GLM's to spike trains with a few sentences linking this work to the larger statistical literature. Latter sections include extensions of a basic GLM to model spatio-temporal receptive fields as well as network activity in an arbitrary numbers of neurons.
A Tutorial on Principal Component Analysis
Apr 03, 2014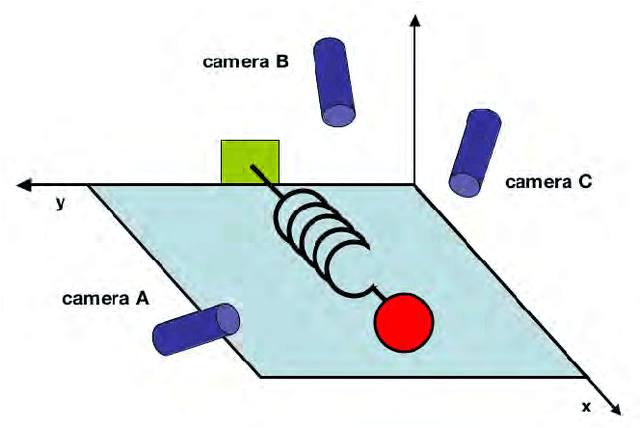
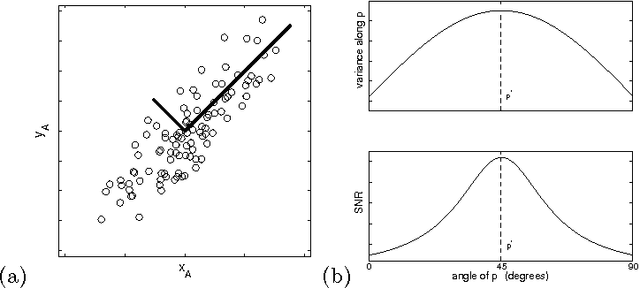
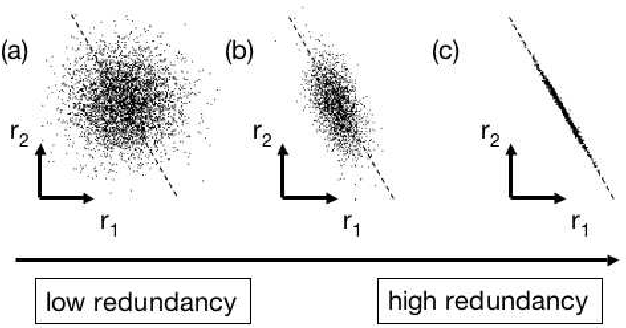
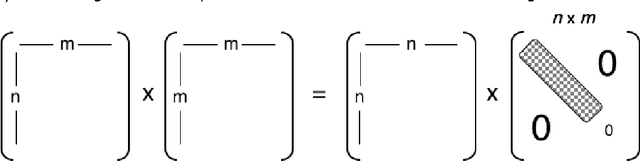
Principal component analysis (PCA) is a mainstay of modern data analysis - a black box that is widely used but (sometimes) poorly understood. The goal of this paper is to dispel the magic behind this black box. This manuscript focuses on building a solid intuition for how and why principal component analysis works. This manuscript crystallizes this knowledge by deriving from simple intuitions, the mathematics behind PCA. This tutorial does not shy away from explaining the ideas informally, nor does it shy away from the mathematics. The hope is that by addressing both aspects, readers of all levels will be able to gain a better understanding of PCA as well as the when, the how and the why of applying this technique.
Zero-Shot Learning by Convex Combination of Semantic Embeddings
Mar 21, 2014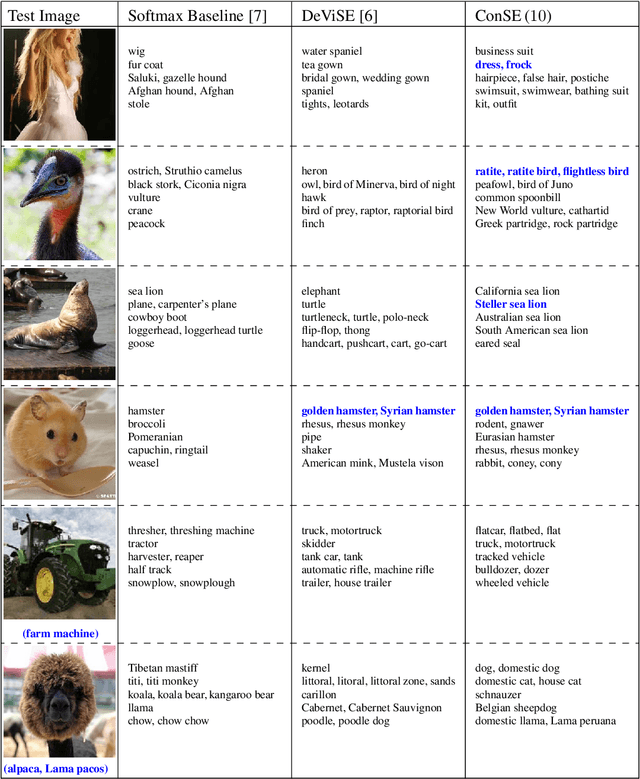
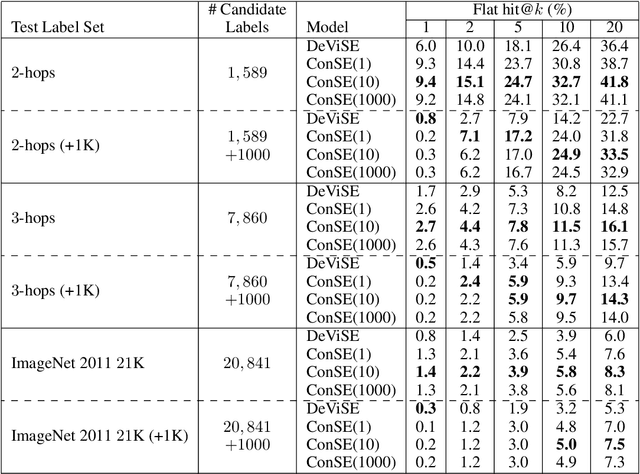
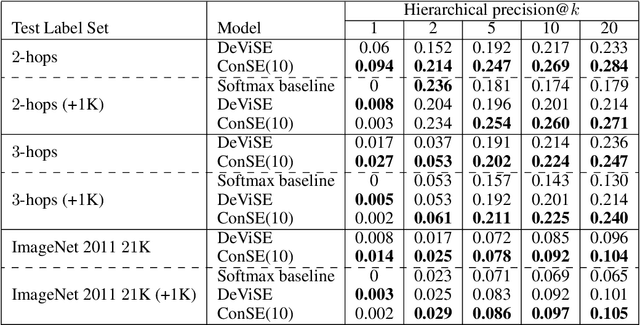
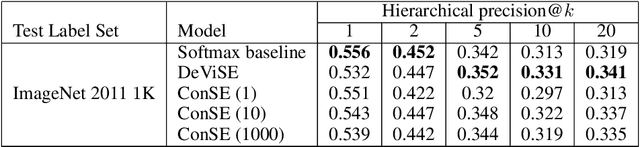
Several recent publications have proposed methods for mapping images into continuous semantic embedding spaces. In some cases the embedding space is trained jointly with the image transformation. In other cases the semantic embedding space is established by an independent natural language processing task, and then the image transformation into that space is learned in a second stage. Proponents of these image embedding systems have stressed their advantages over the traditional \nway{} classification framing of image understanding, particularly in terms of the promise for zero-shot learning -- the ability to correctly annotate images of previously unseen object categories. In this paper, we propose a simple method for constructing an image embedding system from any existing \nway{} image classifier and a semantic word embedding model, which contains the $\n$ class labels in its vocabulary. Our method maps images into the semantic embedding space via convex combination of the class label embedding vectors, and requires no additional training. We show that this simple and direct method confers many of the advantages associated with more complex image embedding schemes, and indeed outperforms state of the art methods on the ImageNet zero-shot learning task.
Using Web Co-occurrence Statistics for Improving Image Categorization
Dec 20, 2013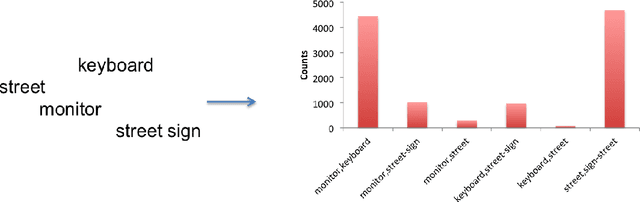
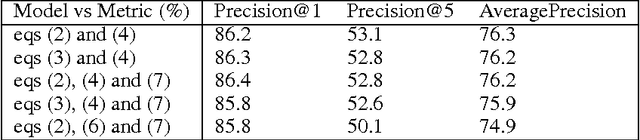
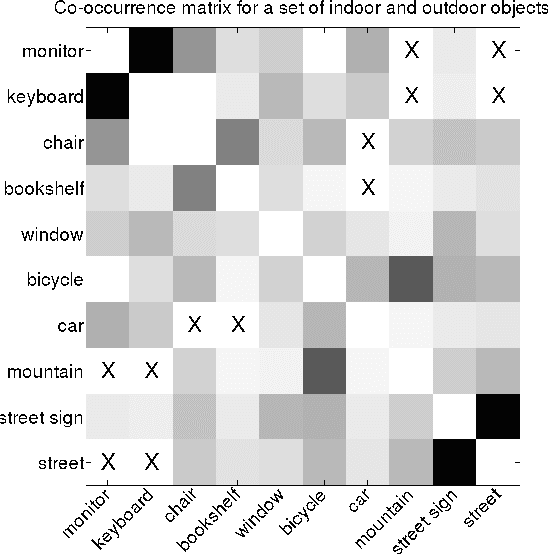

Object recognition and localization are important tasks in computer vision. The focus of this work is the incorporation of contextual information in order to improve object recognition and localization. For instance, it is natural to expect not to see an elephant to appear in the middle of an ocean. We consider a simple approach to encapsulate such common sense knowledge using co-occurrence statistics from web documents. By merely counting the number of times nouns (such as elephants, sharks, oceans, etc.) co-occur in web documents, we obtain a good estimate of expected co-occurrences in visual data. We then cast the problem of combining textual co-occurrence statistics with the predictions of image-based classifiers as an optimization problem. The resulting optimization problem serves as a surrogate for our inference procedure. Albeit the simplicity of the resulting optimization problem, it is effective in improving both recognition and localization accuracy. Concretely, we observe significant improvements in recognition and localization rates for both ImageNet Detection 2012 and Sun 2012 datasets.