 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAUX: a Density-based Approach for Uncertainty eXplanations
Jul 11, 2022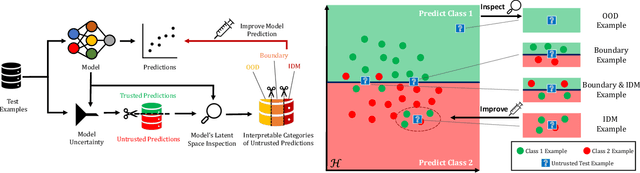
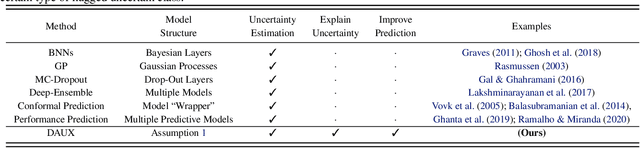
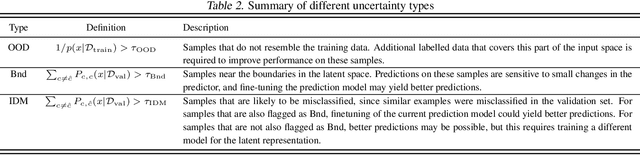

Uncertainty quantification (UQ) is essential for creating trustworthy machine learning models. Recent years have seen a steep rise in UQ methods that can flag suspicious examples, however, it is often unclear what exactly these methods identify. In this work, we propose an assumption-light method for interpreting UQ models themselves. We introduce the confusion density matrix -- a kernel-based approximation of the misclassification density -- and use this to categorize suspicious examples identified by a given UQ method into three classes: out-of-distribution (OOD) examples, boundary (Bnd) examples, and examples in regions of high in-distribution misclassification (IDM). Through extensive experiments, we shed light on existing UQ methods and show that the cause of the uncertainty differs across models. Additionally, we show how the proposed framework can make use of the categorized examples to improve predictive performance.