 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Uncertainty Measures of Automatic Speech Recognition for Non-intrusive Speech Intelligibility Prediction
Apr 08, 2022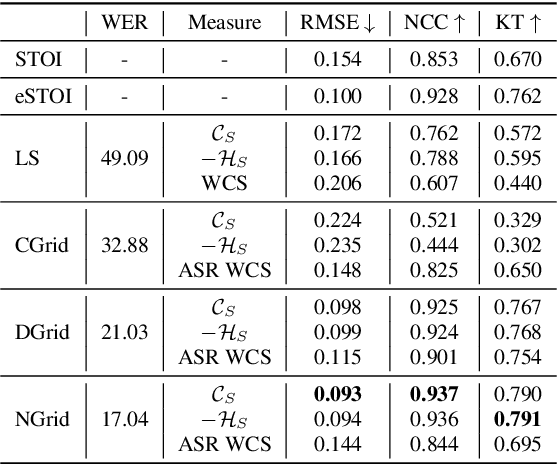
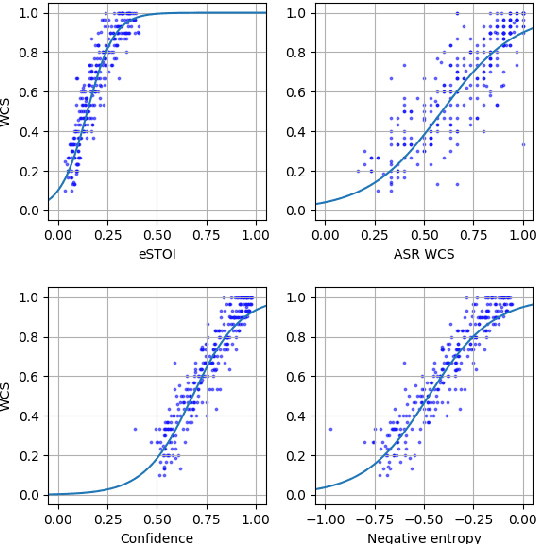
Non-intrusive intelligibility prediction is important for its application in realistic scenarios, where a clean reference signal is difficult to access. The construction of many non-intrusive predictors require either ground truth intelligibility labels or clean reference signals for supervised learning. In this work, we leverage an unsupervised uncertainty estimation method for predicting speech intelligibility, which does not require intelligibility labels or reference signals to train the predictor. Our experiments demonstrate that the uncertainty from state-of-the-art end-to-end automatic speech recognition (ASR) models is highly correlated with speech intelligibility. The proposed method is evaluated on two databases and the results show that the unsupervised uncertainty measures of ASR models are more correlated with speech intelligibility from listening results than the predictions made by widely used intrusive methods.
Exploiting Hidden Representations from a DNN-based Speech Recogniser for Speech Intelligibility Prediction in Hearing-impaired Listeners
Apr 08, 2022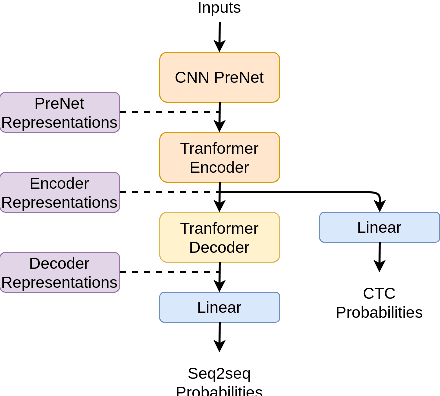
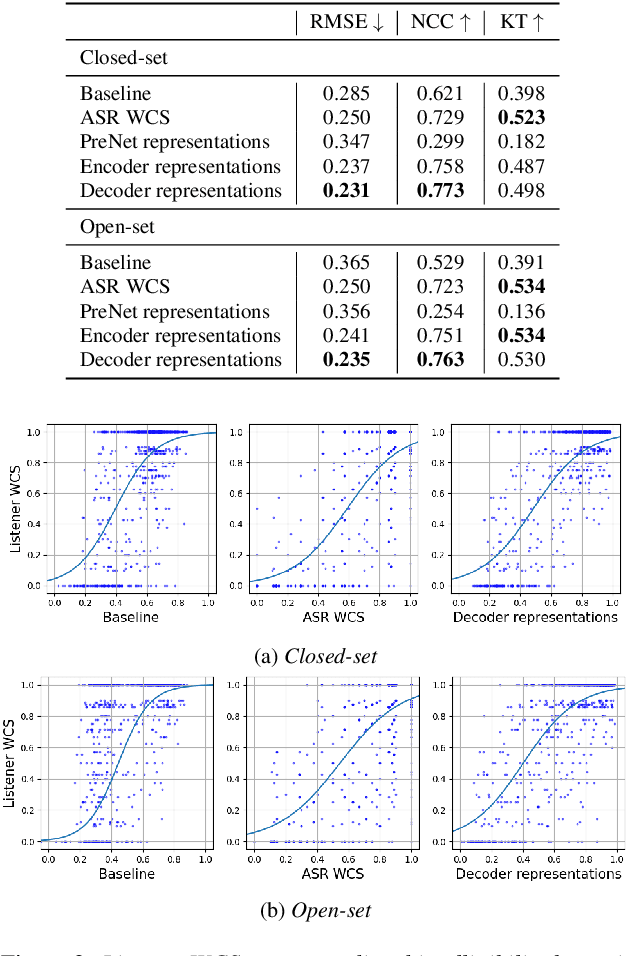
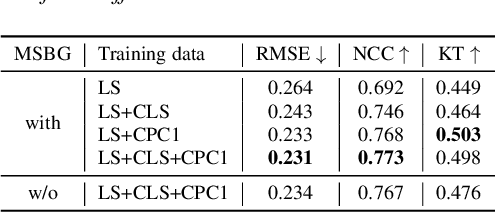
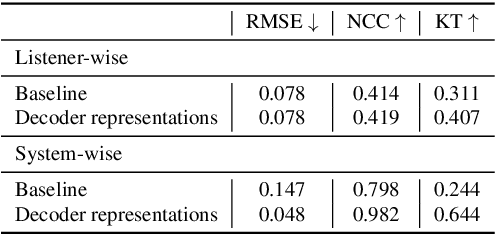
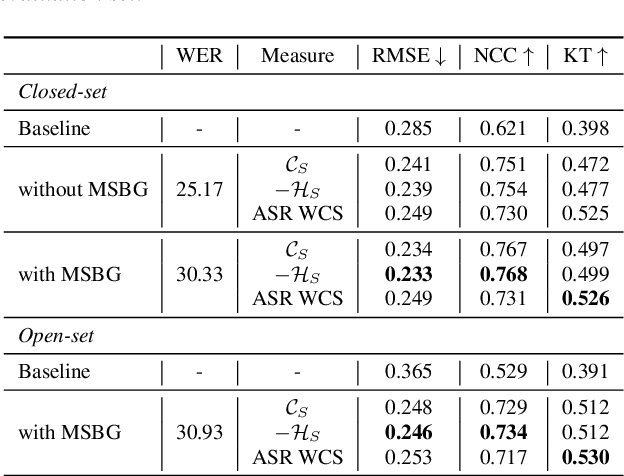
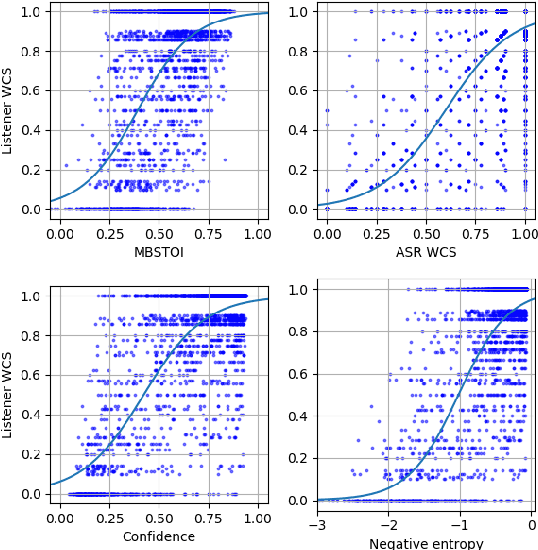
An accurate objective speech intelligibility prediction algorithms is of great interest for many applications such as speech enhancement for hearing aids. Most algorithms measures the signal-to-noise ratios or correlations between the acoustic features of clean reference signals and degraded signals. However, these hand-picked acoustic features are usually not explicitly correlated with recognition. Meanwhile, deep neural network (DNN) based automatic speech recogniser (ASR) is approaching human performance in some speech recognition tasks. This work leverages the hidden representations from DNN-based ASR as features for speech intelligibility prediction in hearing-impaired listeners. The experiments based on a hearing aid intelligibility database show that the proposed method could make better prediction than a widely used short-time objective intelligibility (STOI) based binaural measure.
Auditory-Based Data Augmentation for End-to-End Automatic Speech Recognition
Apr 08, 2022

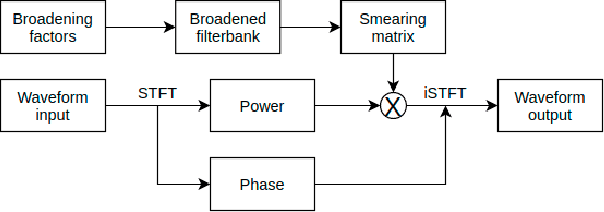
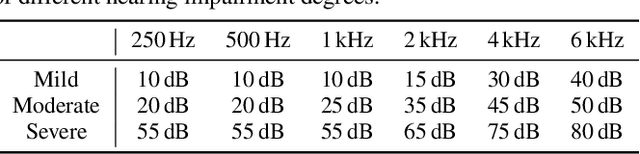
End-to-end models have achieved significant improvement on automatic speech recognition. One common method to improve performance of these models is expanding the data-space through data augmentation. Meanwhile, human auditory inspired front-ends have also demonstrated improvement for automatic speech recognisers. In this work, a well-verified auditory-based model, which can simulate various hearing abilities, is investigated for the purpose of data augmentation for end-to-end speech recognition. By introducing the auditory model into the data augmentation process, end-to-end systems are encouraged to ignore variation from the signal that cannot be heard and thereby focus on robust features for speech recognition. Two mechanisms in the auditory model, spectral smearing and loudness recruitment, are studied on the LibriSpeech dataset with a transformer-based end-to-end model. The results show that the proposed augmentation methods can bring statistically significant improvement on the performance of the state-of-the-art SpecAugment.
Leveraging Bitstream Metadata for Fast and Accurate Video Compression Correction
Jan 31, 2022Video compression is a central feature of the modern internet powering technologies from social media to video conferencing. While video compression continues to mature, for many, and particularly for extreme, compression settings, quality loss is still noticeable. These extreme settings nevertheless have important applications to the efficient transmission of videos over bandwidth constrained or otherwise unstable connections. In this work, we develop a deep learning architecture capable of restoring detail to compressed videos which leverages the underlying structure and motion information embedded in the video bitstream. We show that this improves restoration accuracy compared to prior compression correction methods and is competitive when compared with recent deep-learning-based video compression methods on rate-distortion while achieving higher throughput.
Teacher-Student MixIT for Unsupervised and Semi-supervised Speech Separation
Jun 16, 2021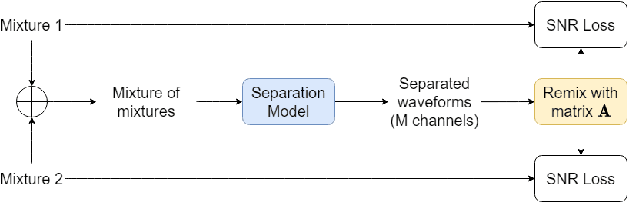
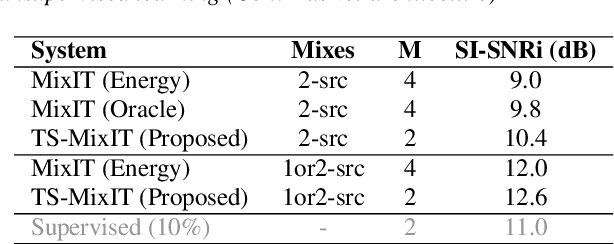
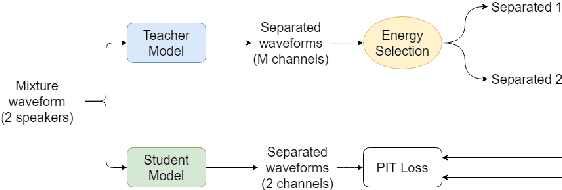
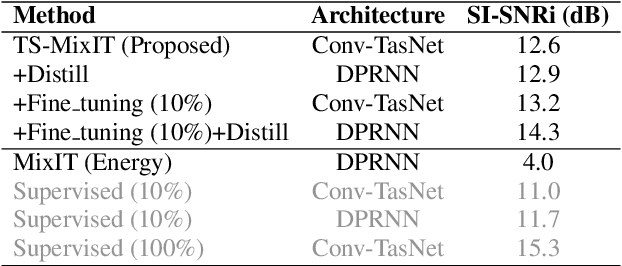
In this paper, we introduce a novel semi-supervised learning framework for end-to-end speech separation. The proposed method first uses mixtures of unseparated sources and the mixture invariant training (MixIT) criterion to train a teacher model. The teacher model then estimates separated sources that are used to train a student model with standard permutation invariant training (PIT). The student model can be fine-tuned with supervised data, i.e., paired artificial mixtures and clean speech sources, and further improved via model distillation. Experiments with single and multi channel mixtures show that the teacher-student training resolves the over-separation problem observed in the original MixIT method. Further, the semisupervised performance is comparable to a fully-supervised separation system trained using ten times the amount of supervised data.
Optimising Hearing Aid Fittings for Speech in Noise with a Differentiable Hearing Loss Model
Jun 08, 2021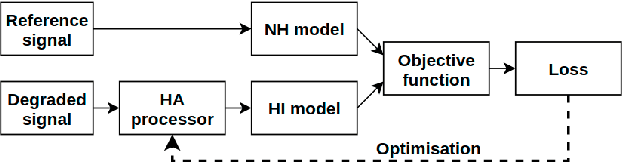
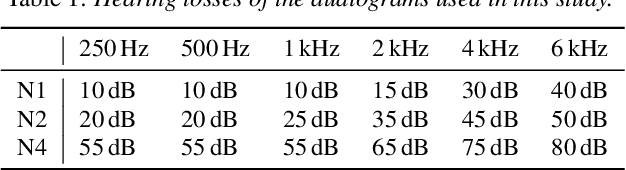
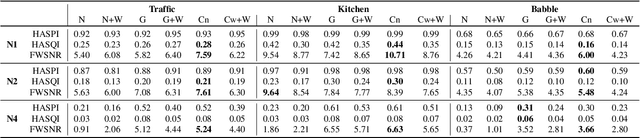
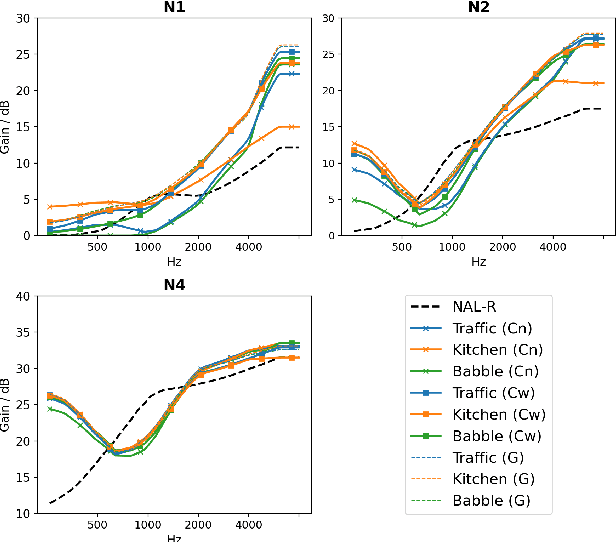
Current hearing aids normally provide amplification based on a general prescriptive fitting, and the benefits provided by the hearing aids vary among different listening environments despite the inclusion of noise suppression feature. Motivated by this fact, this paper proposes a data-driven machine learning technique to develop hearing aid fittings that are customised to speech in different noisy environments. A differentiable hearing loss model is proposed and used to optimise fittings with back-propagation. The customisation is reflected on the data of speech in different noise with also the consideration of noise suppression. The objective evaluation shows the advantages of optimised custom fittings over general prescriptive fittings.
DHASP: Differentiable Hearing Aid Speech Processing
Mar 15, 2021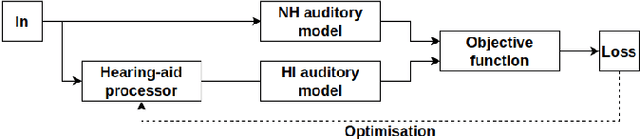

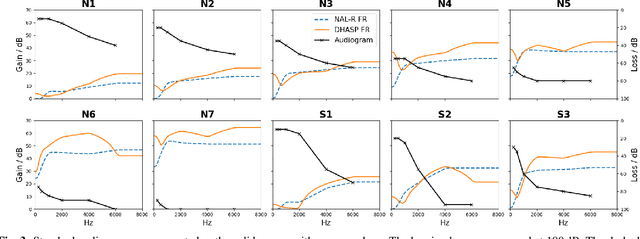
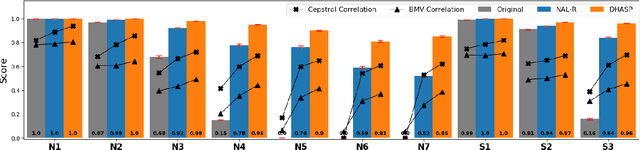
Hearing aids are expected to improve speech intelligibility for listeners with hearing impairment. An appropriate amplification fitting tuned for the listener's hearing disability is critical for good performance. The developments of most prescriptive fittings are based on data collected in subjective listening experiments, which are usually expensive and time-consuming. In this paper, we explore an alternative approach to finding the optimal fitting by introducing a hearing aid speech processing framework, in which the fitting is optimised in an automated way using an intelligibility objective function based on the HASPI physiological auditory model. The framework is fully differentiable, thus can employ the back-propagation algorithm for efficient, data-driven optimisation. Our initial objective experiments show promising results for noise-free speech amplification, where the automatically optimised processors outperform one of the well recognised hearing aid prescriptions.
The Use of Voice Source Features for Sung Speech Recognition
Feb 23, 2021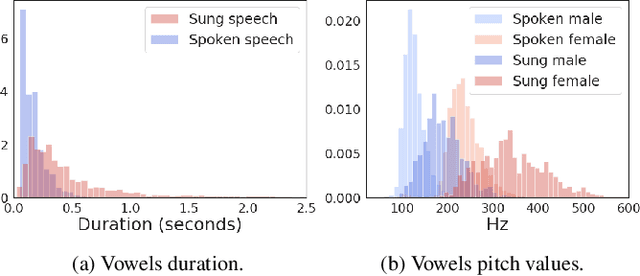
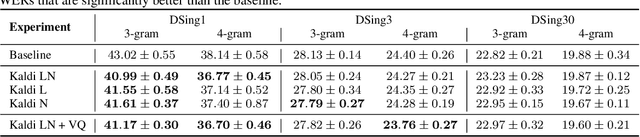
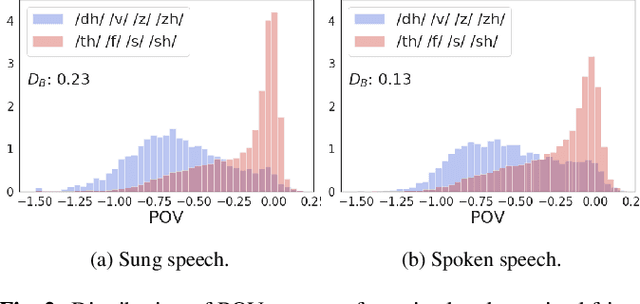
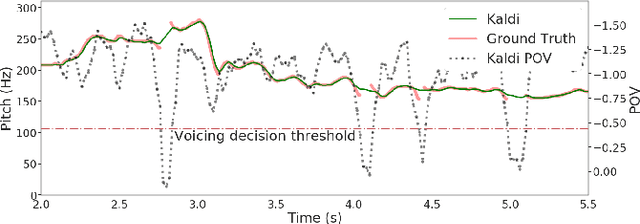
In this paper, we ask whether vocal source features (pitch, shimmer, jitter, etc) can improve the performance of automatic sung speech recognition, arguing that conclusions previously drawn from spoken speech studies may not be valid in the sung speech domain. We first use a parallel singing/speaking corpus (NUS-48E) to illustrate differences in sung vs spoken voicing characteristics including pitch range, syllables duration, vibrato, jitter and shimmer. We then use this analysis to inform speech recognition experiments on the sung speech DSing corpus, using a state of the art acoustic model and augmenting conventional features with various voice source parameters. Experiments are run with three standard (increasingly large) training sets, DSing1 (15.1 hours), DSing3 (44.7 hours) and DSing30 (149.1 hours). Pitch combined with degree of voicing produces a significant decrease in WER from 38.1% to 36.7% when training with DSing1 however smaller decreases in WER observed when training with the larger more varied DSing3 and DSing30 sets were not seen to be statistically significant. Voicing quality characteristics did not improve recognition performance although analysis suggests that they do contribute to an improved discrimination between voiced/unvoiced phoneme pairs.
Time-Domain Speech Extraction with Spatial Information and Multi Speaker Conditioning Mechanism
Feb 07, 2021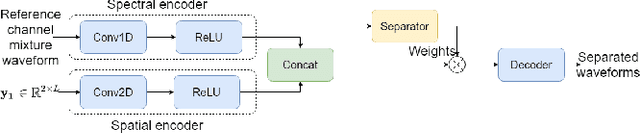
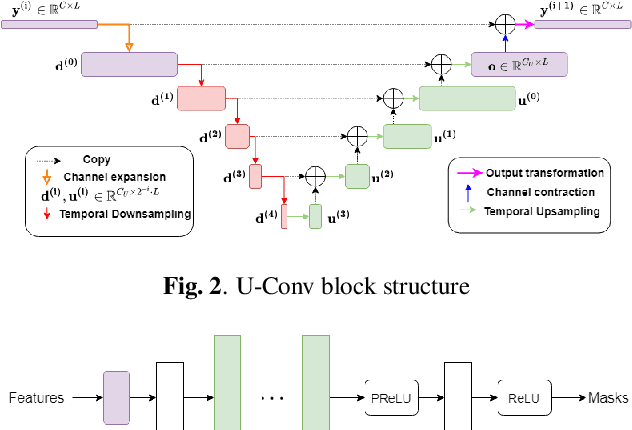
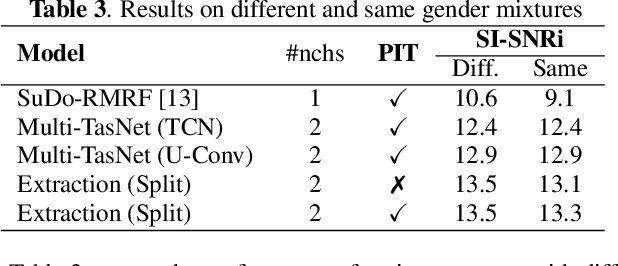

In this paper, we present a novel multi-channel speech extraction system to simultaneously extract multiple clean individual sources from a mixture in noisy and reverberant environments. The proposed method is built on an improved multi-channel time-domain speech separation network which employs speaker embeddings to identify and extract multiple targets without label permutation ambiguity. To efficiently inform the speaker information to the extraction model, we propose a new speaker conditioning mechanism by designing an additional speaker branch for receiving external speaker embeddings. Experiments on 2-channel WHAMR! data show that the proposed system improves by 9% relative the source separation performance over a strong multi-channel baseline, and it increases the speech recognition accuracy by more than 16% relative over the same baseline.
On End-to-end Multi-channel Time Domain Speech Separation in Reverberant Environments
Nov 11, 2020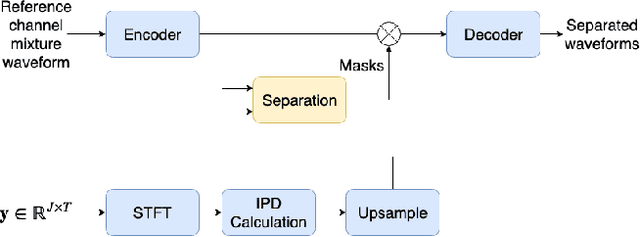

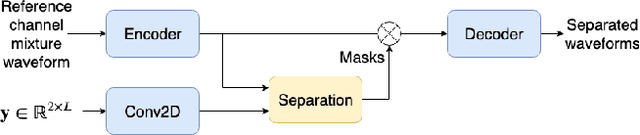
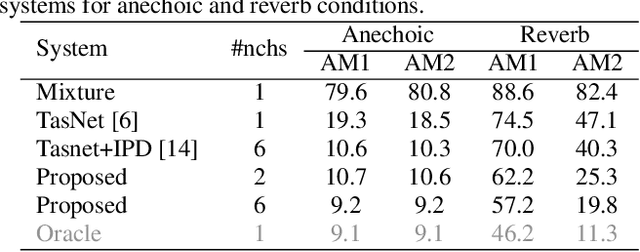
This paper introduces a new method for multi-channel time domain speech separation in reverberant environments. A fully-convolutional neural network structure has been used to directly separate speech from multiple microphone recordings, with no need of conventional spatial feature extraction. To reduce the influence of reverberation on spatial feature extraction, a dereverberation pre-processing method has been applied to further improve the separation performance. A spatialized version of wsj0-2mix dataset has been simulated to evaluate the proposed system. Both source separation and speech recognition performance of the separated signals have been evaluated objectively. Experiments show that the proposed fully-convolutional network improves the source separation metric and the word error rate (WER) by more than 13% and 50% relative, respectively, over a reference system with conventional features. Applying dereverberation as pre-processing to the proposed system can further reduce the WER by 29% relative using an acoustic model trained on clean and reverberated data.
* Presented at IEEE ICASSP 2020