 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Tree-Structured Fusion Model for Single Image Deraining
Nov 21, 2018
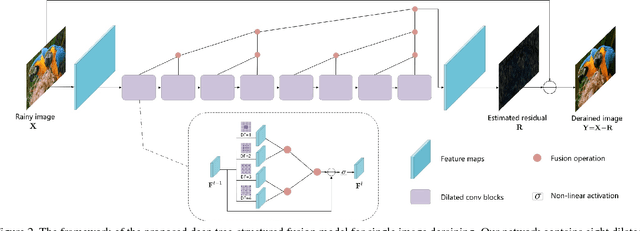
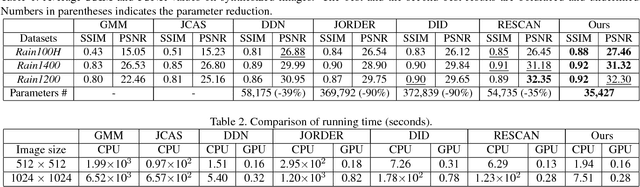
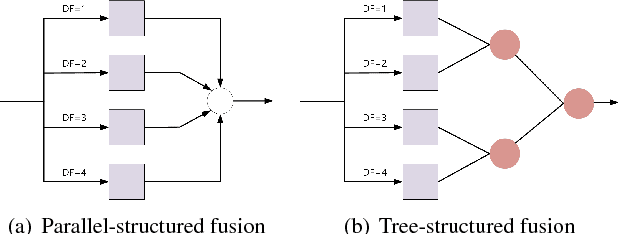
We propose a simple yet effective deep tree-structured fusion model based on feature aggregation for the deraining problem. We argue that by effectively aggregating features, a relatively simple network can still handle tough image deraining problems well. First, to capture the spatial structure of rain we use dilated convolutions as our basic network block. We then design a tree-structured fusion architecture which is deployed within each block (spatial information) and across all blocks (content information). Our method is based on the assumption that adjacent features contain redundant information. This redundancy obstructs generation of new representations and can be reduced by hierarchically fusing adjacent features. Thus, the proposed model is more compact and can effectively use spatial and content information. Experiments on synthetic and real-world datasets show that our network achieves better deraining results with fewer parameters.
Fully Supervised Speaker Diarization
Oct 27, 2018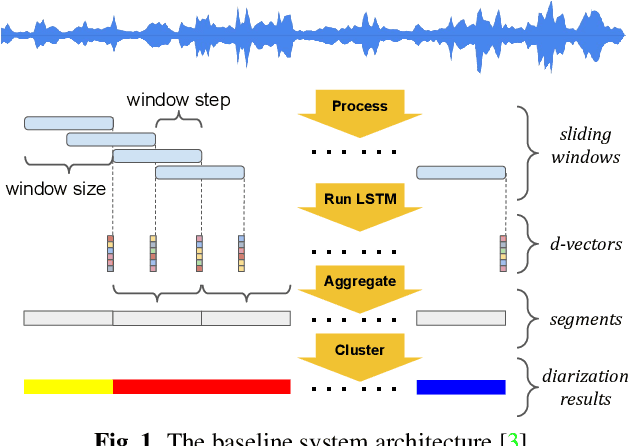
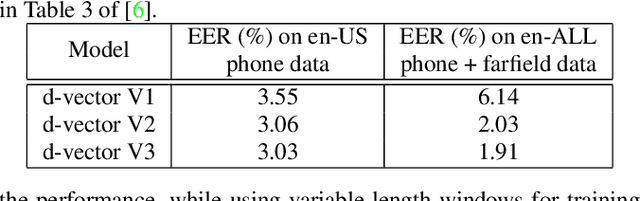
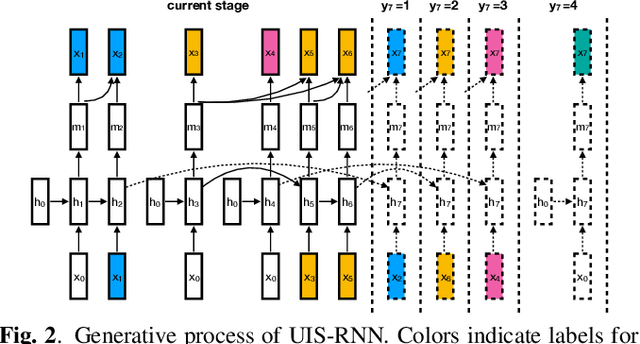
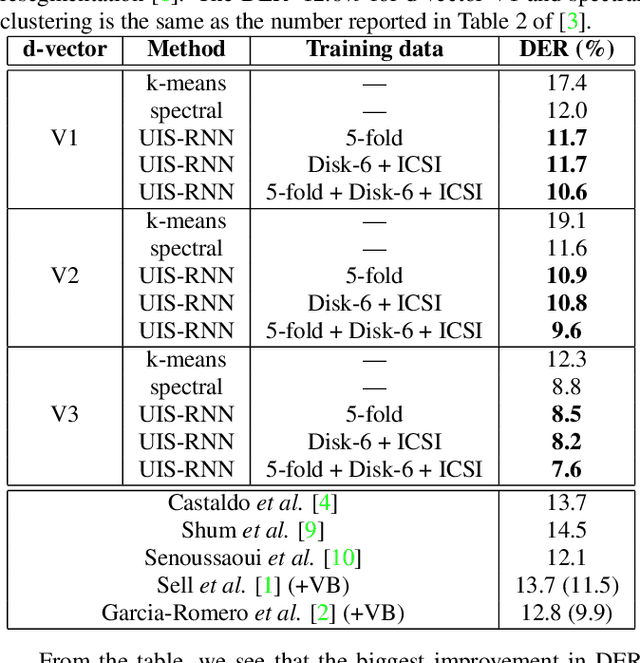
In this paper, we propose a fully supervised speaker diarization approach, named unbounded interleaved-state recurrent neural networks (UIS-RNN). Given extracted speaker-discriminative embeddings (a.k.a. d-vectors) from input utterances, each individual speaker is modeled by a parameter-sharing RNN, while the RNN states for different speakers interleave in the time domain. This RNN is naturally integrated with a distance-dependent Chinese restaurant process (ddCRP) to accommodate an unknown number of speakers. Our system is fully supervised and is able to learn from examples where time-stamped speaker labels are annotated. We achieved a 7.6% diarization error rate on NIST SRE 2000 CALLHOME, which is better than the state-of-the-art method using spectral clustering. Moreover, our method decodes in an online fashion while most state-of-the-art systems rely on offline clustering.
An Adversarial Learning Approach to Medical Image Synthesis for Lesion Removal
Oct 25, 2018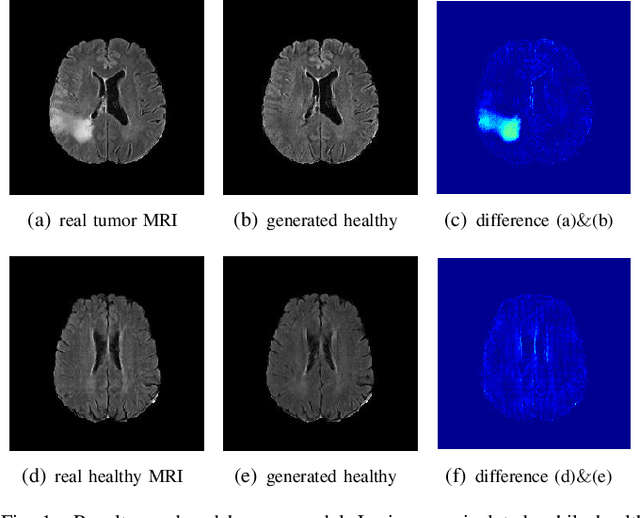
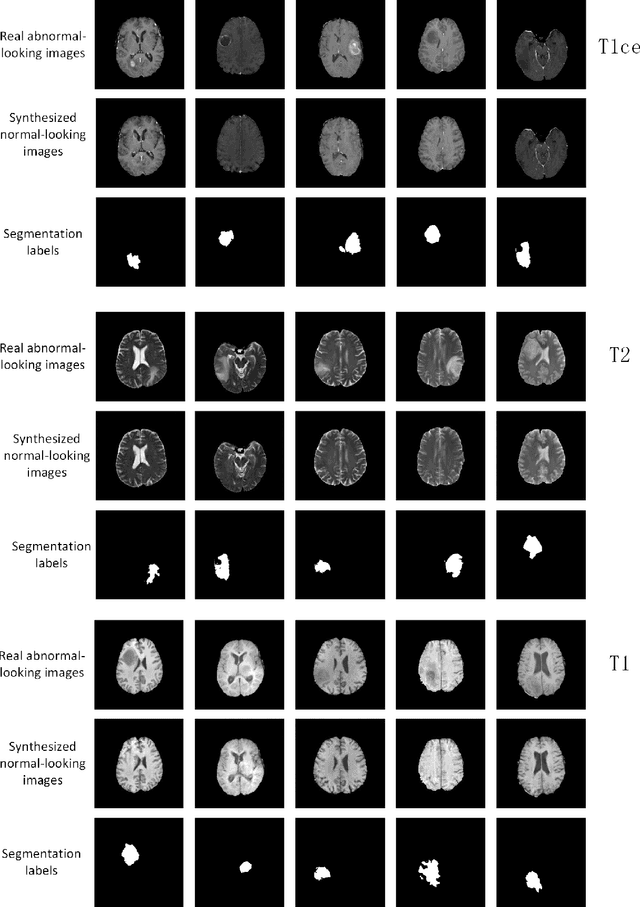
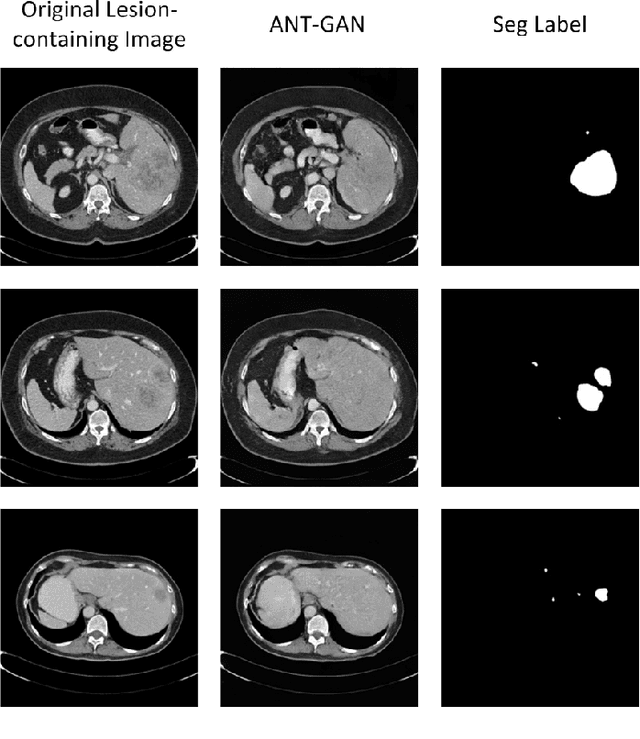
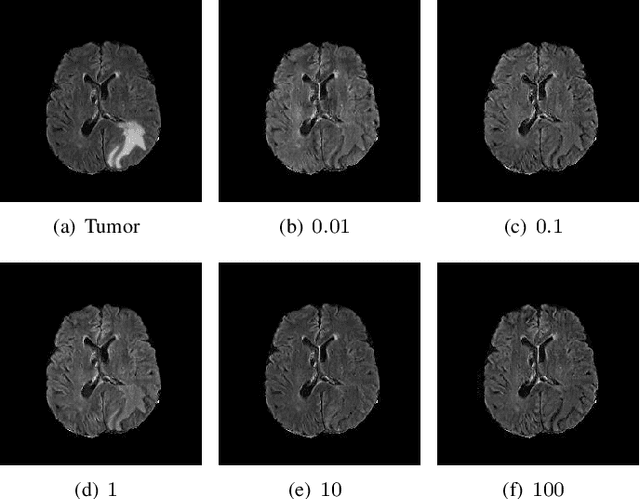
The analysis of lesion within medical image data is desirable for efficient disease diagnosis, treatment and prognosis. The common lesion analysis tasks like segmentation and classification are mainly based on supervised learning with well-paired image-level or voxel-level labels. However, labeling the lesion in medical images is laborious requiring highly specialized knowledge. Inspired by the fact that radiologists make diagnoses based on expert knowledge on "healthiness" and "unhealthiness" developed from extensive experience, we propose an medical image synthesis model named abnormal-to-normal translation generative adversarial network (ANT-GAN) to predict a normal-looking medical image based on its abnormal-looking counterpart without the need of paired data for training. Unlike typical GANs, whose aim is to generate realistic samples with variations, our more restrictive model aims at producing the underlying normal-looking image corresponding to an image containing lesions, and thus requires a specialized design. With an ability to segment normal from abnormal tissue, our model is able to generate a highly realistic lesion-free medical image based on its true lesion-containing counterpart. Being able to provide a "normal" version of a medical image (possibly the same image if there is no illness) is not only an intriguing topic, but also can serve as a pre-processing and provide useful side information for medical imaging tasks like lesion segmentation or classification validated by our experiments.
MBA: Mini-Batch AUC Optimization
May 31, 2018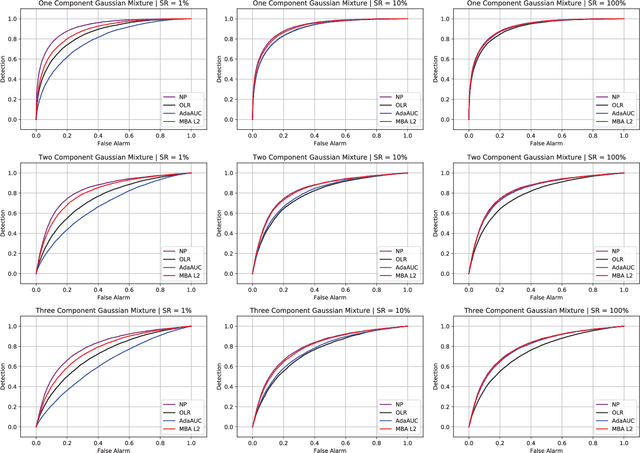
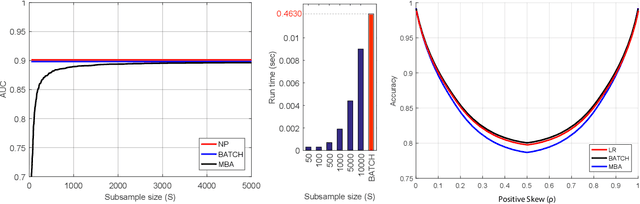
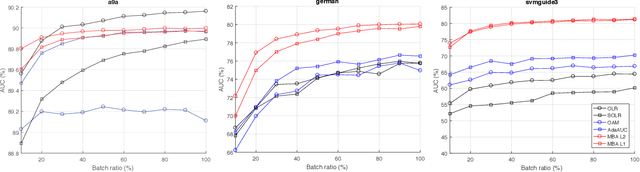
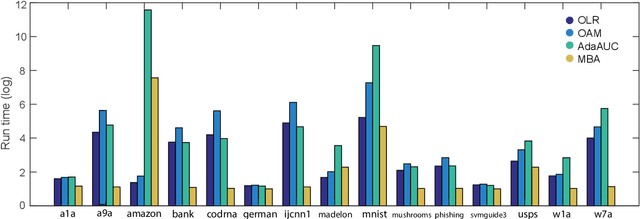
Area under the receiver operating characteristics curve (AUC) is an important metric for a wide range of signal processing and machine learning problems, and scalable methods for optimizing AUC have recently been proposed. However, handling very large datasets remains an open challenge for this problem. This paper proposes a novel approach to AUC maximization, based on sampling mini-batches of positive/negative instance pairs and computing U-statistics to approximate a global risk minimization problem. The resulting algorithm is simple, fast, and learning-rate free. We show that the number of samples required for good performance is independent of the number of pairs available, which is a quadratic function of the positive and negative instances. Extensive experiments show the practical utility of the proposed method.
Lightweight Pyramid Networks for Image Deraining
May 16, 2018
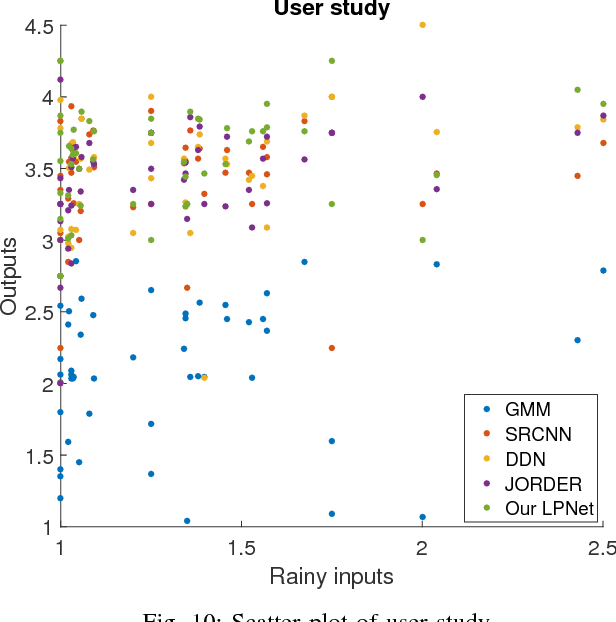

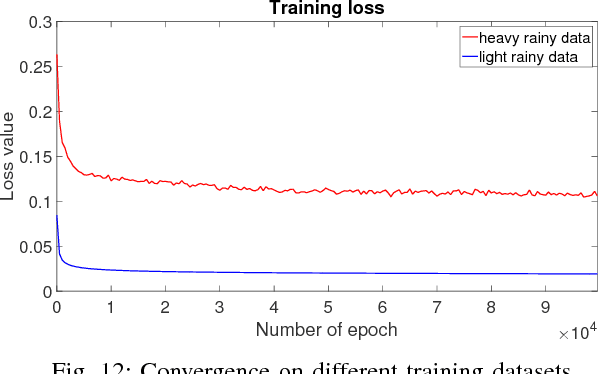
Existing deep convolutional neural networks have found major success in image deraining, but at the expense of an enormous number of parameters. This limits their potential application, for example in mobile devices. In this paper, we propose a lightweight pyramid of networks (LPNet) for single image deraining. Instead of designing a complex network structures, we use domain-specific knowledge to simplify the learning process. Specifically, we find that by introducing the mature Gaussian-Laplacian image pyramid decomposition technology to the neural network, the learning problem at each pyramid level is greatly simplified and can be handled by a relatively shallow network with few parameters. We adopt recursive and residual network structures to build the proposed LPNet, which has less than 8K parameters while still achieving state-of-the-art performance on rain removal. We also discuss the potential value of LPNet for other low- and high-level vision tasks.
MEnet: A Metric Expression Network for Salient Object Segmentation
May 15, 2018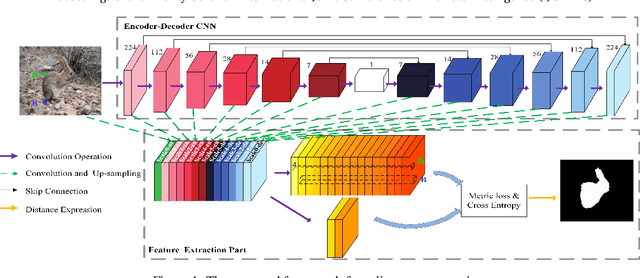
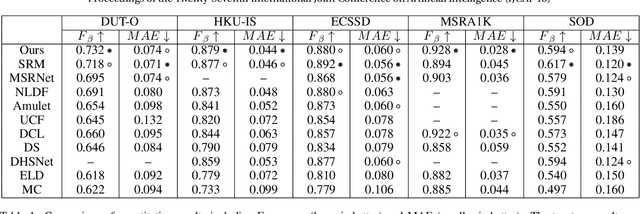
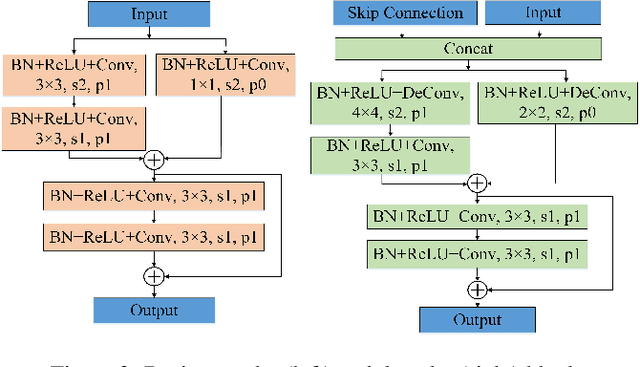
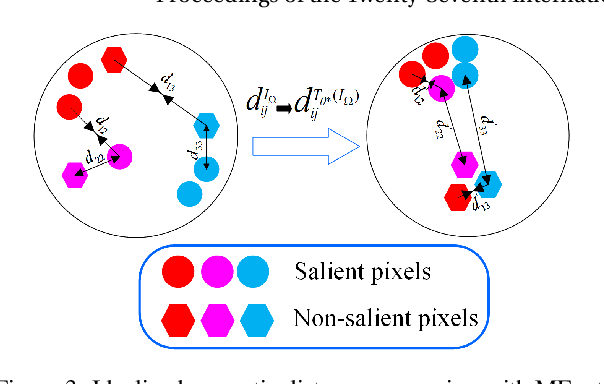
Recent CNN-based saliency models have achieved great performance on public datasets, however, most of them are sensitive to distortion (e.g., noise, compression). In this paper, an end-to-end generic salient object segmentation model called Metric Expression Network (MEnet) is proposed to overcome this drawback. Within this architecture, we construct a new topological metric space, with the implicit metric being determined by the deep network. In this way, we succeed in grouping all the pixels within the observed image semantically within this latent space into two regions: a salient region and a non-salient region. With this method, all feature extractions are carried out at the pixel level, which makes the output boundaries of salient object fine-grained. Experimental results show that the proposed metric can generate robust salient maps that allow for object segmentation. By testing the method on several public benchmarks, we show that the performance of MEnet has achieved good results. Furthermore, the proposed method outperforms previous CNN-based methods on distorted images.
Joint CS-MRI Reconstruction and Segmentation with a Unified Deep Network
May 06, 2018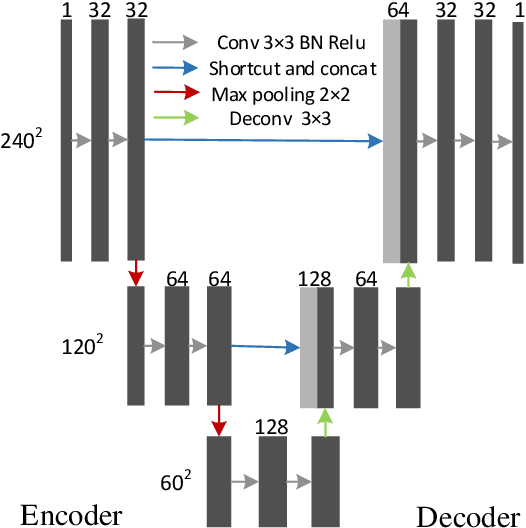
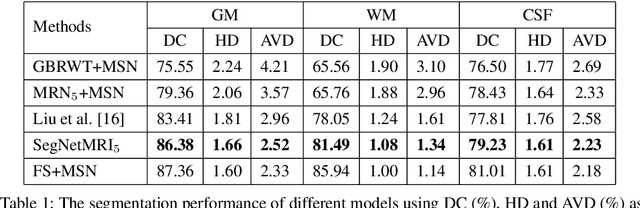
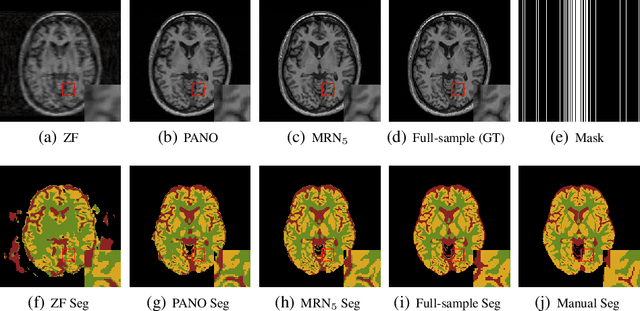
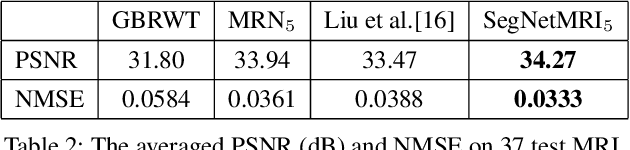
The need for fast acquisition and automatic analysis of MRI data is growing in the age of big data. Although compressed sensing magnetic resonance imaging (CS-MRI) has been studied to accelerate MRI by reducing k-space measurements, in current CS-MRI techniques MRI applications such as segmentation are overlooked when doing image reconstruction. In this paper, we test the utility of CS-MRI methods in automatic segmentation models and propose a unified deep neural network architecture called SegNetMRI which we apply to the combined CS-MRI reconstruction and segmentation problem. SegNetMRI is built upon a MRI reconstruction network with multiple cascaded blocks each containing an encoder-decoder unit and a data fidelity unit, and MRI segmentation networks having the same encoder-decoder structure. The two subnetworks are pre-trained and fine-tuned with shared reconstruction encoders. The outputs are merged into the final segmentation. Our experiments show that SegNetMRI can improve both the reconstruction and segmentation performance when using compressive measurements.
A Deep Information Sharing Network for Multi-contrast Compressed Sensing MRI Reconstruction
Apr 10, 2018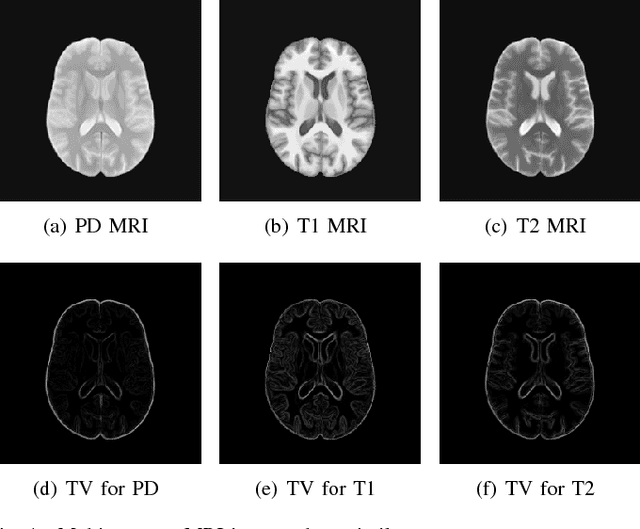
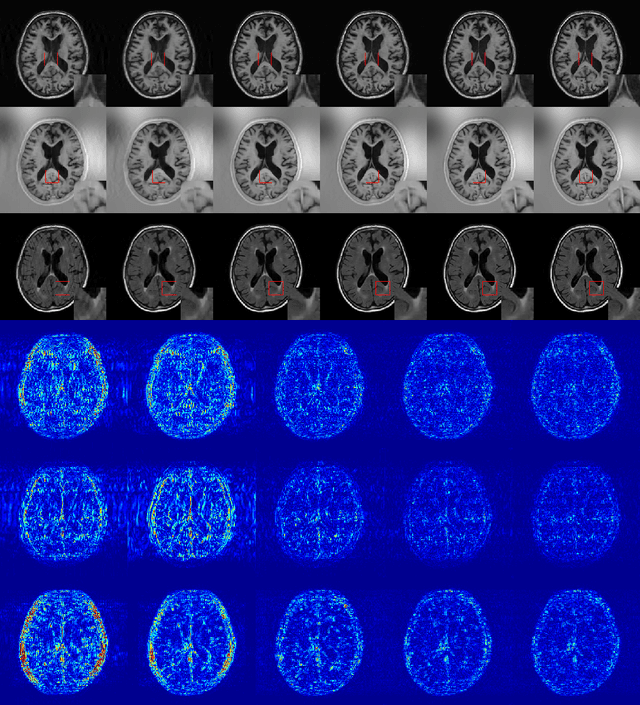
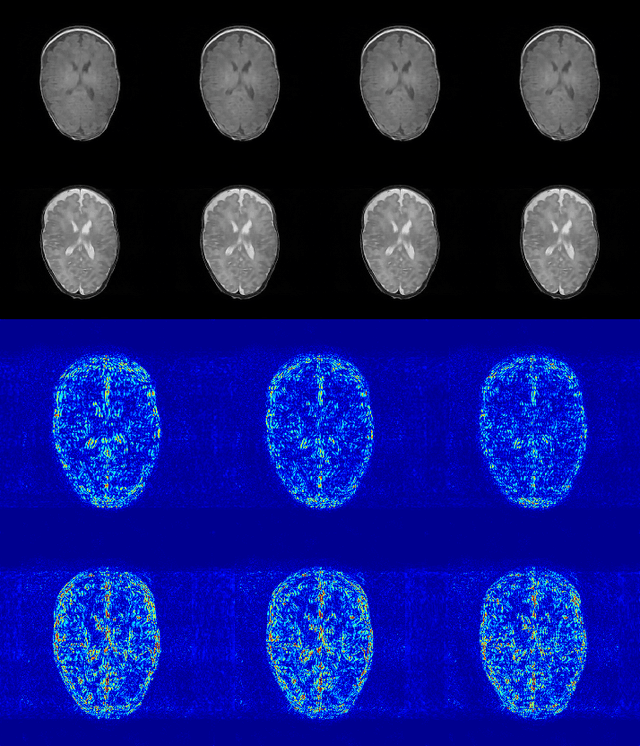
In multi-contrast magnetic resonance imaging (MRI), compressed sensing theory can accelerate imaging by sampling fewer measurements within each contrast. The conventional optimization-based models suffer several limitations: strict assumption of shared sparse support, time-consuming optimization and "shallow" models with difficulties in encoding the rich patterns hiding in massive MRI data. In this paper, we propose the first deep learning model for multi-contrast MRI reconstruction. We achieve information sharing through feature sharing units, which significantly reduces the number of parameters. The feature sharing unit is combined with a data fidelity unit to comprise an inference block. These inference blocks are cascaded with dense connections, which allows for information transmission across different depths of the network efficiently. Our extensive experiments on various multi-contrast MRI datasets show that proposed model outperforms both state-of-the-art single-contrast and multi-contrast MRI methods in accuracy and efficiency. We show the improved reconstruction quality can bring great benefits for the later medical image analysis stage. Furthermore, the robustness of the proposed model to the non-registration environment shows its potential in real MRI applications.
A Segmentation-aware Deep Fusion Network for Compressed Sensing MRI
Apr 04, 2018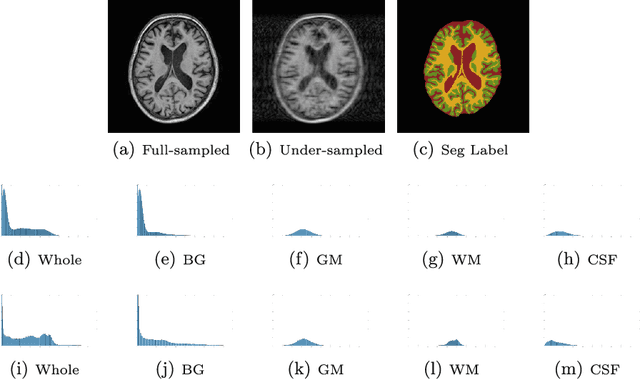
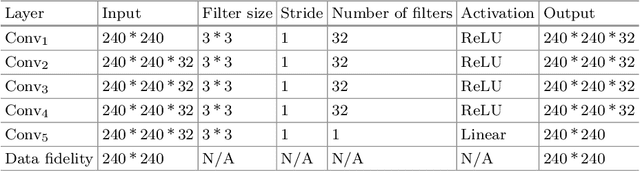
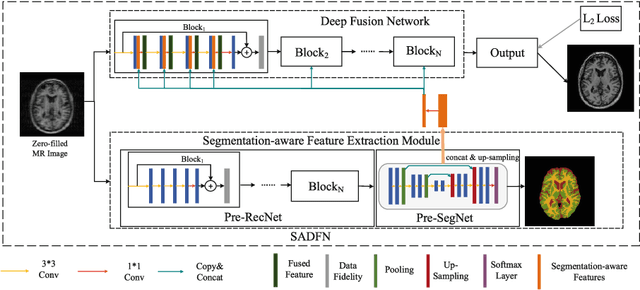
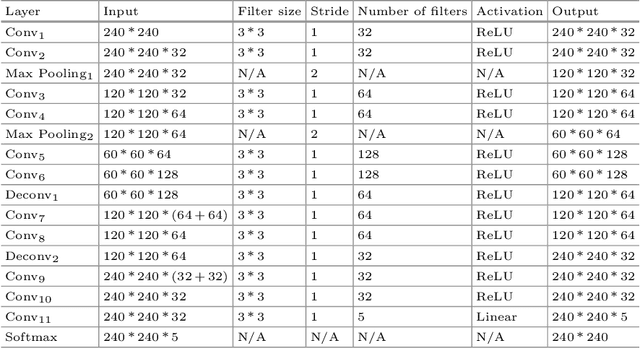
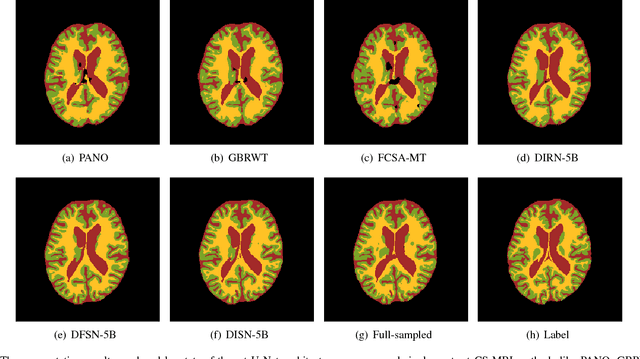
Compressed sensing MRI is a classic inverse problem in the field of computational imaging, accelerating the MR imaging by measuring less k-space data. The deep neural network models provide the stronger representation ability and faster reconstruction compared with "shallow" optimization-based methods. However, in the existing deep-based CS-MRI models, the high-level semantic supervision information from massive segmentation-labels in MRI dataset is overlooked. In this paper, we proposed a segmentation-aware deep fusion network called SADFN for compressed sensing MRI. The multilayer feature aggregation (MLFA) method is introduced here to fuse all the features from different layers in the segmentation network. Then, the aggregated feature maps containing semantic information are provided to each layer in the reconstruction network with a feature fusion strategy. This guarantees the reconstruction network is aware of the different regions in the image it reconstructs, simplifying the function mapping. We prove the utility of the cross-layer and cross-task information fusion strategy by comparative study. Extensive experiments on brain segmentation benchmark MRBrainS validated that the proposed SADFN model achieves state-of-the-art accuracy in compressed sensing MRI. This paper provides a novel approach to guide the low-level visual task using the information from mid- or high-level task.
A Divide-and-Conquer Approach to Compressed Sensing MRI
Mar 27, 2018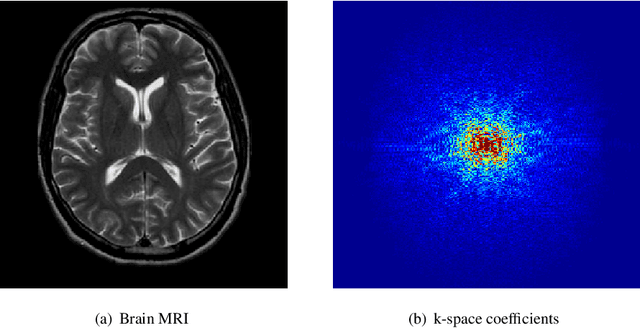
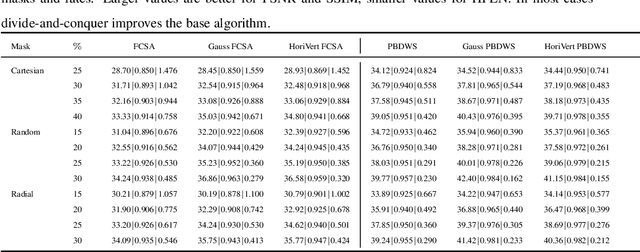
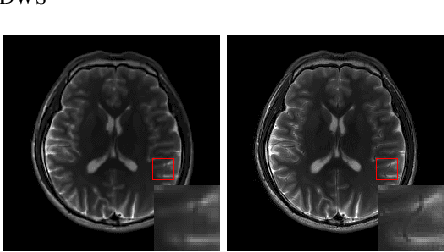
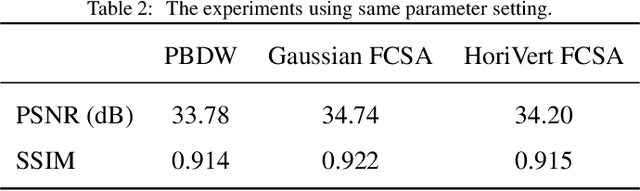
Compressed sensing (CS) theory assures us that we can accurately reconstruct magnetic resonance images using fewer k-space measurements than the Nyquist sampling rate requires. In traditional CS-MRI inversion methods, the fact that the energy within the Fourier measurement domain is distributed non-uniformly is often neglected during reconstruction. As a result, more densely sampled low-frequency information tends to dominate penalization schemes for reconstructing MRI at the expense of high-frequency details. In this paper, we propose a new framework for CS-MRI inversion in which we decompose the observed k-space data into "subspaces" via sets of filters in a lossless way, and reconstruct the images in these various spaces individually using off-the-shelf algorithms. We then fuse the results to obtain the final reconstruction. In this way we are able to focus reconstruction on frequency information within the entire k-space more equally, preserving both high and low frequency details. We demonstrate that the proposed framework is competitive with state-of-the-art methods in CS-MRI in terms of quantitative performance, and often improves an algorithm's results qualitatively compared with it's direct application to k-space.