 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise2Blur: Online Noise Extraction and Denoising
Dec 03, 2019
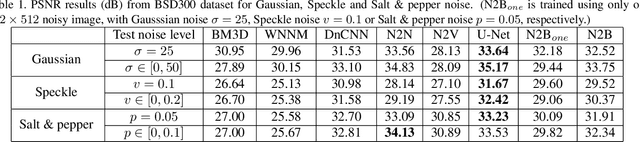
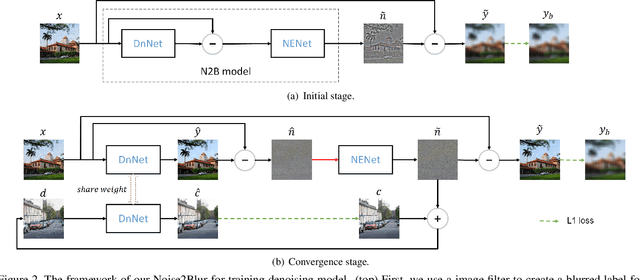
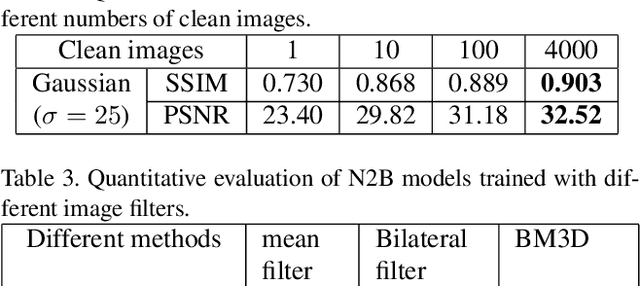
We propose a new framework called Noise2Blur (N2B) for training robust image denoising models without pre-collected paired noisy/clean images. The training of the model requires only some (or even one) noisy images, some random unpaired clean images, and noise-free but blurred labels obtained by predefined filtering of the noisy images. The N2B model consists of two parts: a denoising network and a noise extraction network. First, the noise extraction network learns to output a noise map using the noise information from the denoising network under the guidence of the blurred labels. Then, the noise map is added to a clean image to generate a new ``noisy/clean'' image pair. Using the new image pair, the denoising network learns to generate clean and high-quality images from noisy observations. These two networks are trained simultaneously and mutually aid each other to learn the mappings of noise to clean/blur. Experiments on several denoising tasks show that the denoising performance of N2B is close to that of other denoising CNNs trained with pre-collected paired data.
Risk Bounds for Low Cost Bipartite Ranking
Dec 02, 2019

Bipartite ranking is an important supervised learning problem; however, unlike regression or classification, it has a quadratic dependence on the number of samples. To circumvent the prohibitive sample cost, many recent work focus on stochastic gradient-based methods. In this paper we consider an alternative approach, which leverages the structure of the widely-adopted pairwise squared loss, to obtain a stochastic and low cost algorithm that does not require stochastic gradients or learning rates. Using a novel uniform risk bound---based on matrix and vector concentration inequalities---we show that the sample size required for competitive performance against the all-pairs batch algorithm does not have a quadratic dependence. Generalization bounds for both the batch and low cost stochastic algorithms are presented. Experimental results show significant speed gain against the batch algorithm, as well as competitive performance against state-of-the-art bipartite ranking algorithms on real datasets.
Accurate Uncertainty Estimation and Decomposition in Ensemble Learning
Nov 11, 2019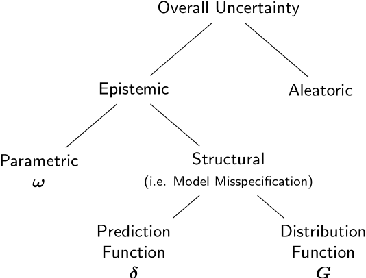
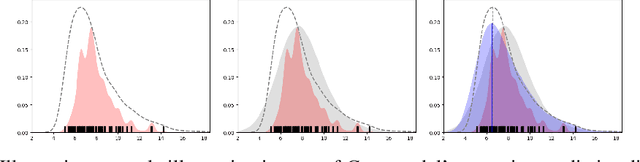
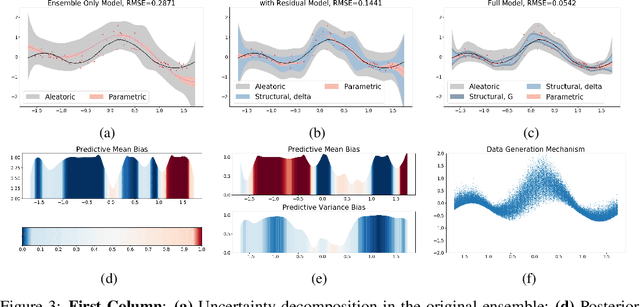
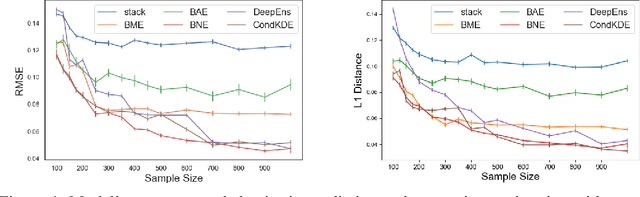
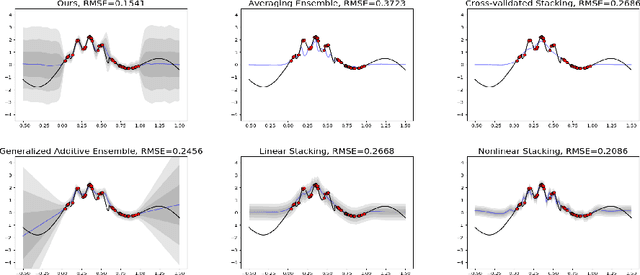
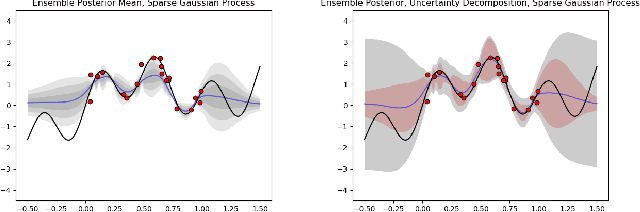
Ensemble learning is a standard approach to building machine learning systems that capture complex phenomena in real-world data. An important aspect of these systems is the complete and valid quantification of model uncertainty. We introduce a Bayesian nonparametric ensemble (BNE) approach that augments an existing ensemble model to account for different sources of model uncertainty. BNE augments a model's prediction and distribution functions using Bayesian nonparametric machinery. It has a theoretical guarantee in that it robustly estimates the uncertainty patterns in the data distribution, and can decompose its overall predictive uncertainty into distinct components that are due to different sources of noise and error. We show that our method achieves accurate uncertainty estimates under complex observational noise, and illustrate its real-world utility in terms of uncertainty decomposition and model bias detection for an ensemble in predict air pollution exposures in Eastern Massachusetts, USA.
Reweighted Expectation Maximization
Jun 13, 2019
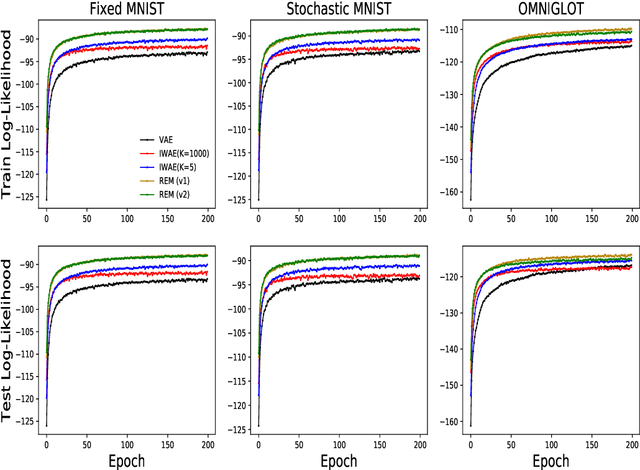
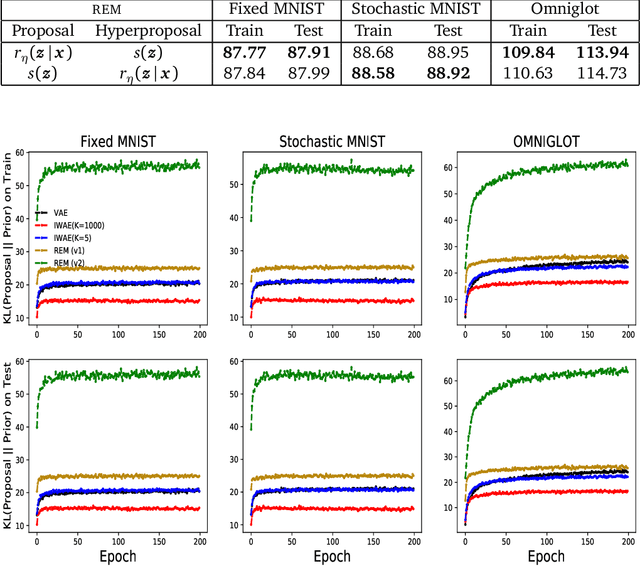
Training deep generative models with maximum likelihood remains a challenge. The typical workaround is to use variational inference (VI) and maximize a lower bound to the log marginal likelihood of the data. Variational auto-encoders (VAEs) adopt this approach. They further amortize the cost of inference by using a recognition network to parameterize the variational family. Amortized VI scales approximate posterior inference in deep generative models to large datasets. However it introduces an amortization gap and leads to approximate posteriors of reduced expressivity due to the problem known as posterior collapse. In this paper, we consider expectation maximization (EM) as a paradigm for fitting deep generative models. Unlike VI, EM directly maximizes the log marginal likelihood of the data. We rediscover the importance weighted auto-encoder (IWAE) as an instance of EM and propose a new EM-based algorithm for fitting deep generative models called reweighted expectation maximization (REM). REM learns better generative models than the IWAE by decoupling the learning dynamics of the generative model and the recognition network using a separate expressive proposal found by moment matching. We compared REM to the VAE and the IWAE on several density estimation benchmarks and found it leads to significantly better performance as measured by log-likelihood.
Random Function Priors for Correlation Modeling
May 13, 2019
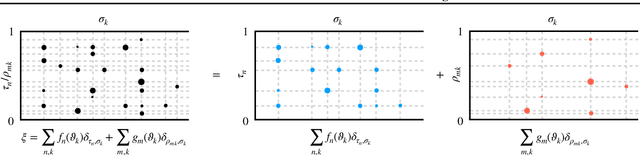
The likelihood model of high dimensional data $X_n$ can often be expressed as $p(X_n|Z_n,\theta)$, where $\theta\mathrel{\mathop:}=(\theta_k)_{k\in[K]}$ is a collection of hidden features shared across objects, indexed by $n$, and $Z_n$ is a non-negative factor loading vector with $K$ entries where $Z_{nk}$ indicates the strength of $\theta_k$ used to express $X_n$. In this paper, we introduce random function priors for $Z_n$ for modeling correlations among its $K$ dimensions $Z_{n1}$ through $Z_{nK}$, which we call \textit{population random measure embedding} (PRME). Our model can be viewed as a generalized paintbox model~\cite{Broderick13} using random functions, and can be learned efficiently with neural networks via amortized variational inference. We derive our Bayesian nonparametric method by applying a representation theorem on separately exchangeable discrete random measures.
Rain O'er Me: Synthesizing real rain to derain with data distillation
Apr 10, 2019

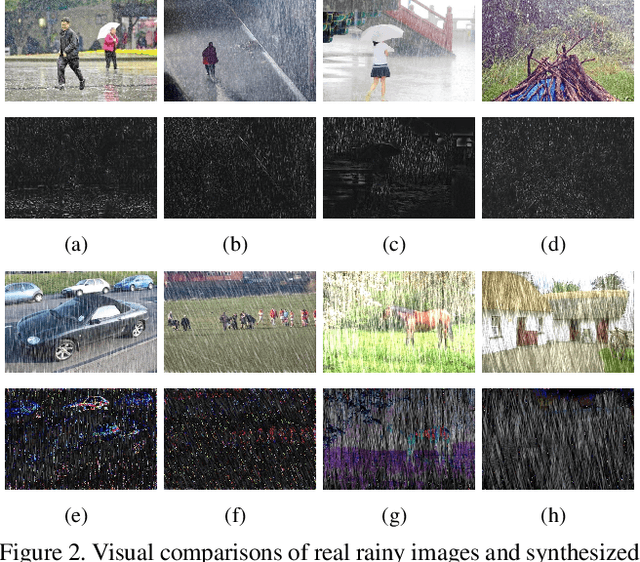
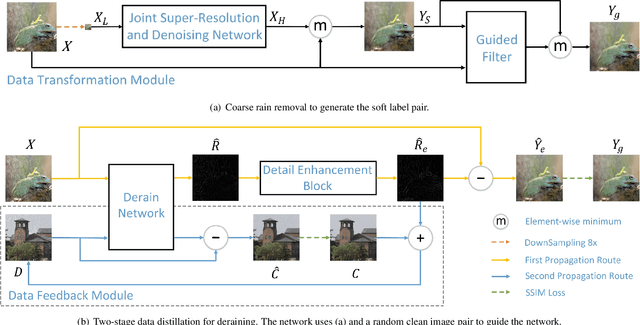
We present a supervised technique for learning to remove rain from images without using synthetic rain software. The method is based on a two-stage data distillation approach: 1) A rainy image is first paired with a coarsely derained version using on a simple filtering technique ("rain-to-clean"). 2) Then a clean image is randomly matched with the rainy soft-labeled pair. Through a shared deep neural network, the rain that is removed from the first image is then added to the clean image to generate a second pair ("clean-to-rain"). The neural network simultaneously learns to map both images such that high resolution structure in the clean images can inform the deraining of the rainy images. Demonstrations show that this approach can address those visual characteristics of rain not easily synthesized by software in the usual way.
Global Explanations of Neural Networks: Mapping the Landscape of Predictions
Feb 06, 2019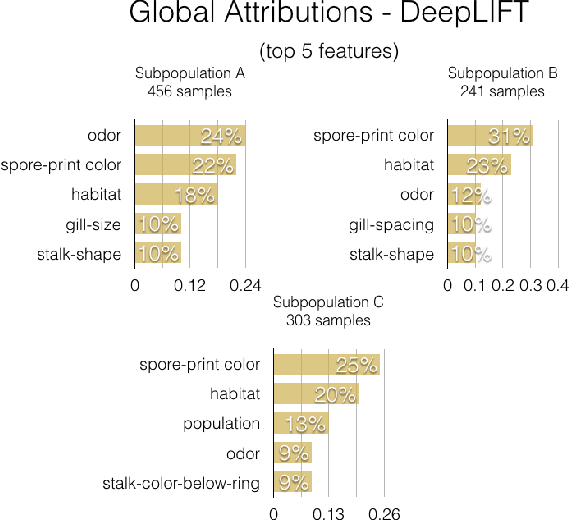
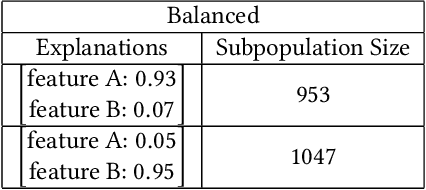
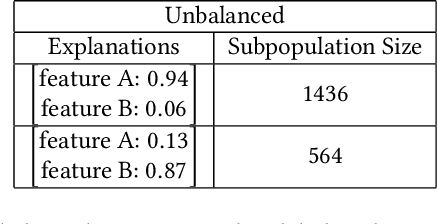
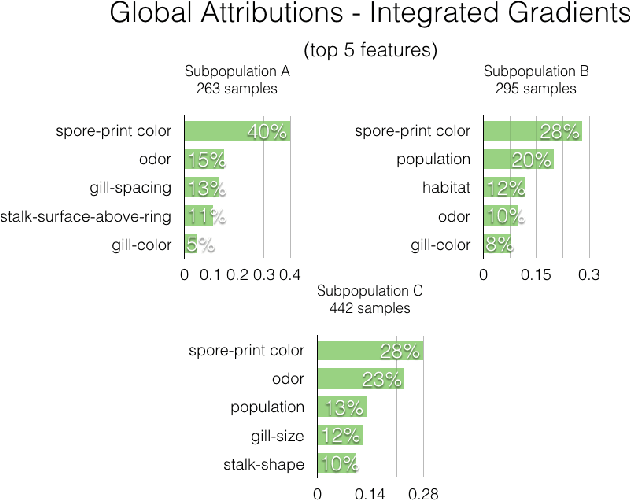
A barrier to the wider adoption of neural networks is their lack of interpretability. While local explanation methods exist for one prediction, most global attributions still reduce neural network decisions to a single set of features. In response, we present an approach for generating global attributions called GAM, which explains the landscape of neural network predictions across subpopulations. GAM augments global explanations with the proportion of samples that each attribution best explains and specifies which samples are described by each attribution. Global explanations also have tunable granularity to detect more or fewer subpopulations. We demonstrate that GAM's global explanations 1) yield the known feature importances of simulated data, 2) match feature weights of interpretable statistical models on real data, and 3) are intuitive to practitioners through user studies. With more transparent predictions, GAM can help ensure neural network decisions are generated for the right reasons.
Mixed Membership Recurrent Neural Networks
Dec 23, 2018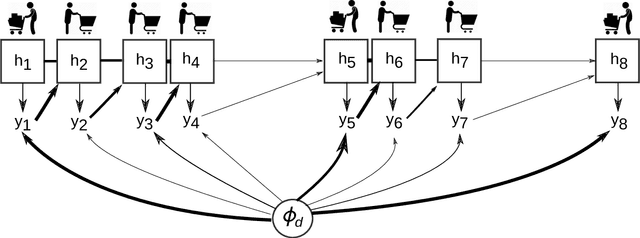
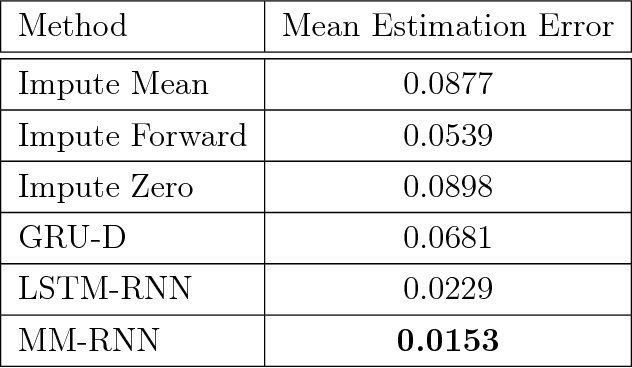
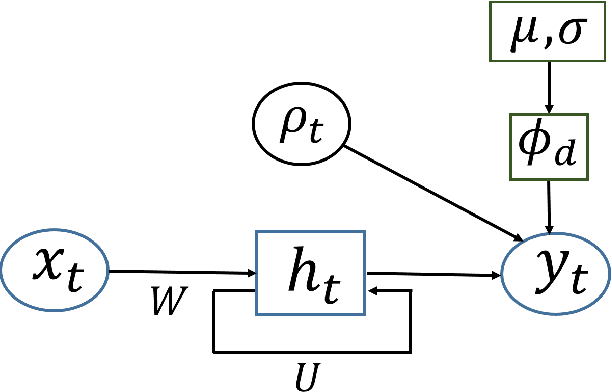
Models for sequential data such as the recurrent neural network (RNN) often implicitly model a sequence as having a fixed time interval between observations and do not account for group-level effects when multiple sequences are observed. We propose a model for grouped sequential data based on the RNN that accounts for varying time intervals between observations in a sequence by learning a group-level base parameter to which each sequence can revert. Our approach is motivated by the mixed membership framework, and we show how it can be used for dynamic topic modeling in which the distribution on topics (not the topics themselves) are evolving in time. We demonstrate our approach on a dataset of 3.4 million online grocery shopping orders made by 206K customers.
Adaptive and Calibrated Ensemble Learning with Dependent Tail-free Process
Dec 19, 2018

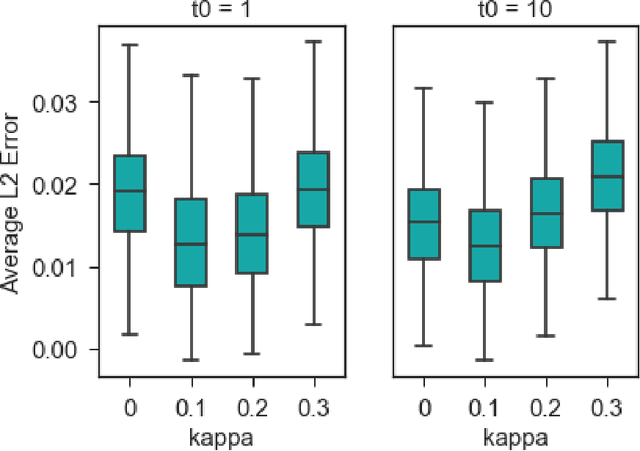
Ensemble learning is a mainstay in modern data science practice. Conventional ensemble algorithms assigns to base models a set of deterministic, constant model weights that (1) do not fully account for variations in base model accuracy across subgroups, nor (2) provide uncertainty estimates for the ensemble prediction, which could result in mis-calibrated (i.e. precise but biased) predictions that could in turn negatively impact the algorithm performance in real-word applications. In this work, we present an adaptive, probabilistic approach to ensemble learning using dependent tail-free process as ensemble weight prior. Given input feature $\mathbf{x}$, our method optimally combines base models based on their predictive accuracy in the feature space $\mathbf{x} \in \mathcal{X}$, and provides interpretable uncertainty estimates both in model selection and in ensemble prediction. To encourage scalable and calibrated inference, we derive a structured variational inference algorithm that jointly minimize KL objective and the model's calibration score (i.e. Continuous Ranked Probability Score (CRPS)). We illustrate the utility of our method on both a synthetic nonlinear function regression task, and on the real-world application of spatio-temporal integration of particle pollution prediction models in New England.
Towards Explainable Deep Learning for Credit Lending: A Case Study
Nov 30, 2018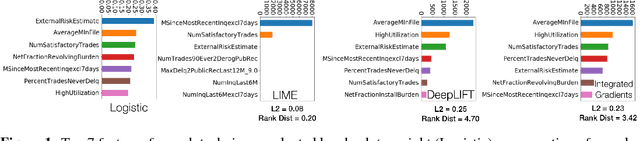

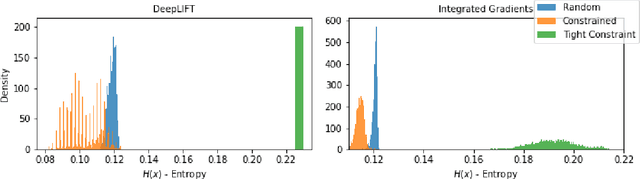
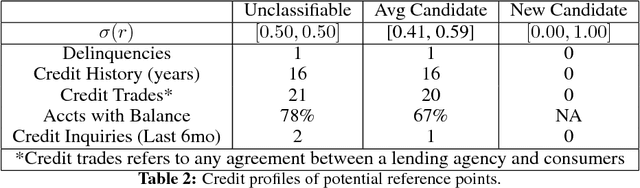
Deep learning adoption in the financial services industry has been limited due to a lack of model interpretability. However, several techniques have been proposed to explain predictions made by a neural network. We provide an initial investigation into these techniques for the assessment of credit risk with neural networks.