 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Deep Learning to Identify Patients with Cognitive Impairment in Electronic Health Records
Nov 13, 2021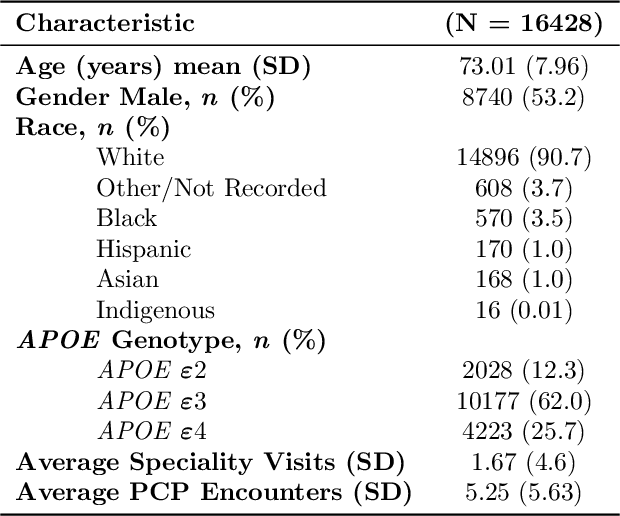



Dementia is a neurodegenerative disorder that causes cognitive decline and affects more than 50 million people worldwide. Dementia is under-diagnosed by healthcare professionals - only one in four people who suffer from dementia are diagnosed. Even when a diagnosis is made, it may not be entered as a structured International Classification of Diseases (ICD) diagnosis code in a patient's charts. Information relevant to cognitive impairment (CI) is often found within electronic health records (EHR), but manual review of clinician notes by experts is both time consuming and often prone to errors. Automated mining of these notes presents an opportunity to label patients with cognitive impairment in EHR data. We developed natural language processing (NLP) tools to identify patients with cognitive impairment and demonstrate that linguistic context enhances performance for the cognitive impairment classification task. We fine-tuned our attention based deep learning model, which can learn from complex language structures, and substantially improved accuracy (0.93) relative to a baseline NLP model (0.84). Further, we show that deep learning NLP can successfully identify dementia patients without dementia-related ICD codes or medications.
Natural Language Processing to Detect Cognitive Concerns in Electronic Health Records Using Deep Learning
Nov 12, 2020
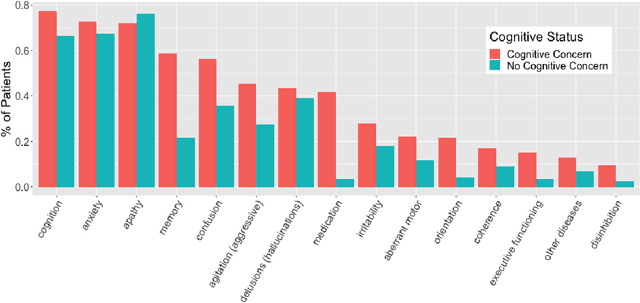

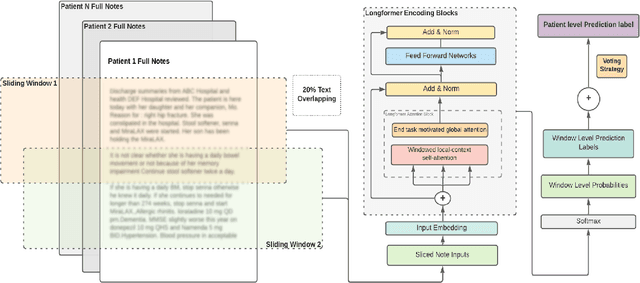
Dementia is under-recognized in the community, under-diagnosed by healthcare professionals, and under-coded in claims data. Information on cognitive dysfunction, however, is often found in unstructured clinician notes within medical records but manual review by experts is time consuming and often prone to errors. Automated mining of these notes presents a potential opportunity to label patients with cognitive concerns who could benefit from an evaluation or be referred to specialist care. In order to identify patients with cognitive concerns in electronic medical records, we applied natural language processing (NLP) algorithms and compared model performance to a baseline model that used structured diagnosis codes and medication data only. An attention-based deep learning model outperformed the baseline model and other simpler models.
Data science is science's second chance to get causal inference right: A classification of data science tasks
Oct 09, 2018Causal inference from observational data is the goal of many data analyses in the health and social sciences. However, academic statistics has often frowned upon data analyses with a causal objective. The introduction of the term "data science" provides a historic opportunity to redefine data analysis in such a way that it naturally accommodates causal inference from observational data. Like others before, we organize the scientific contributions of data science into three classes of tasks: description, prediction, and causal inference. An explicit classification of data science tasks is necessary to discuss the data, assumptions, and analytics required to successfully accomplish each task. We argue that a failure to adequately describe the role of subject-matter expert knowledge in data analysis is a source of widespread misunderstandings about data science. Specifically, causal analyses typically require not only good data and algorithms, but also domain expert knowledge. We discuss the implications for the use of data science to guide decision-making in the real world and to train data scientists.