 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Driven Methods for Balancing Fairness and Efficiency in Ride-Pooling
Oct 07, 2021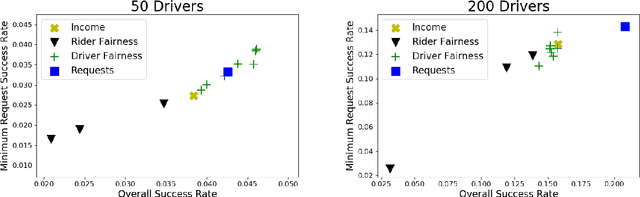
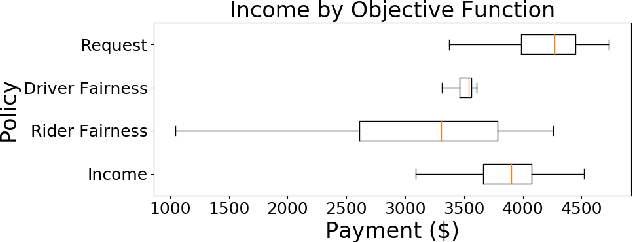
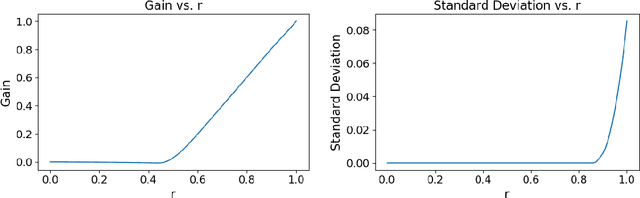
Rideshare and ride-pooling platforms use artificial intelligence-based matching algorithms to pair riders and drivers. However, these platforms can induce inequality either through an unequal income distribution or disparate treatment of riders. We investigate two methods to reduce forms of inequality in ride-pooling platforms: (1) incorporating fairness constraints into the objective function and (2) redistributing income to drivers to reduce income fluctuation and inequality. To evaluate our solutions, we use the New York City taxi data set. For the first method, we find that optimizing for driver-side fairness outperforms state-of-the-art models on the number of riders serviced, both in the worst-off neighborhood and overall, showing that optimizing for fairness can assist profitability in certain circumstances. For the second method, we explore income redistribution as a way to combat income inequality by having drivers keep an $r$ fraction of their income, and contributing the rest to a redistribution pool. For certain values of $r$, most drivers earn near their Shapley value, while still incentivizing drivers to maximize value, thereby avoiding the free-rider problem and reducing income variability. The first method can be extended to many definitions of fairness and the second method provably improves fairness without affecting profitability.
Learning Revenue-Maximizing Auctions With Differentiable Matching
Jun 15, 2021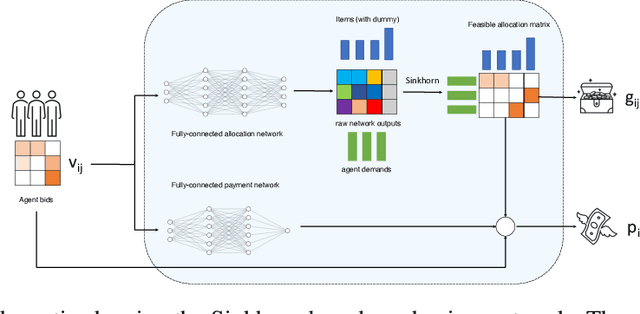

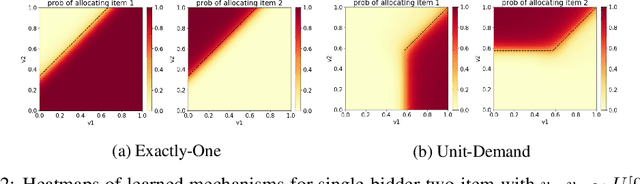
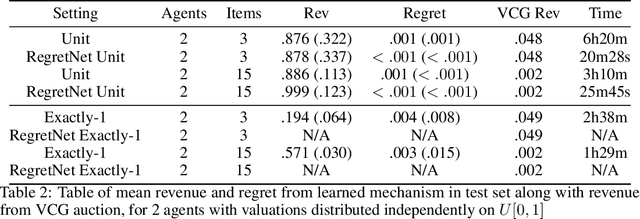
We propose a new architecture to approximately learn incentive compatible, revenue-maximizing auctions from sampled valuations. Our architecture uses the Sinkhorn algorithm to perform a differentiable bipartite matching which allows the network to learn strategyproof revenue-maximizing mechanisms in settings not learnable by the previous RegretNet architecture. In particular, our architecture is able to learn mechanisms in settings without free disposal where each bidder must be allocated exactly some number of items. In experiments, we show our approach successfully recovers multiple known optimal mechanisms and high-revenue, low-regret mechanisms in larger settings where the optimal mechanism is unknown.
Counterfactual Explanations for Machine Learning: Challenges Revisited
Jun 14, 2021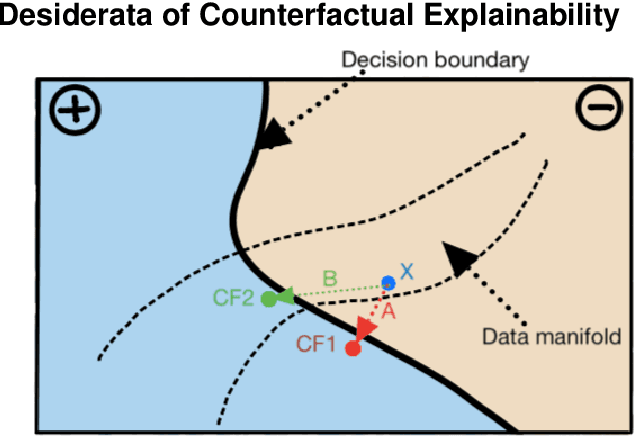
Counterfactual explanations (CFEs) are an emerging technique under the umbrella of interpretability of machine learning (ML) models. They provide ``what if'' feedback of the form ``if an input datapoint were $x'$ instead of $x$, then an ML model's output would be $y'$ instead of $y$.'' Counterfactual explainability for ML models has yet to see widespread adoption in industry. In this short paper, we posit reasons for this slow uptake. Leveraging recent work outlining desirable properties of CFEs and our experience running the ML wing of a model monitoring startup, we identify outstanding obstacles hindering CFE deployment in industry.
Planning to Fairly Allocate: Probabilistic Fairness in the Restless Bandit Setting
Jun 14, 2021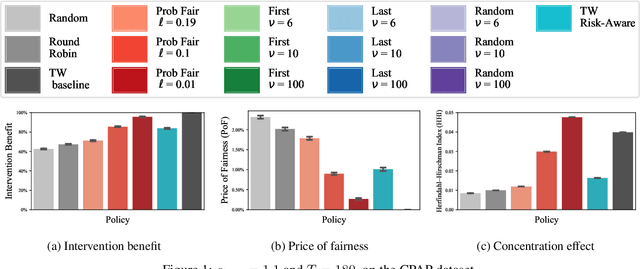
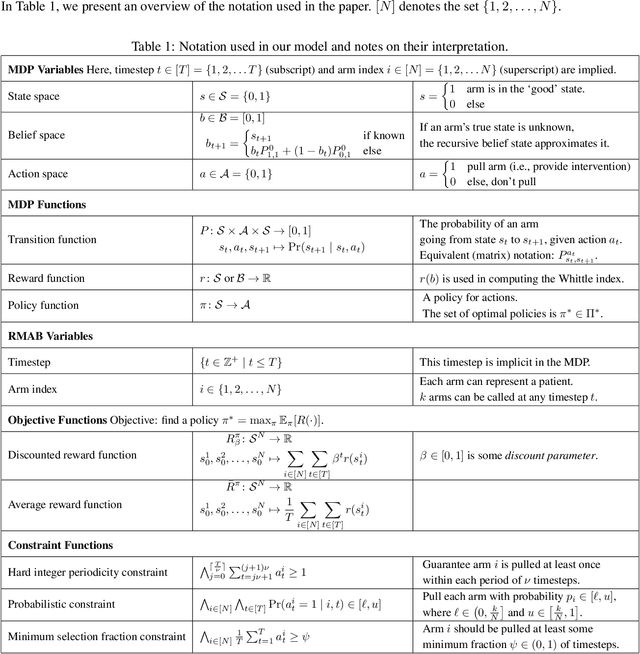
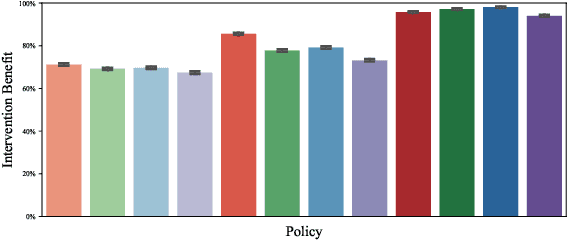
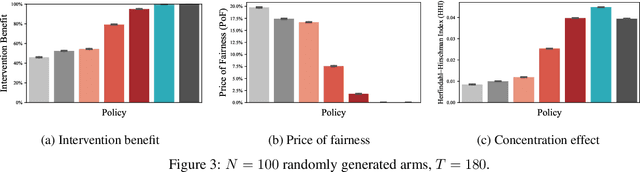
Restless and collapsing bandits are commonly used to model constrained resource allocation in settings featuring arms with action-dependent transition probabilities, such as allocating health interventions among patients [Whittle, 1988; Mate et al., 2020]. However, state-of-the-art Whittle-index-based approaches to this planning problem either do not consider fairness among arms, or incentivize fairness without guaranteeing it [Mate et al., 2021]. Additionally, their optimality guarantees only apply when arms are indexable and threshold-optimal. We demonstrate that the incorporation of hard fairness constraints necessitates the coupling of arms, which undermines the tractability, and by extension, indexability of the problem. We then introduce ProbFair, a probabilistically fair stationary policy that maximizes total expected reward and satisfies the budget constraint, while ensuring a strictly positive lower bound on the probability of being pulled at each timestep. We evaluate our algorithm on a real-world application, where interventions support continuous positive airway pressure (CPAP) therapy adherence among obstructive sleep apnea (OSA) patients, as well as simulations on a broader class of synthetic transition matrices.
LowKey: Leveraging Adversarial Attacks to Protect Social Media Users from Facial Recognition
Jan 25, 2021

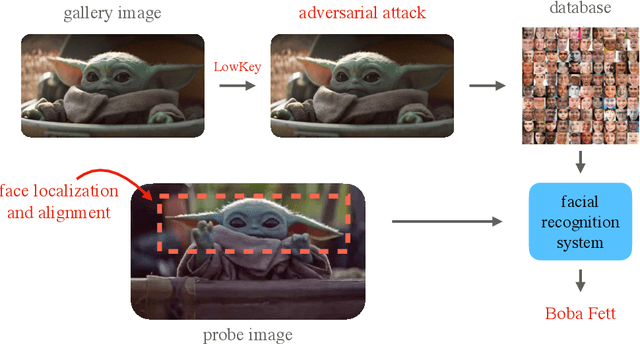
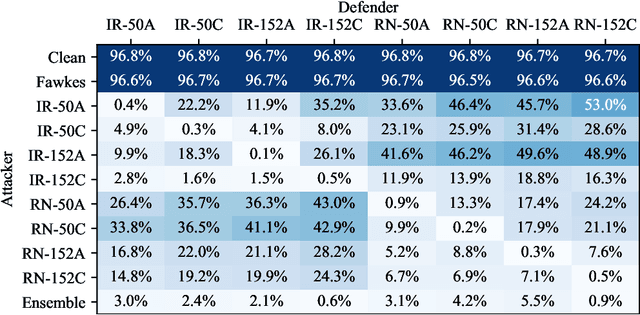
Facial recognition systems are increasingly deployed by private corporations, government agencies, and contractors for consumer services and mass surveillance programs alike. These systems are typically built by scraping social media profiles for user images. Adversarial perturbations have been proposed for bypassing facial recognition systems. However, existing methods fail on full-scale systems and commercial APIs. We develop our own adversarial filter that accounts for the entire image processing pipeline and is demonstrably effective against industrial-grade pipelines that include face detection and large scale databases. Additionally, we release an easy-to-use webtool that significantly degrades the accuracy of Amazon Rekognition and the Microsoft Azure Face Recognition API, reducing the accuracy of each to below 1%.
Counterfactual Explanations for Machine Learning: A Review
Oct 20, 2020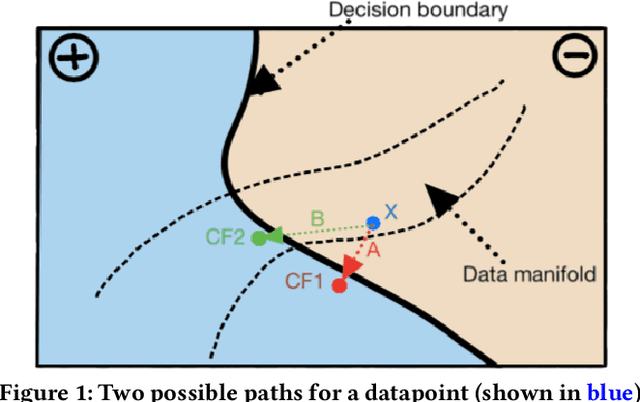
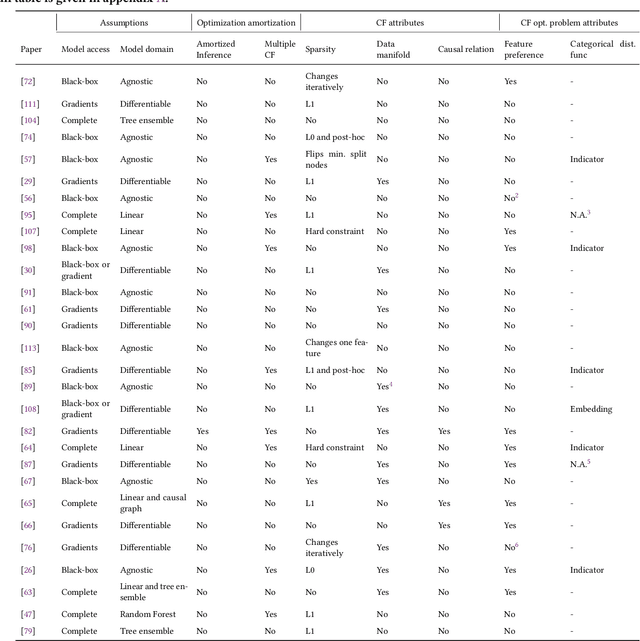
Machine learning plays a role in many deployed decision systems, often in ways that are difficult or impossible to understand by human stakeholders. Explaining, in a human-understandable way, the relationship between the input and output of machine learning models is essential to the development of trustworthy machine-learning-based systems. A burgeoning body of research seeks to define the goals and methods of explainability in machine learning. In this paper, we seek to review and categorize research on counterfactual explanations, a specific class of explanation that provides a link between what could have happened had input to a model been changed in a particular way. Modern approaches to counterfactual explainability in machine learning draw connections to the established legal doctrine in many countries, making them appealing to fielded systems in high-impact areas such as finance and healthcare. Thus, we design a rubric with desirable properties of counterfactual explanation algorithms and comprehensively evaluate all currently-proposed algorithms against that rubric. Our rubric provides easy comparison and comprehension of the advantages and disadvantages of different approaches and serves as an introduction to major research themes in this field. We also identify gaps and discuss promising research directions in the space of counterfactual explainability.
Detection as Regression: Certified Object Detection by Median Smoothing
Jul 07, 2020
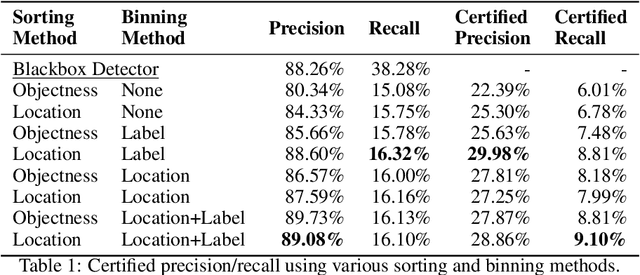

Despite the vulnerability of object detectors to adversarial attacks, very few defenses are known to date. While adversarial training can improve the empirical robustness of image classifiers, a direct extension to object detection is very expensive. This work is motivated by recent progress on certified classification by randomized smoothing. We start by presenting a reduction from object detection to a regression problem. Then, to enable certified regression, where standard mean smoothing fails, we propose median smoothing, which is of independent interest. We obtain the first model-agnostic, training-free, and certified defense for object detection against $\ell_2$-bounded attacks.
Certifying Strategyproof Auction Networks
Jun 15, 2020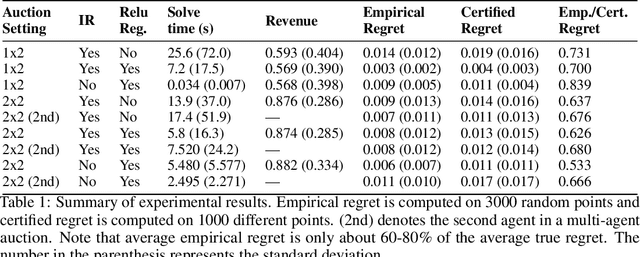
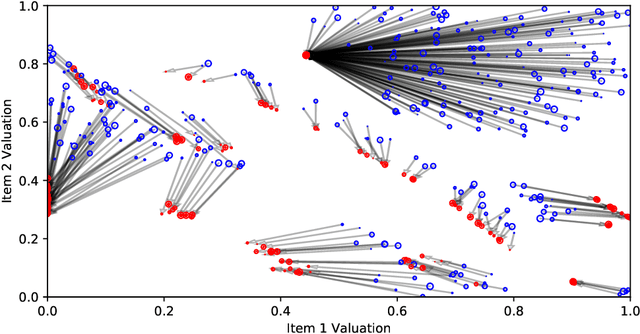
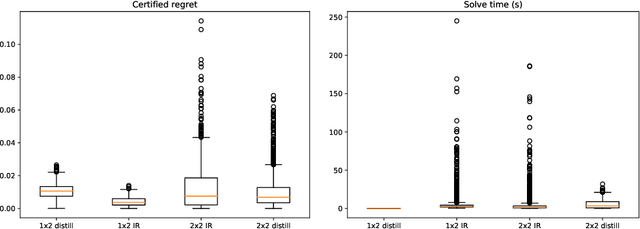

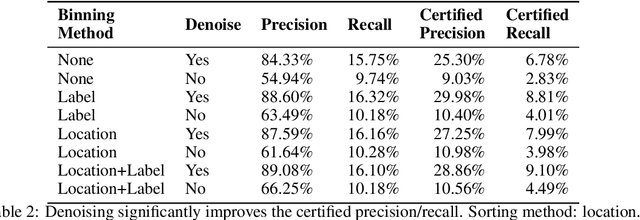
Optimal auctions maximize a seller's expected revenue subject to individual rationality and strategyproofness for the buyers. Myerson's seminal work in 1981 settled the case of auctioning a single item; however, subsequent decades of work have yielded little progress moving beyond a single item, leaving the design of revenue-maximizing auctions as a central open problem in the field of mechanism design. A recent thread of work in "differentiable economics" has used tools from modern deep learning to instead learn good mechanisms. We focus on the RegretNet architecture, which can represent auctions with arbitrary numbers of items and participants; it is trained to be empirically strategyproof, but the property is never exactly verified leaving potential loopholes for market participants to exploit. We propose ways to explicitly verify strategyproofness under a particular valuation profile using techniques from the neural network verification literature. Doing so requires making several modifications to the RegretNet architecture in order to represent it exactly in an integer program. We train our network and produce certificates in several settings, including settings for which the optimal strategyproof mechanism is not known.
Active Preference Elicitation via Adjustable Robust Optimization
Mar 04, 2020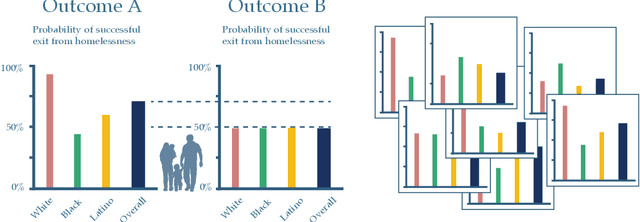

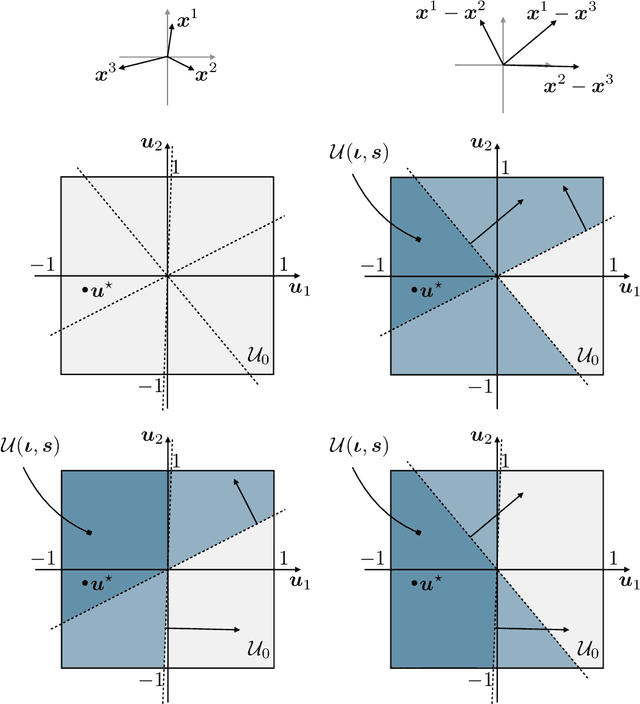
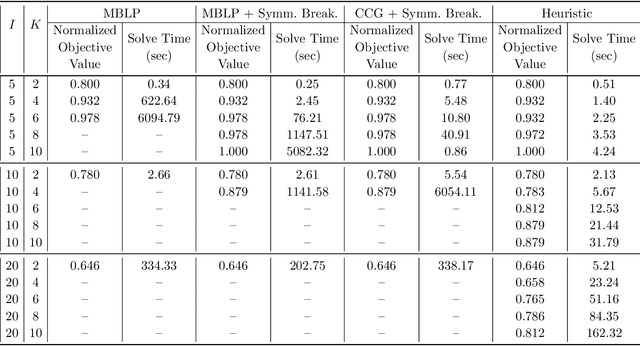
We consider the problem faced by a recommender system which seeks to offer a user with unknown preferences an item. Before making a recommendation, the system has the opportunity to elicit the user's preferences by making queries. Each query corresponds to a pairwise comparison between items. We take the point of view of either a risk averse or regret averse recommender system which only possess set-based information on the user utility function. We investigate: a) an offline elicitation setting, where all queries are made at once, and b) an online elicitation setting, where queries are selected sequentially over time. We propose exact robust optimization formulations of these problems which integrate the elicitation and recommendation phases and study the complexity of these problems. For the offline case, where the problem takes the form of a two-stage robust optimization problem with decision-dependent information discovery, we provide an enumeration-based algorithm and also an equivalent reformulation in the form of a mixed-binary linear program which we solve via column-and-constraint generation. For the online setting, where the problem takes the form of a multi-stage robust optimization problem with decision-dependent information discovery, we propose a conservative solution approach. We evaluate the performance of our methods on both synthetic data and real data from the Homeless Management Information System. We simulate elicitation of the preferences of policy-makers in terms of characteristics of housing allocation policies to better match individuals experiencing homelessness to scarce housing resources. Our framework is shown to outperform the state-of-the-art techniques from the literature.
Forming Diverse Teams from Sequentially Arriving People
Feb 25, 2020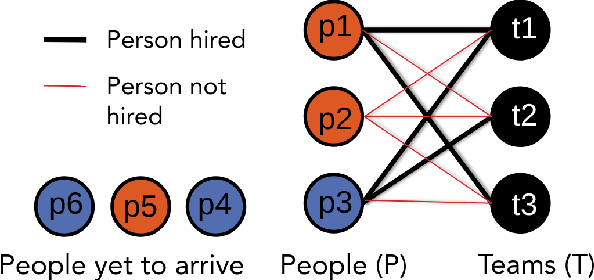


Collaborative work often benefits from having teams or organizations with heterogeneous members. In this paper, we present a method to form such diverse teams from people arriving sequentially over time. We define a monotone submodular objective function that combines the diversity and quality of a team and propose an algorithm to maximize the objective while satisfying multiple constraints. This allows us to balance both how diverse the team is and how well it can perform the task at hand. Using crowd experiments, we show that, in practice, the algorithm leads to large gains in team diversity. Using simulations, we show how to quantify the additional cost of forming diverse teams and how to address the problem of simultaneously maximizing diversity for several attributes (e.g., country of origin, gender). Our method has applications in collaborative work ranging from team formation, the assignment of workers to teams in crowdsourcing, and reviewer allocation to journal papers arriving sequentially. Our code is publicly accessible for further research.