 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisease Entity Recognition and Normalization is Improved with Large Language Model Derived Synthetic Normalized Mentions
Oct 10, 2024



Background: Machine learning methods for clinical named entity recognition and entity normalization systems can utilize both labeled corpora and Knowledge Graphs (KGs) for learning. However, infrequently occurring concepts may have few mentions in training corpora and lack detailed descriptions or synonyms, even in large KGs. For Disease Entity Recognition (DER) and Disease Entity Normalization (DEN), this can result in fewer high quality training examples relative to the number of known diseases. Large Language Model (LLM) generation of synthetic training examples could improve performance in these information extraction tasks. Methods: We fine-tuned a LLaMa-2 13B Chat LLM to generate a synthetic corpus containing normalized mentions of concepts from the Unified Medical Language System (UMLS) Disease Semantic Group. We measured overall and Out of Distribution (OOD) performance for DER and DEN, with and without synthetic data augmentation. We evaluated performance on 3 different disease corpora using 4 different data augmentation strategies, assessed using BioBERT for DER and SapBERT and KrissBERT for DEN. Results: Our synthetic data yielded a substantial improvement for DEN, in all 3 training corpora the top 1 accuracy of both SapBERT and KrissBERT improved by 3-9 points in overall performance and by 20-55 points in OOD data. A small improvement (1-2 points) was also seen for DER in overall performance, but only one dataset showed OOD improvement. Conclusion: LLM generation of normalized disease mentions can improve DEN relative to normalization approaches that do not utilize LLMs to augment data with synthetic mentions. Ablation studies indicate that performance gains for DEN were only partially attributable to improvements in OOD performance. The same approach has only a limited ability to improve DER. We make our software and dataset publicly available.
Transfer Learning for the Prediction of Entity Modifiers in Clinical Text: Application to Opioid Use Disorder Case Detection
Feb 05, 2024Background: The semantics of entities extracted from a clinical text can be dramatically altered by modifiers, including entity negation, uncertainty, conditionality, severity, and subject. Existing models for determining modifiers of clinical entities involve regular expression or features weights that are trained independently for each modifier. Methods: We develop and evaluate a multi-task transformer architecture design where modifiers are learned and predicted jointly using the publicly available SemEval 2015 Task 14 corpus and a new Opioid Use Disorder (OUD) data set that contains modifiers shared with SemEval as well as novel modifiers specific for OUD. We evaluate the effectiveness of our multi-task learning approach versus previously published systems and assess the feasibility of transfer learning for clinical entity modifiers when only a portion of clinical modifiers are shared. Results: Our approach achieved state-of-the-art results on the ShARe corpus from SemEval 2015 Task 14, showing an increase of 1.1% on weighted accuracy, 1.7% on unweighted accuracy, and 10% on micro F1 scores. Conclusions: We show that learned weights from our shared model can be effectively transferred to a new partially matched data set, validating the use of transfer learning for clinical text modifiers
An Open Natural Language Processing Development Framework for EHR-based Clinical Research: A case demonstration using the National COVID Cohort Collaborative (N3C)
Oct 20, 2021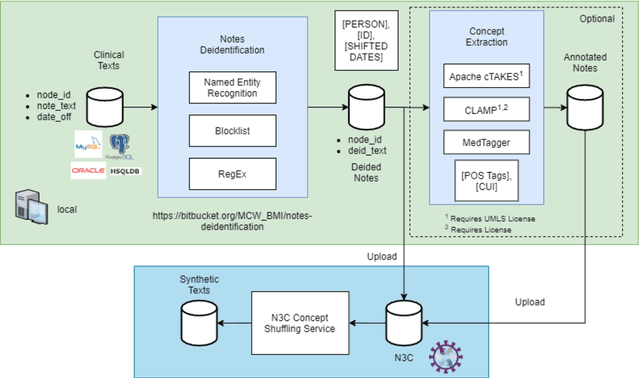

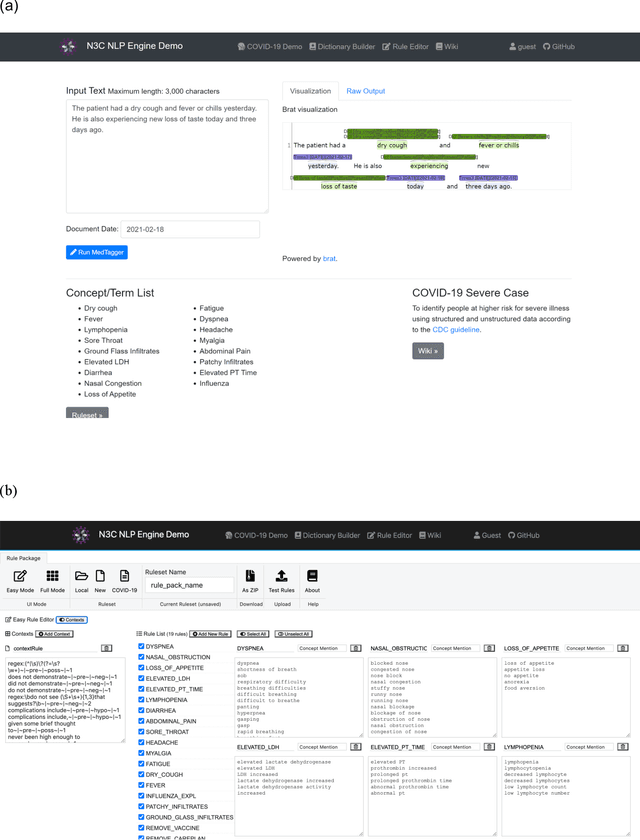
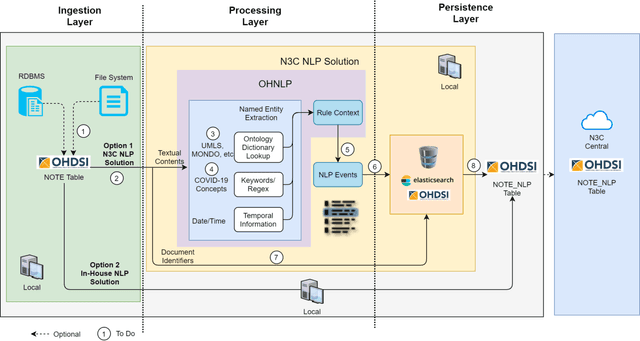
While we pay attention to the latest advances in clinical natural language processing (NLP), we can notice some resistance in the clinical and translational research community to adopt NLP models due to limited transparency, Interpretability and usability. Built upon our previous work, in this study, we proposed an open natural language processing development framework and evaluated it through the implementation of NLP algorithms for the National COVID Cohort Collaborative (N3C). Based on the interests in information extraction from COVID-19 related clinical notes, our work includes 1) an open data annotation process using COVID-19 signs and symptoms as the use case, 2) a community-driven ruleset composing platform, and 3) a synthetic text data generation workflow to generate texts for information extraction tasks without involving human subjects. The generated corpora derived out of the texts from multiple intuitions and gold standard annotation are tested on a single institution's rule set has the performances in F1 score of 0.876, 0.706 and 0.694, respectively. The study as a consortium effort of the N3C NLP subgroup demonstrates the feasibility of creating a federated NLP algorithm development and benchmarking platform to enhance multi-institution clinical NLP study.