 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-Augmented Transformers for Robust AI-Text Detection Across Domains and Generators
May 05, 2026AI-generated text is nowadays produced at scale across domains and heterogeneous generation pipelines, making robustness to distribution shift a central requirement for supervised binary detectors. We train transformer-based detectors on HC3 PLUS and calibrate a single decision threshold by maximising balanced accuracy on held-out validation; this threshold is then kept fixed for all downstream test distributions, revealing domain- and generator-dependent error asymmetries under shift. We evaluate in-domain on HC3 PLUS, under cross-dataset transfer to the multi-domain, multi-generator M4 benchmark, and on the external AI-Text-Detection-Pile. Although base models achieve near-ceiling in-domain performance (up to 99.5% balanced accuracy), performance under shift is brittle and strongly model-dependent. Feature augmentation via attention-based linguistic feature fusion improves transfer, with our best model (DeBERTa-v3-base+FeatAttn) achieving 85.9% balanced accuracy on M4. Multi-seed experiments confirm high stability. Under the same fixed-threshold protocol, our model outperforms strong zero-shot baselines by up to +7.22 points. Category-level ablations further show that readability and vocabulary features contribute most to robustness under shift. Overall, these results demonstrate that feature augmentation and a modern DeBERTa backbone significantly outperform earlier BERT/RoBERTa models, while the fixed-threshold protocol provides a more realistic and informative assessment of practical detector robustness.
David vs. Goliath: A comparative study of different-sized LLMs for code generation in the domain of automotive scenario generation
Oct 15, 2025



Scenario simulation is central to testing autonomous driving systems. Scenic, a domain-specific language (DSL) for CARLA, enables precise and reproducible scenarios, but NL-to-Scenic generation with large language models (LLMs) suffers from scarce data, limited reproducibility, and inconsistent metrics. We introduce NL2Scenic, an open dataset and framework with 146 NL/Scenic pairs, a difficulty-stratified 30-case test split, an Example Retriever, and 14 prompting variants (ZS, FS, CoT, SP, MoT). We evaluate 13 models: four proprietary (GPT-4o, GPT-5, Claude-Sonnet-4, Gemini-2.5-pro) and nine open-source code models (Qwen2.5Coder 0.5B-32B; CodeLlama 7B/13B/34B), using text metrics (BLEU, ChrF, EDIT-SIM, CrystalBLEU) and execution metrics (compilation and generation), and compare them with an expert study (n=11). EDIT-SIM correlates best with human judgments; we also propose EDIT-COMP (F1 of EDIT-SIM and compilation) as a robust dataset-level proxy that improves ranking fidelity. GPT-4o performs best overall, while Qwen2.5Coder-14B reaches about 88 percent of its expert score on local hardware. Retrieval-augmented prompting, Few-Shot with Example Retriever (FSER), consistently boosts smaller models, and scaling shows diminishing returns beyond mid-size, with Qwen2.5Coder outperforming CodeLlama at comparable scales. NL2Scenic and EDIT-COMP offer a standardized, reproducible basis for evaluating Scenic code generation and indicate that mid-size open-source models are practical, cost-effective options for autonomous-driving scenario programming.
Deepfake Detection of Face Images based on a Convolutional Neural Network
Mar 14, 2025



Fake News and especially deepfakes (generated, non-real image or video content) have become a serious topic over the last years. With the emergence of machine learning algorithms it is now easier than ever before to generate such fake content, even for private persons. This issue of generated fake images is especially critical in the context of politics and public figures. We want to address this conflict by building a model based on a Convolutions Neural Network in order to detect such generated and fake images showing human portraits. As a basis, we use a pre-trained ResNet-50 model due to its effectiveness in terms of classifying images. We then adopted the base model to our task of classifying a single image as authentic/real or fake by adding an fully connected output layer containing a single neuron indicating the authenticity of an image. We applied fine tuning and transfer learning to develop the model and improve its parameters. For the training process we collected the image data set "Diverse Face Fake Dataset" containing a wide range of different image manipulation methods and also diversity in terms of faces visible on the images. With our final model we reached the following outstanding performance metrics: precision = 0.98, recall 0.96, F1-Score = 0.97 and an area-under-curve = 0.99.
Face Recognition with Machine Learning in OpenCV_ Fusion of the results with the Localization Data of an Acoustic Camera for Speaker Identification
Jul 04, 2017
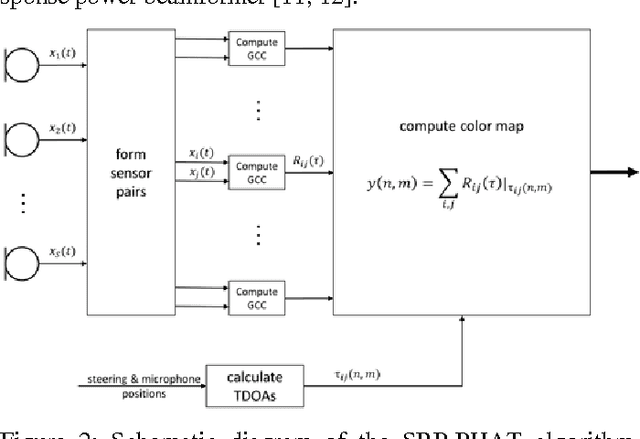

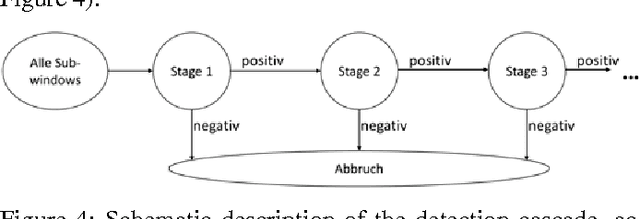
This contribution gives an overview of face recogni-tion algorithms, their implementation and practical uses. First, a training set of different persons' faces has to be collected and used to train a face recognizer. The resulting face model can be utilized to classify people in specific individuals or unknowns. After tracking the recognized face and estimating the acoustic sound source's position, both can be combined to give detailed information about possible speakers and if they are talking or not. This leads to a precise real-time description of the situation, which can be used for further applications, e.g. for multi-channel speech enhancement by adaptive beamformers.