 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Neural Light Fields with Ray-Space Embedding Networks
Dec 06, 2021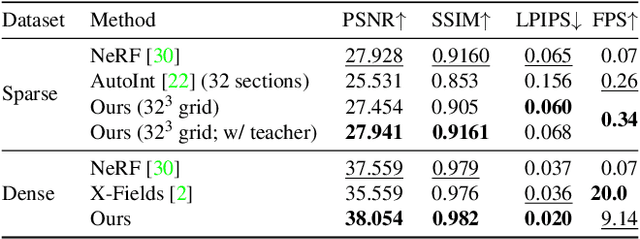
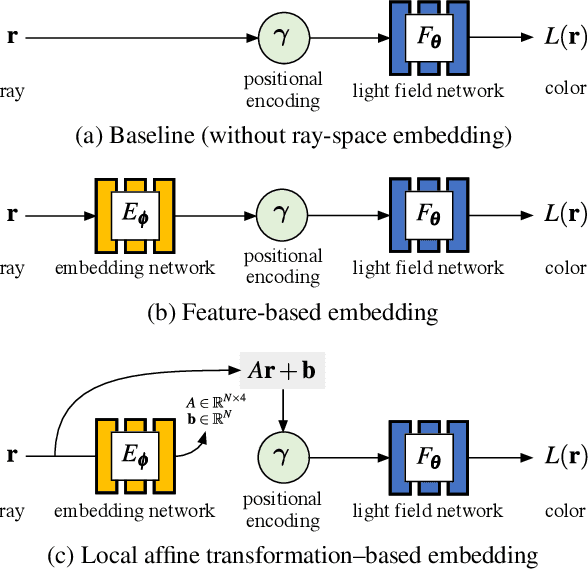

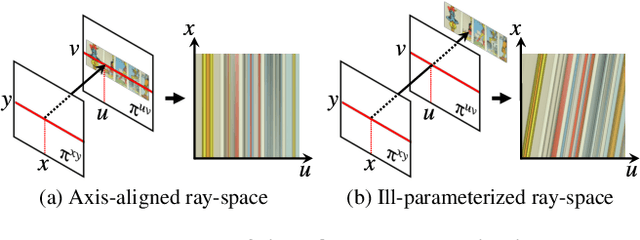
Neural radiance fields (NeRFs) produce state-of-the-art view synthesis results. However, they are slow to render, requiring hundreds of network evaluations per pixel to approximate a volume rendering integral. Baking NeRFs into explicit data structures enables efficient rendering, but results in a large increase in memory footprint and, in many cases, a quality reduction. In this paper, we propose a novel neural light field representation that, in contrast, is compact and directly predicts integrated radiance along rays. Our method supports rendering with a single network evaluation per pixel for small baseline light field datasets and can also be applied to larger baselines with only a few evaluations per pixel. At the core of our approach is a ray-space embedding network that maps the 4D ray-space manifold into an intermediate, interpolable latent space. Our method achieves state-of-the-art quality on dense forward-facing datasets such as the Stanford Light Field dataset. In addition, for forward-facing scenes with sparser inputs we achieve results that are competitive with NeRF-based approaches in terms of quality while providing a better speed/quality/memory trade-off with far fewer network evaluations.
Dynamic View Synthesis from Dynamic Monocular Video
May 13, 2021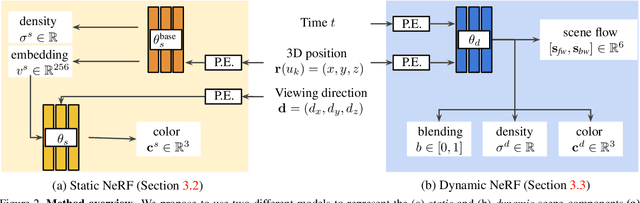


We present an algorithm for generating novel views at arbitrary viewpoints and any input time step given a monocular video of a dynamic scene. Our work builds upon recent advances in neural implicit representation and uses continuous and differentiable functions for modeling the time-varying structure and the appearance of the scene. We jointly train a time-invariant static NeRF and a time-varying dynamic NeRF, and learn how to blend the results in an unsupervised manner. However, learning this implicit function from a single video is highly ill-posed (with infinitely many solutions that match the input video). To resolve the ambiguity, we introduce regularization losses to encourage a more physically plausible solution. We show extensive quantitative and qualitative results of dynamic view synthesis from casually captured videos.
Robust Consistent Video Depth Estimation
Dec 10, 2020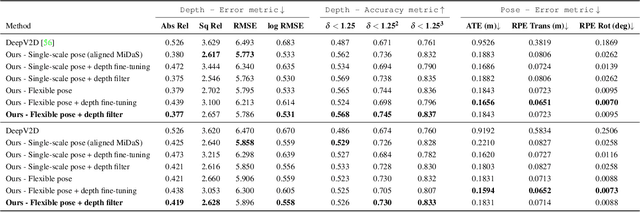
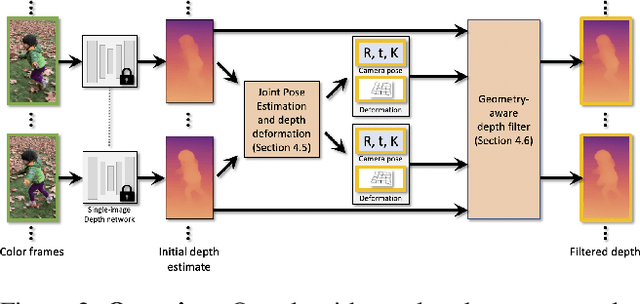
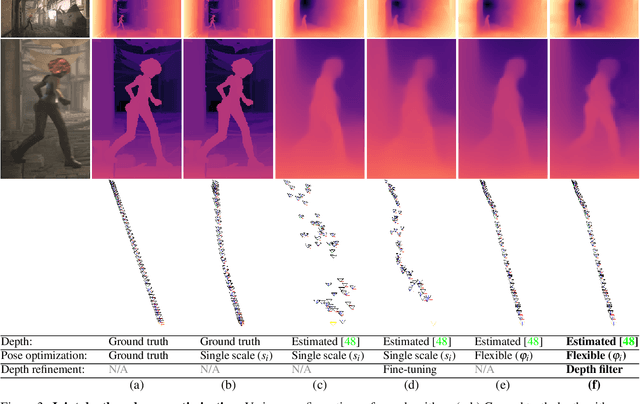
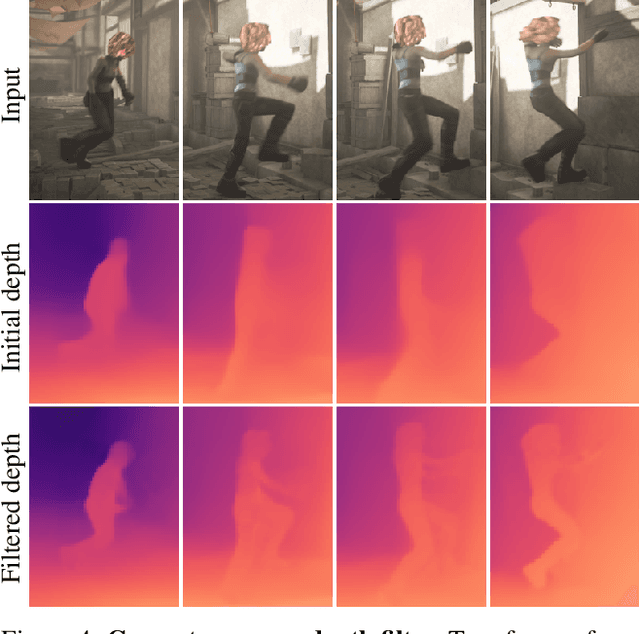
We present an algorithm for estimating consistent dense depth maps and camera poses from a monocular video. We integrate a learning-based depth prior, in the form of a convolutional neural network trained for single-image depth estimation, with geometric optimization, to estimate a smooth camera trajectory as well as detailed and stable depth reconstruction. Our algorithm combines two complementary techniques: (1) flexible deformation-splines for low-frequency large-scale alignment and (2) geometry-aware depth filtering for high-frequency alignment of fine depth details. In contrast to prior approaches, our method does not require camera poses as input and achieves robust reconstruction for challenging hand-held cell phone captures containing a significant amount of noise, shake, motion blur, and rolling shutter deformations. Our method quantitatively outperforms state-of-the-arts on the Sintel benchmark for both depth and pose estimations and attains favorable qualitative results across diverse wild datasets.
Space-time Neural Irradiance Fields for Free-Viewpoint Video
Nov 25, 2020

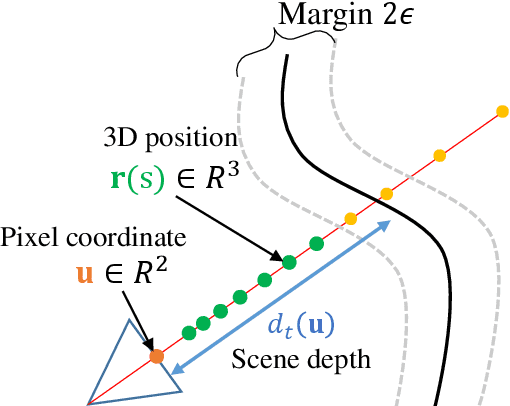

We present a method that learns a spatiotemporal neural irradiance field for dynamic scenes from a single video. Our learned representation enables free-viewpoint rendering of the input video. Our method builds upon recent advances in implicit representations. Learning a spatiotemporal irradiance field from a single video poses significant challenges because the video contains only one observation of the scene at any point in time. The 3D geometry of a scene can be legitimately represented in numerous ways since varying geometry (motion) can be explained with varying appearance and vice versa. We address this ambiguity by constraining the time-varying geometry of our dynamic scene representation using the scene depth estimated from video depth estimation methods, aggregating contents from individual frames into a single global representation. We provide an extensive quantitative evaluation and demonstrate compelling free-viewpoint rendering results.
Flow-edge Guided Video Completion
Sep 03, 2020
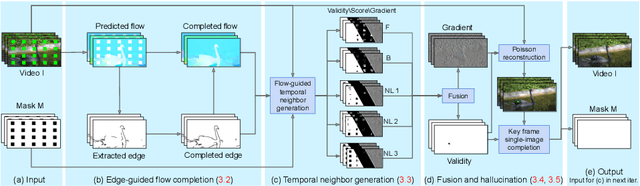
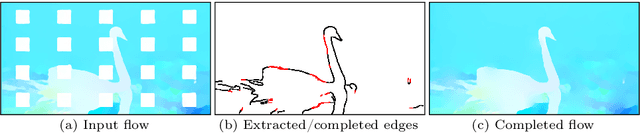

We present a new flow-based video completion algorithm. Previous flow completion methods are often unable to retain the sharpness of motion boundaries. Our method first extracts and completes motion edges, and then uses them to guide piecewise-smooth flow completion with sharp edges. Existing methods propagate colors among local flow connections between adjacent frames. However, not all missing regions in a video can be reached in this way because the motion boundaries form impenetrable barriers. Our method alleviates this problem by introducing non-local flow connections to temporally distant frames, enabling propagating video content over motion boundaries. We validate our approach on the DAVIS dataset. Both visual and quantitative results show that our method compares favorably against the state-of-the-art algorithms.
One Shot 3D Photography
Sep 01, 2020
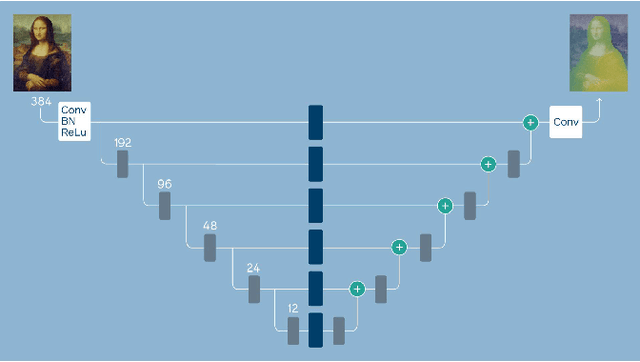

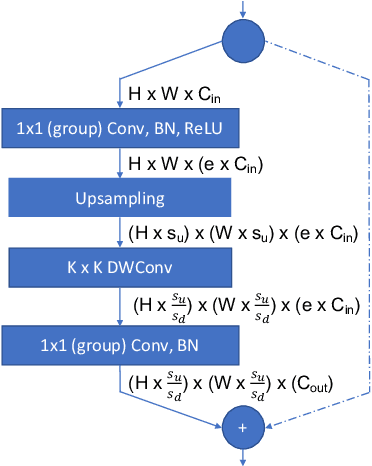
3D photography is a new medium that allows viewers to more fully experience a captured moment. In this work, we refer to a 3D photo as one that displays parallax induced by moving the viewpoint (as opposed to a stereo pair with a fixed viewpoint). 3D photos are static in time, like traditional photos, but are displayed with interactive parallax on mobile or desktop screens, as well as on Virtual Reality devices, where viewing it also includes stereo. We present an end-to-end system for creating and viewing 3D photos, and the algorithmic and design choices therein. Our 3D photos are captured in a single shot and processed directly on a mobile device. The method starts by estimating depth from the 2D input image using a new monocular depth estimation network that is optimized for mobile devices. It performs competitively to the state-of-the-art, but has lower latency and peak memory consumption and uses an order of magnitude fewer parameters. The resulting depth is lifted to a layered depth image, and new geometry is synthesized in parallax regions. We synthesize color texture and structures in the parallax regions as well, using an inpainting network, also optimized for mobile devices, on the LDI directly. Finally, we convert the result into a mesh-based representation that can be efficiently transmitted and rendered even on low-end devices and over poor network connections. Altogether, the processing takes just a few seconds on a mobile device, and the result can be instantly viewed and shared. We perform extensive quantitative evaluation to validate our system and compare its new components against the current state-of-the-art.
* Project page: https://facebookresearch.github.io/one_shot_3d_photography/ Code: https://github.com/facebookresearch/one_shot_3d_photography
Consistent Video Depth Estimation
Apr 30, 2020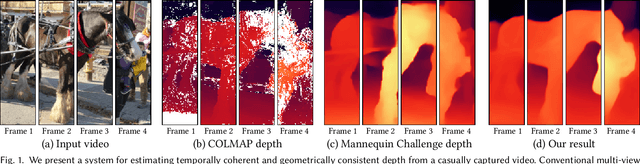
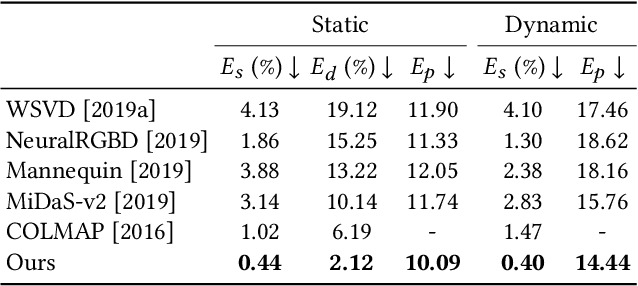
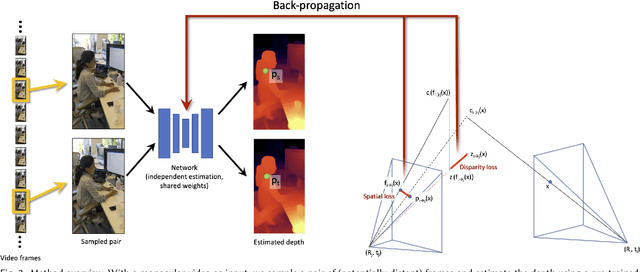
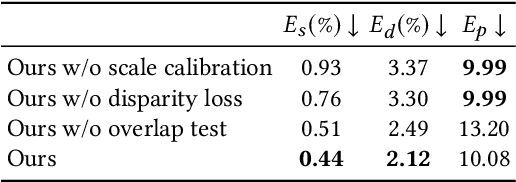
We present an algorithm for reconstructing dense, geometrically consistent depth for all pixels in a monocular video. We leverage a conventional structure-from-motion reconstruction to establish geometric constraints on pixels in the video. Unlike the ad-hoc priors in classical reconstruction, we use a learning-based prior, i.e., a convolutional neural network trained for single-image depth estimation. At test time, we fine-tune this network to satisfy the geometric constraints of a particular input video, while retaining its ability to synthesize plausible depth details in parts of the video that are less constrained. We show through quantitative validation that our method achieves higher accuracy and a higher degree of geometric consistency than previous monocular reconstruction methods. Visually, our results appear more stable. Our algorithm is able to handle challenging hand-held captured input videos with a moderate degree of dynamic motion. The improved quality of the reconstruction enables several applications, such as scene reconstruction and advanced video-based visual effects.
3D Photography using Context-aware Layered Depth Inpainting
Apr 14, 2020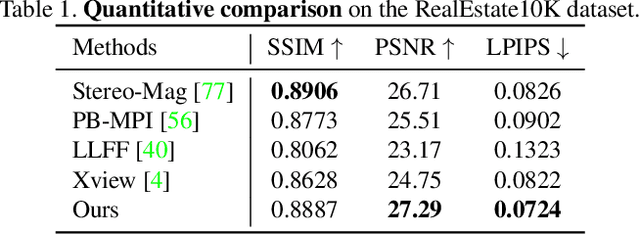
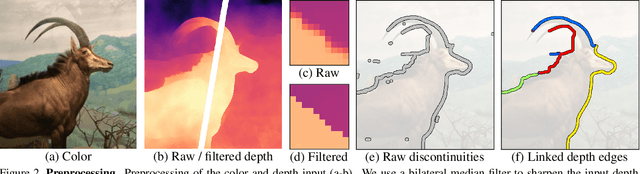
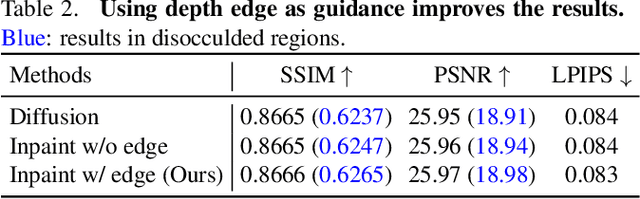

We propose a method for converting a single RGB-D input image into a 3D photo - a multi-layer representation for novel view synthesis that contains hallucinated color and depth structures in regions occluded in the original view. We use a Layered Depth Image with explicit pixel connectivity as underlying representation, and present a learning-based inpainting model that synthesizes new local color-and-depth content into the occluded region in a spatial context-aware manner. The resulting 3D photos can be efficiently rendered with motion parallax using standard graphics engines. We validate the effectiveness of our method on a wide range of challenging everyday scenes and show fewer artifacts compared with the state of the arts.
DeepMVS: Learning Multi-view Stereopsis
Apr 02, 2018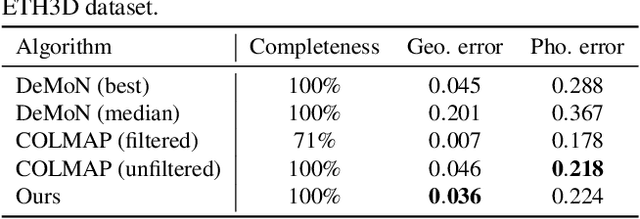
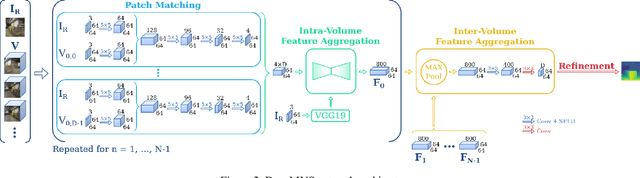

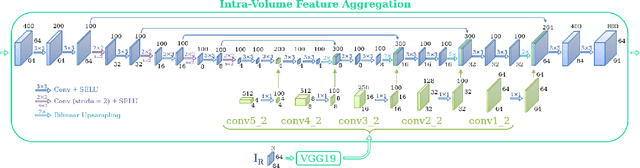
We present DeepMVS, a deep convolutional neural network (ConvNet) for multi-view stereo reconstruction. Taking an arbitrary number of posed images as input, we first produce a set of plane-sweep volumes and use the proposed DeepMVS network to predict high-quality disparity maps. The key contributions that enable these results are (1) supervised pretraining on a photorealistic synthetic dataset, (2) an effective method for aggregating information across a set of unordered images, and (3) integrating multi-layer feature activations from the pre-trained VGG-19 network. We validate the efficacy of DeepMVS using the ETH3D Benchmark. Our results show that DeepMVS compares favorably against state-of-the-art conventional MVS algorithms and other ConvNet based methods, particularly for near-textureless regions and thin structures.
Co-segmentation for Space-Time Co-located Collections
Jan 31, 2017
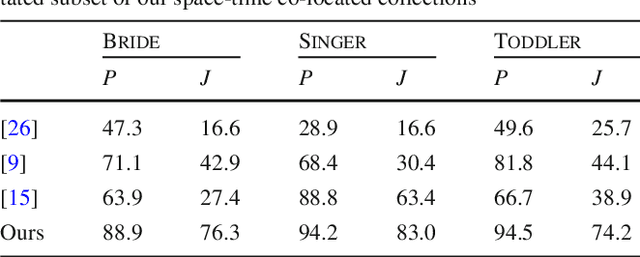
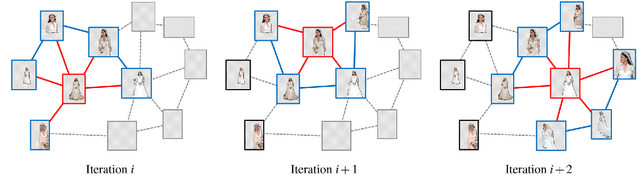
We present a co-segmentation technique for space-time co-located image collections. These prevalent collections capture various dynamic events, usually by multiple photographers, and may contain multiple co-occurring objects which are not necessarily part of the intended foreground object, resulting in ambiguities for traditional co-segmentation techniques. Thus, to disambiguate what the common foreground object is, we introduce a weakly-supervised technique, where we assume only a small seed, given in the form of a single segmented image. We take a distributed approach, where local belief models are propagated and reinforced with similar images. Our technique progressively expands the foreground and background belief models across the entire collection. The technique exploits the power of the entire set of image without building a global model, and thus successfully overcomes large variability in appearance of the common foreground object. We demonstrate that our method outperforms previous co-segmentation techniques on challenging space-time co-located collections, including dense benchmark datasets which were adapted for our novel problem setting.