 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings of the 29th International Conference on Machine Learning (ICML-12)
Sep 16, 2012This is an index to the papers that appear in the Proceedings of the 29th International Conference on Machine Learning (ICML-12). The conference was held in Edinburgh, Scotland, June 27th - July 3rd, 2012.
Model-Based Bayesian Reinforcement Learning in Large Structured Domains
Jun 13, 2012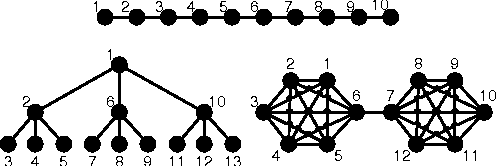
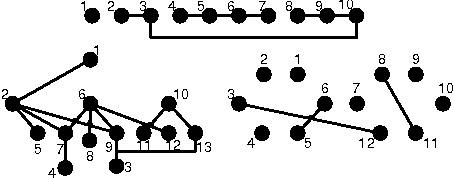
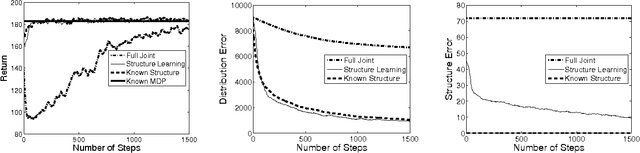
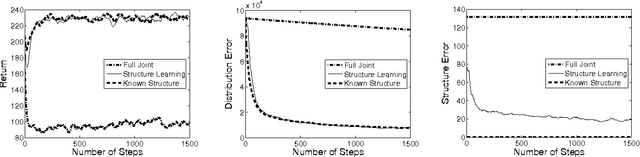
Model-based Bayesian reinforcement learning has generated significant interest in the AI community as it provides an elegant solution to the optimal exploration-exploitation tradeoff in classical reinforcement learning. Unfortunately, the applicability of this type of approach has been limited to small domains due to the high complexity of reasoning about the joint posterior over model parameters. In this paper, we consider the use of factored representations combined with online planning techniques, to improve scalability of these methods. The main contribution of this paper is a Bayesian framework for learning the structure and parameters of a dynamical system, while also simultaneously planning a (near-)optimal sequence of actions.
Active Learning for Developing Personalized Treatment
Feb 14, 2012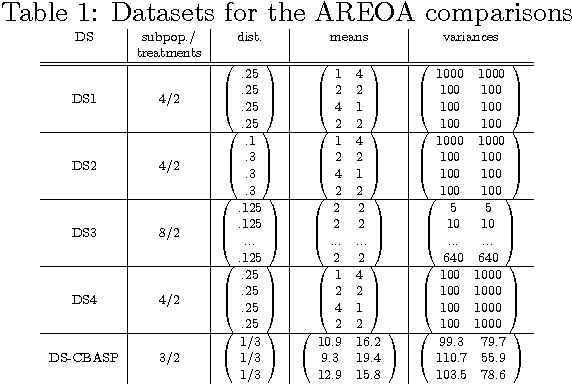
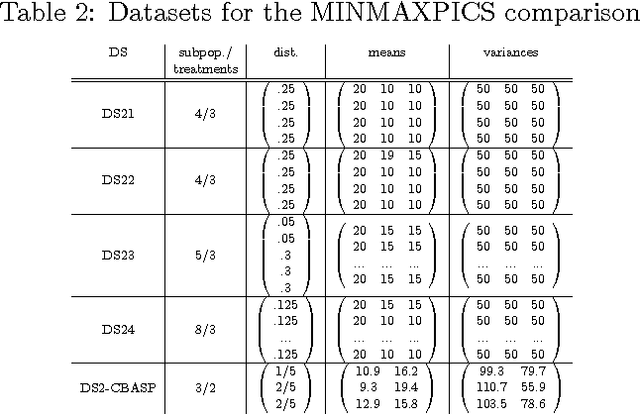
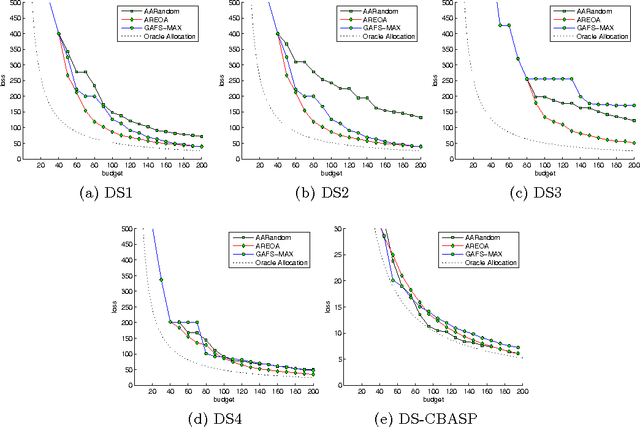
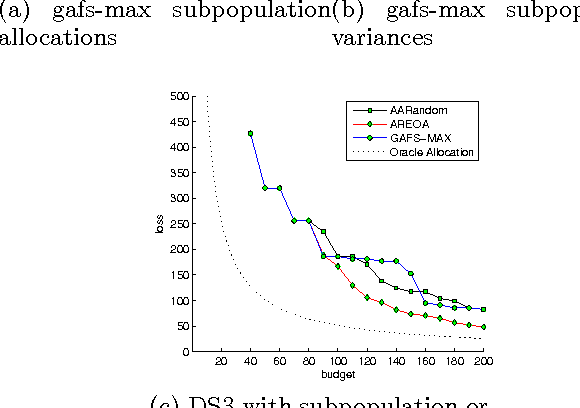
The personalization of treatment via bio-markers and other risk categories has drawn increasing interest among clinical scientists. Personalized treatment strategies can be learned using data from clinical trials, but such trials are very costly to run. This paper explores the use of active learning techniques to design more efficient trials, addressing issues such as whom to recruit, at what point in the trial, and which treatment to assign, throughout the duration of the trial. We propose a minimax bandit model with two different optimization criteria, and discuss the computational challenges and issues pertaining to this approach. We evaluate our active learning policies using both simulated data, and data modeled after a clinical trial for treating depressed individuals, and contrast our methods with other plausible active learning policies.
PAC-Bayesian Policy Evaluation for Reinforcement Learning
Feb 14, 2012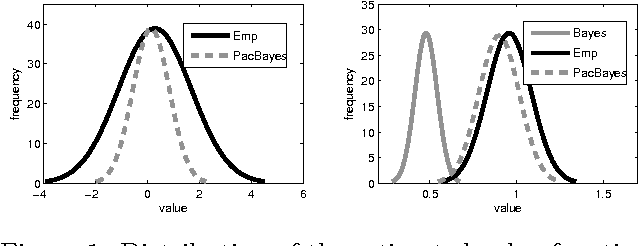
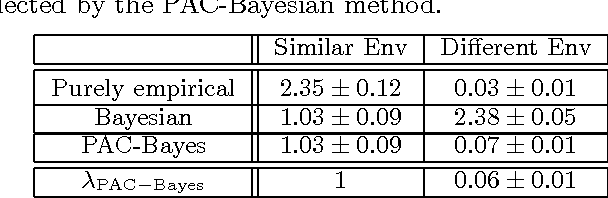

Bayesian priors offer a compact yet general means of incorporating domain knowledge into many learning tasks. The correctness of the Bayesian analysis and inference, however, largely depends on accuracy and correctness of these priors. PAC-Bayesian methods overcome this problem by providing bounds that hold regardless of the correctness of the prior distribution. This paper introduces the first PAC-Bayesian bound for the batch reinforcement learning problem with function approximation. We show how this bound can be used to perform model-selection in a transfer learning scenario. Our empirical results confirm that PAC-Bayesian policy evaluation is able to leverage prior distributions when they are informative and, unlike standard Bayesian RL approaches, ignore them when they are misleading.