 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Computation in Neural Networks for faster models
Jan 07, 2016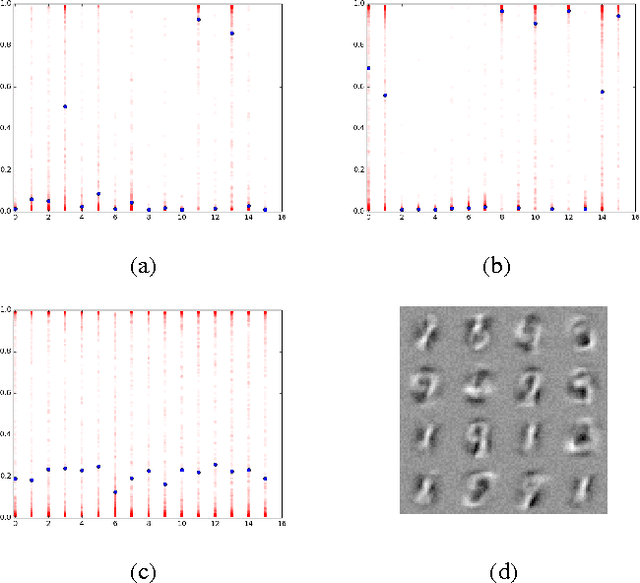
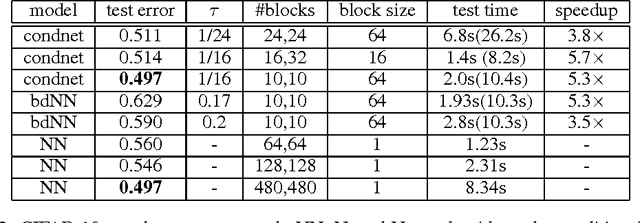
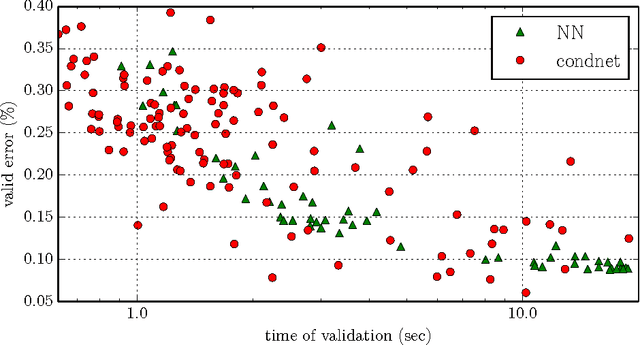
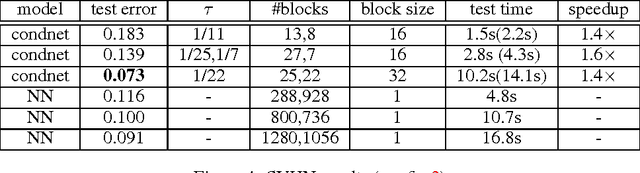
Deep learning has become the state-of-art tool in many applications, but the evaluation and training of deep models can be time-consuming and computationally expensive. The conditional computation approach has been proposed to tackle this problem (Bengio et al., 2013; Davis & Arel, 2013). It operates by selectively activating only parts of the network at a time. In this paper, we use reinforcement learning as a tool to optimize conditional computation policies. More specifically, we cast the problem of learning activation-dependent policies for dropping out blocks of units as a reinforcement learning problem. We propose a learning scheme motivated by computation speed, capturing the idea of wanting to have parsimonious activations while maintaining prediction accuracy. We apply a policy gradient algorithm for learning policies that optimize this loss function and propose a regularization mechanism that encourages diversification of the dropout policy. We present encouraging empirical results showing that this approach improves the speed of computation without impacting the quality of the approximation.
Practical Kernel-Based Reinforcement Learning
Jul 21, 2014


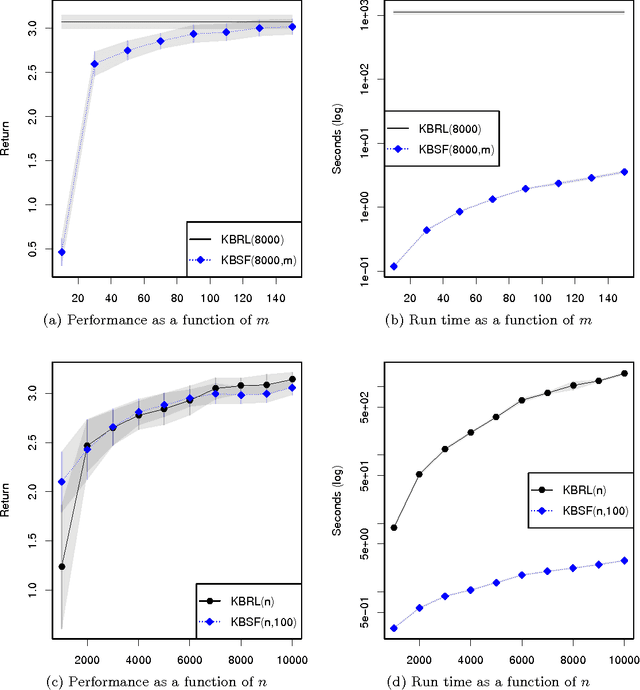
Kernel-based reinforcement learning (KBRL) stands out among reinforcement learning algorithms for its strong theoretical guarantees. By casting the learning problem as a local kernel approximation, KBRL provides a way of computing a decision policy which is statistically consistent and converges to a unique solution. Unfortunately, the model constructed by KBRL grows with the number of sample transitions, resulting in a computational cost that precludes its application to large-scale or on-line domains. In this paper we introduce an algorithm that turns KBRL into a practical reinforcement learning tool. Kernel-based stochastic factorization (KBSF) builds on a simple idea: when a transition matrix is represented as the product of two stochastic matrices, one can swap the factors of the multiplication to obtain another transition matrix, potentially much smaller, which retains some fundamental properties of its precursor. KBSF exploits such an insight to compress the information contained in KBRL's model into an approximator of fixed size. This makes it possible to build an approximation that takes into account both the difficulty of the problem and the associated computational cost. KBSF's computational complexity is linear in the number of sample transitions, which is the best one can do without discarding data. Moreover, the algorithm's simple mechanics allow for a fully incremental implementation that makes the amount of memory used independent of the number of sample transitions. The result is a kernel-based reinforcement learning algorithm that can be applied to large-scale problems in both off-line and on-line regimes. We derive upper bounds for the distance between the value functions computed by KBRL and KBSF using the same data. We also illustrate the potential of our algorithm in an extensive empirical study in which KBSF is applied to difficult tasks based on real-world data.
Efficient Learning and Planning with Compressed Predictive States
Jul 20, 2014

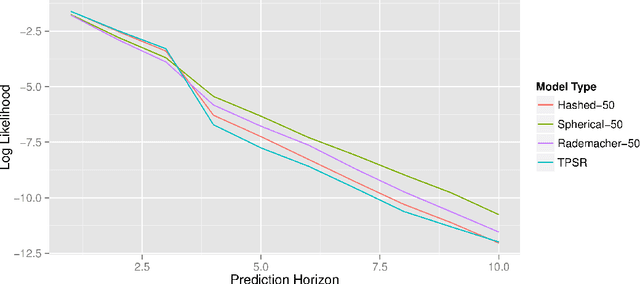
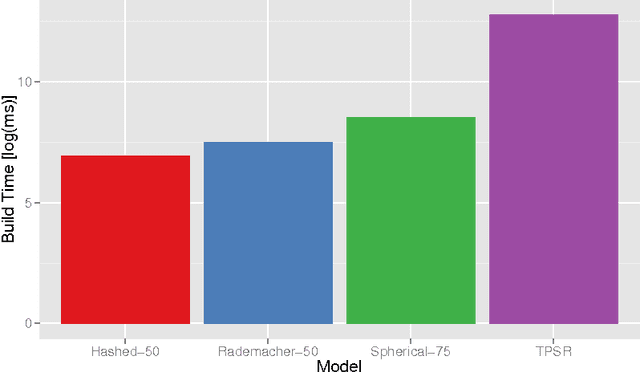
Predictive state representations (PSRs) offer an expressive framework for modelling partially observable systems. By compactly representing systems as functions of observable quantities, the PSR learning approach avoids using local-minima prone expectation-maximization and instead employs a globally optimal moment-based algorithm. Moreover, since PSRs do not require a predetermined latent state structure as an input, they offer an attractive framework for model-based reinforcement learning when agents must plan without a priori access to a system model. Unfortunately, the expressiveness of PSRs comes with significant computational cost, and this cost is a major factor inhibiting the use of PSRs in applications. In order to alleviate this shortcoming, we introduce the notion of compressed PSRs (CPSRs). The CPSR learning approach combines recent advancements in dimensionality reduction, incremental matrix decomposition, and compressed sensing. We show how this approach provides a principled avenue for learning accurate approximations of PSRs, drastically reducing the computational costs associated with learning while also providing effective regularization. Going further, we propose a planning framework which exploits these learned models. And we show that this approach facilitates model-learning and planning in large complex partially observable domains, a task that is infeasible without the principled use of compression.
Representation as a Service
Jul 09, 2014
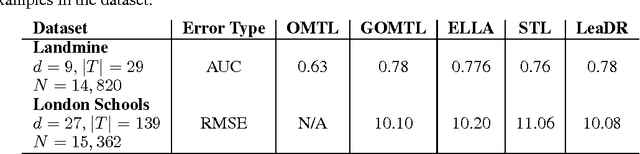
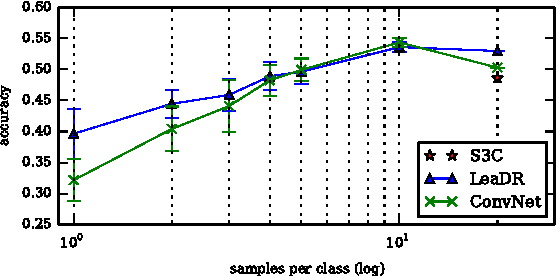
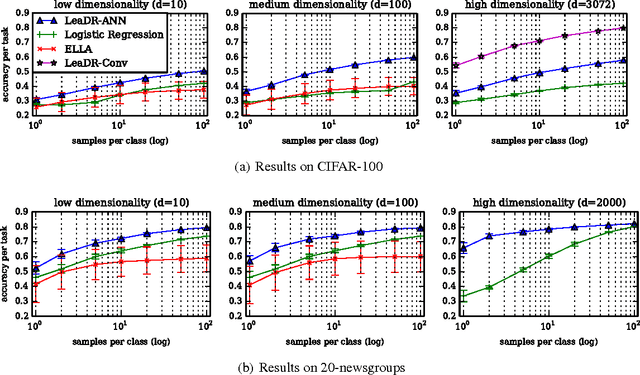
Consider a Machine Learning Service Provider (MLSP) designed to rapidly create highly accurate learners for a never-ending stream of new tasks. The challenge is to produce task-specific learners that can be trained from few labeled samples, even if tasks are not uniquely identified, and the number of tasks and input dimensionality are large. In this paper, we argue that the MLSP should exploit knowledge from previous tasks to build a good representation of the environment it is in, and more precisely, that useful representations for such a service are ones that minimize generalization error for a new hypothesis trained on a new task. We formalize this intuition with a novel method that minimizes an empirical proxy of the intra-task small-sample generalization error. We present several empirical results showing state-of-the art performance on single-task transfer, multitask learning, and the full lifelong learning problem.
Non-Deterministic Policies in Markovian Decision Processes
Jan 16, 2014
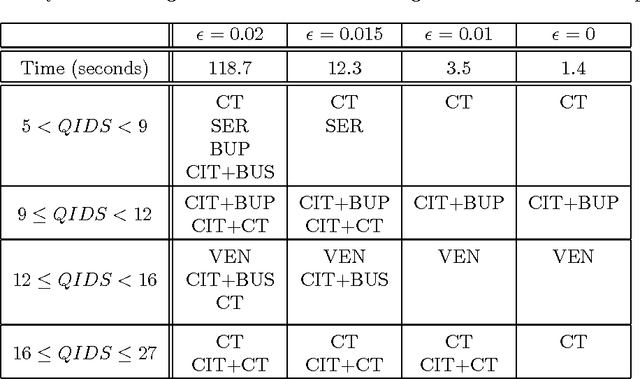
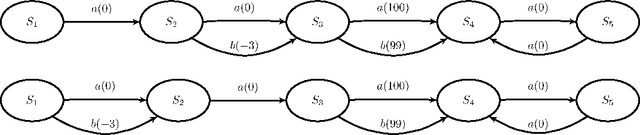
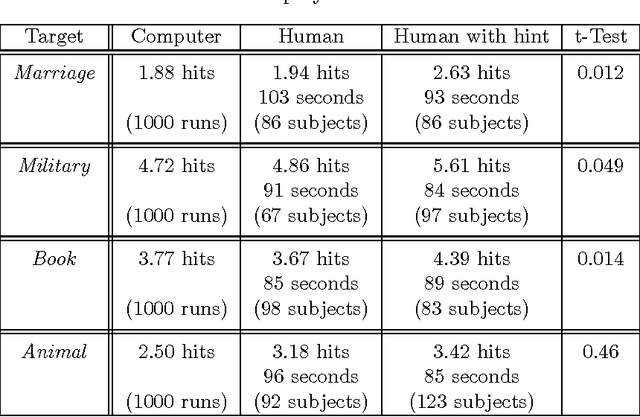
Markovian processes have long been used to model stochastic environments. Reinforcement learning has emerged as a framework to solve sequential planning and decision-making problems in such environments. In recent years, attempts were made to apply methods from reinforcement learning to construct decision support systems for action selection in Markovian environments. Although conventional methods in reinforcement learning have proved to be useful in problems concerning sequential decision-making, they cannot be applied in their current form to decision support systems, such as those in medical domains, as they suggest policies that are often highly prescriptive and leave little room for the users input. Without the ability to provide flexible guidelines, it is unlikely that these methods can gain ground with users of such systems. This paper introduces the new concept of non-deterministic policies to allow more flexibility in the users decision-making process, while constraining decisions to remain near optimal solutions. We provide two algorithms to compute non-deterministic policies in discrete domains. We study the output and running time of these method on a set of synthetic and real-world problems. In an experiment with human subjects, we show that humans assisted by hints based on non-deterministic policies outperform both human-only and computer-only agents in a web navigation task.
Online Planning Algorithms for POMDPs
Jan 15, 2014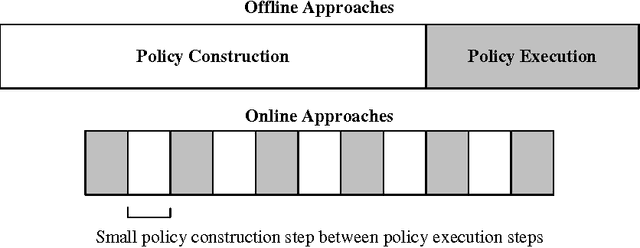
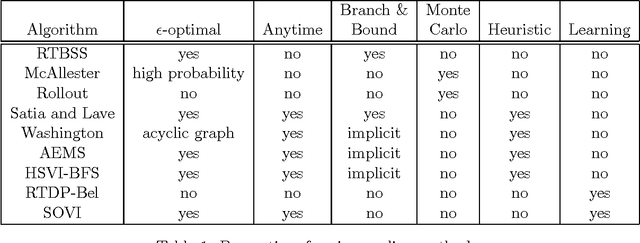
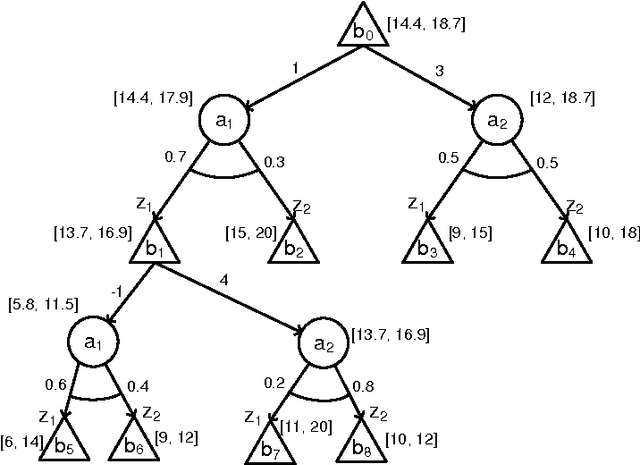

Partially Observable Markov Decision Processes (POMDPs) provide a rich framework for sequential decision-making under uncertainty in stochastic domains. However, solving a POMDP is often intractable except for small problems due to their complexity. Here, we focus on online approaches that alleviate the computational complexity by computing good local policies at each decision step during the execution. Online algorithms generally consist of a lookahead search to find the best action to execute at each time step in an environment. Our objectives here are to survey the various existing online POMDP methods, analyze their properties and discuss their advantages and disadvantages; and to thoroughly evaluate these online approaches in different environments under various metrics (return, error bound reduction, lower bound improvement). Our experimental results indicate that state-of-the-art online heuristic search methods can handle large POMDP domains efficiently.
Online Ensemble Learning for Imbalanced Data Streams
Oct 30, 2013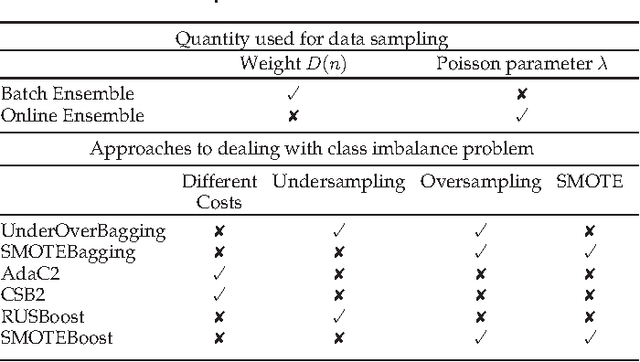
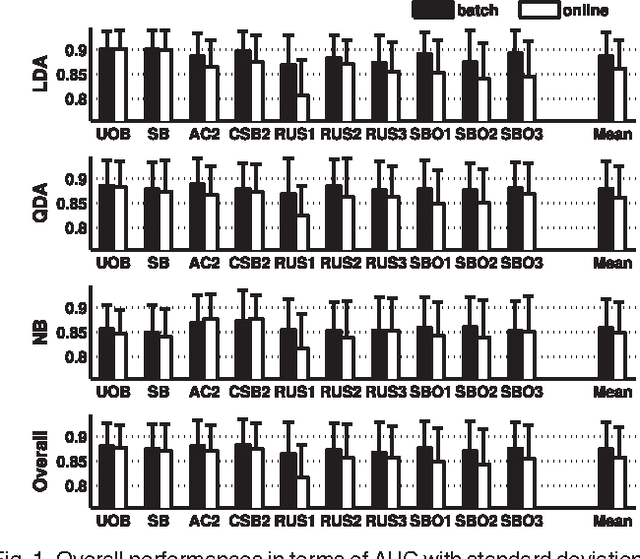
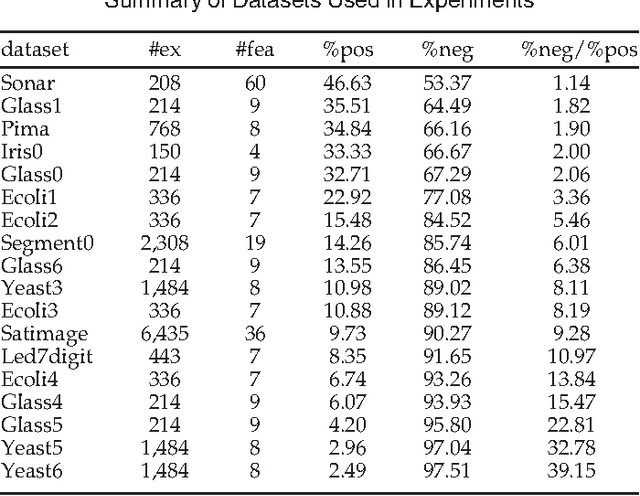
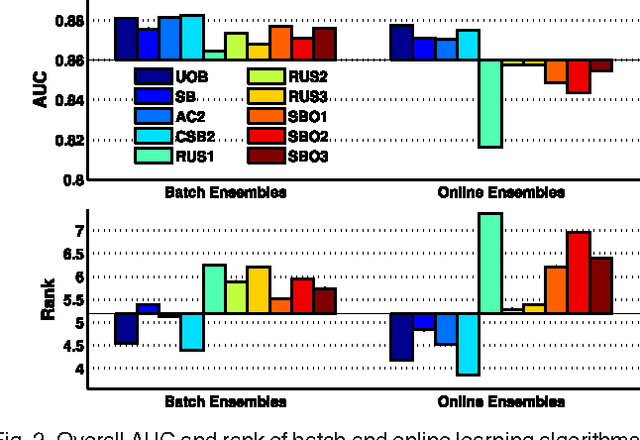
While both cost-sensitive learning and online learning have been studied extensively, the effort in simultaneously dealing with these two issues is limited. Aiming at this challenge task, a novel learning framework is proposed in this paper. The key idea is based on the fusion of online ensemble algorithms and the state of the art batch mode cost-sensitive bagging/boosting algorithms. Within this framework, two separately developed research areas are bridged together, and a batch of theoretically sound online cost-sensitive bagging and online cost-sensitive boosting algorithms are first proposed. Unlike other online cost-sensitive learning algorithms lacking theoretical analysis of asymptotic properties, the convergence of the proposed algorithms is guaranteed under certain conditions, and the experimental evidence with benchmark data sets also validates the effectiveness and efficiency of the proposed methods.
End-to-End Text Recognition with Hybrid HMM Maxout Models
Oct 07, 2013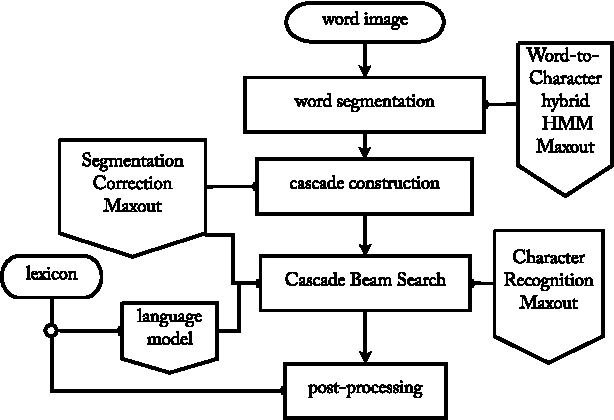
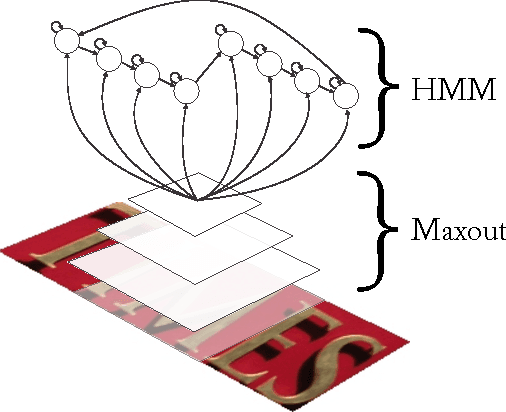
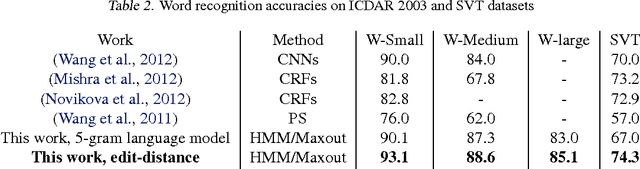

The problem of detecting and recognizing text in natural scenes has proved to be more challenging than its counterpart in documents, with most of the previous work focusing on a single part of the problem. In this work, we propose new solutions to the character and word recognition problems and then show how to combine these solutions in an end-to-end text-recognition system. We do so by leveraging the recently introduced Maxout networks along with hybrid HMM models that have proven useful for voice recognition. Using these elements, we build a tunable and highly accurate recognition system that beats state-of-the-art results on all the sub-problems for both the ICDAR 2003 and SVT benchmark datasets.
Policy-contingent abstraction for robust robot control
Oct 19, 2012
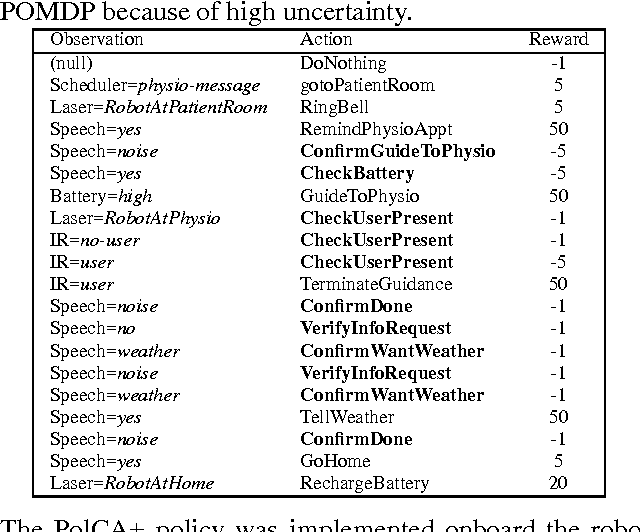
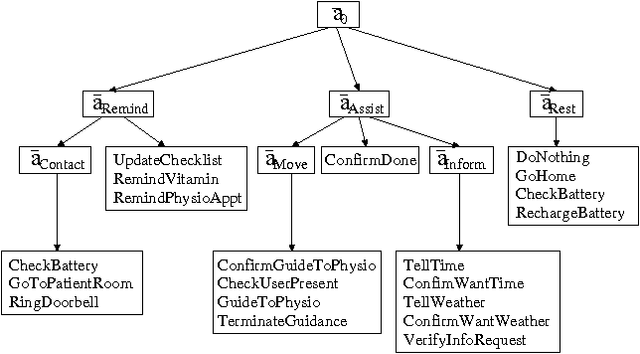
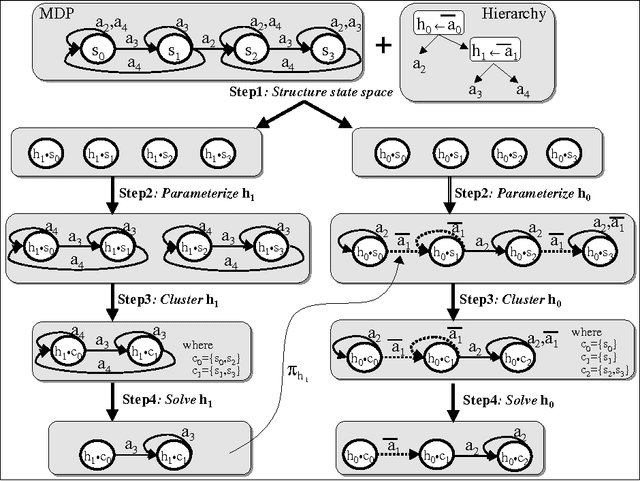
This paper presents a scalable control algorithm that enables a deployed mobile robot system to make high-level decisions under full consideration of its probabilistic belief. Our approach is based on insights from the rich literature of hierarchical controllers and hierarchical MDPs. The resulting controller has been successfully deployed in a nursing facility near Pittsburgh, PA. To the best of our knowledge, this work is a unique instance of applying POMDPs to high-level robotic control problems.
Bellman Error Based Feature Generation using Random Projections on Sparse Spaces
Sep 21, 2012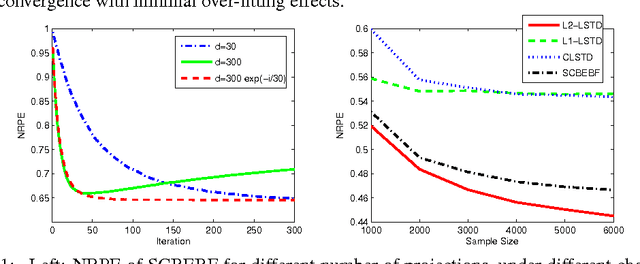
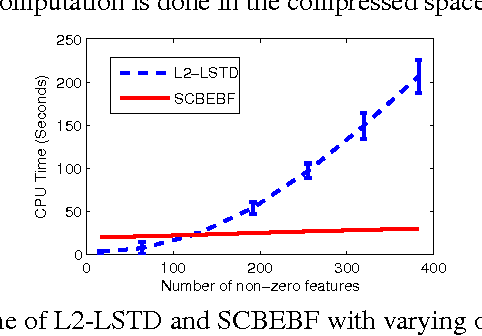
We address the problem of automatic generation of features for value function approximation. Bellman Error Basis Functions (BEBFs) have been shown to improve the error of policy evaluation with function approximation, with a convergence rate similar to that of value iteration. We propose a simple, fast and robust algorithm based on random projections to generate BEBFs for sparse feature spaces. We provide a finite sample analysis of the proposed method, and prove that projections logarithmic in the dimension of the original space are enough to guarantee contraction in the error. Empirical results demonstrate the strength of this method.