 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering of Social Media Messages for Humanitarian Aid Response during Crisis
Jul 23, 2020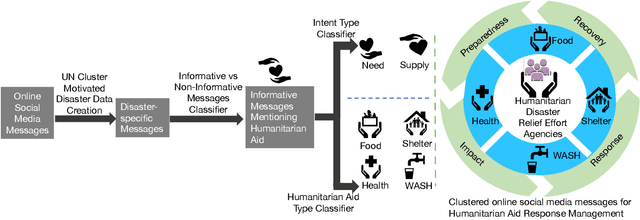
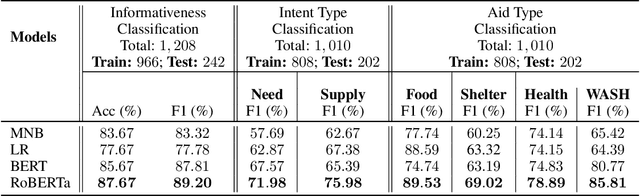


Social media has quickly grown into an essential tool for people to communicate and express their needs during crisis events. Prior work in analyzing social media data for crisis management has focused primarily on automatically identifying actionable (or, informative) crisis-related messages. In this work, we show that recent advances in Deep Learning and Natural Language Processing outperform prior approaches for the task of classifying informativeness and encourage the field to adopt them for their research or even deployment. We also extend these methods to two sub-tasks of informativeness and find that the Deep Learning methods are effective here as well.
Personalizing Grammatical Error Correction: Adaptation to Proficiency Level and L1
Jun 04, 2020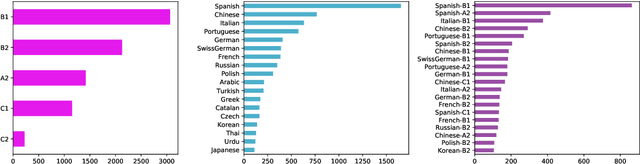
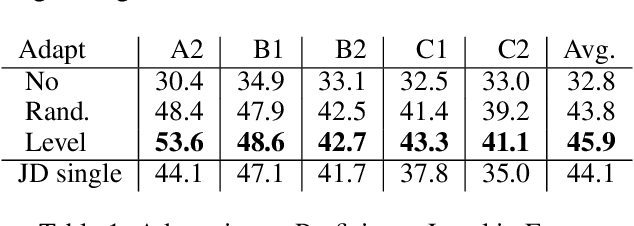
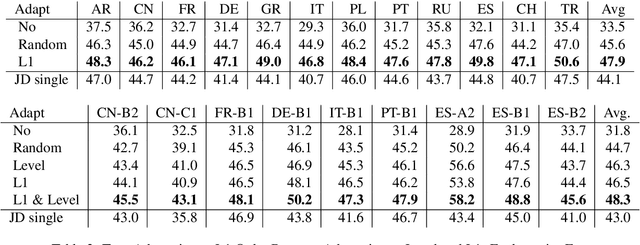
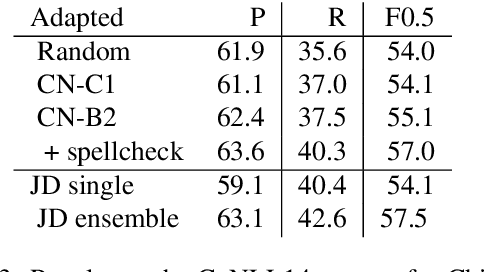
Grammar error correction (GEC) systems have become ubiquitous in a variety of software applications, and have started to approach human-level performance for some datasets. However, very little is known about how to efficiently personalize these systems to the user's characteristics, such as their proficiency level and first language, or to emerging domains of text. We present the first results on adapting a general-purpose neural GEC system to both the proficiency level and the first language of a writer, using only a few thousand annotated sentences. Our study is the broadest of its kind, covering five proficiency levels and twelve different languages, and comparing three different adaptation scenarios: adapting to the proficiency level only, to the first language only, or to both aspects simultaneously. We show that tailoring to both scenarios achieves the largest performance improvement (3.6 F0.5) relative to a strong baseline.
* Proceedings of the 2019 EMNLP Workshop W-NUT: The 5th Workshop on Noisy User-generated Text
Rhetoric, Logic, and Dialectic: Advancing Theory-based Argument Quality Assessment in Natural Language Processing
Jun 01, 2020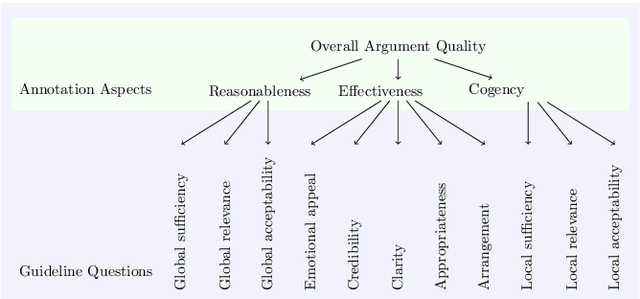

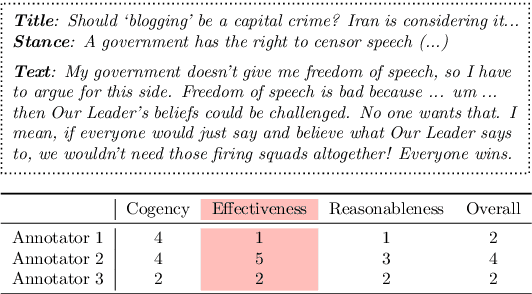
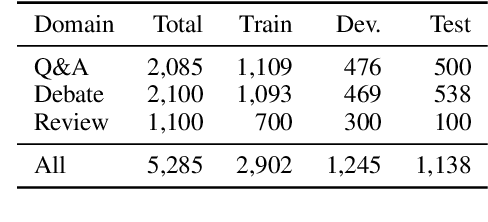
Argumentative quality is an important feature of everyday writing in many textual domains, such as online reviews and question-and-answer (Q&A) forums. Authors can improve their writing with feedback targeting individual aspects of argument quality (AQ), even though preceding work has mostly focused on assessing the overall AQ. These individual aspects are reflected in theory-based dimensions of argument quality, but automatic assessment in real-world texts is still in its infancy -- a large-scale corpus and computational models are missing. In this work, we advance theory-based argument quality research by conducting an extensive analysis covering three diverse domains of online argumentative writing: Q&A forums, debate forums, and review forums. We start with an annotation study with linguistic experts and crowd workers, resulting in the first large-scale English corpus annotated with theory-based argument quality scores, dubbed AQCorpus. Next, we propose the first computational approaches to theory-based argument quality assessment, which can serve as strong baselines for future work. Our research yields interesting findings including the feasibility of large-scale theory-based argument quality annotations, the fact that relations between theory-based argument quality dimensions can be exploited to yield performance improvements, and demonstrates the usefulness of theory-based argument quality predictions with respect to the practical AQ assessment view.
Multimodal Categorization of Crisis Events in Social Media
Apr 10, 2020
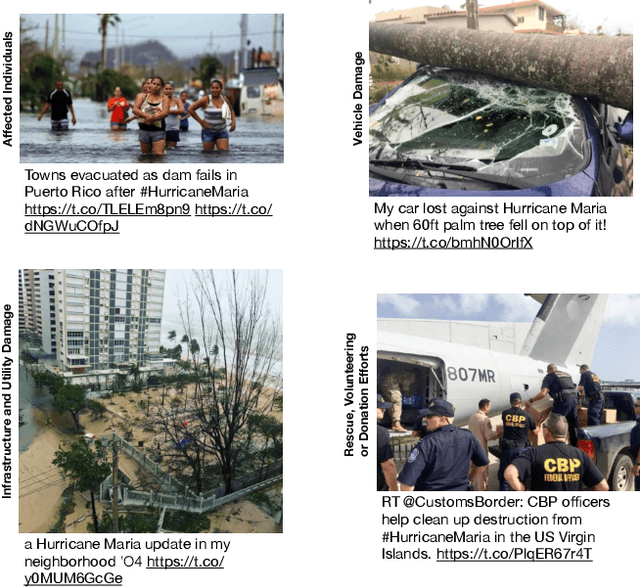
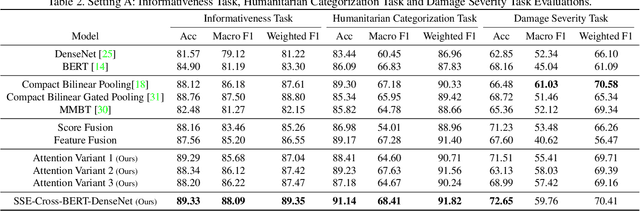
Recent developments in image classification and natural language processing, coupled with the rapid growth in social media usage, have enabled fundamental advances in detecting breaking events around the world in real-time. Emergency response is one such area that stands to gain from these advances. By processing billions of texts and images a minute, events can be automatically detected to enable emergency response workers to better assess rapidly evolving situations and deploy resources accordingly. To date, most event detection techniques in this area have focused on image-only or text-only approaches, limiting detection performance and impacting the quality of information delivered to crisis response teams. In this paper, we present a new multimodal fusion method that leverages both images and texts as input. In particular, we introduce a cross-attention module that can filter uninformative and misleading components from weak modalities on a sample by sample basis. In addition, we employ a multimodal graph-based approach to stochastically transition between embeddings of different multimodal pairs during training to better regularize the learning process as well as dealing with limited training data by constructing new matched pairs from different samples. We show that our method outperforms the unimodal approaches and strong multimodal baselines by a large margin on three crisis-related tasks.
* Conference on Computer Vision and Pattern Recognition (CVPR 2020)
The Unbearable Weight of Generating Artificial Errors for Grammatical Error Correction
Jul 21, 2019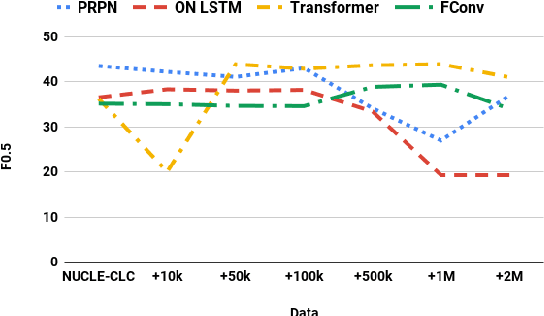
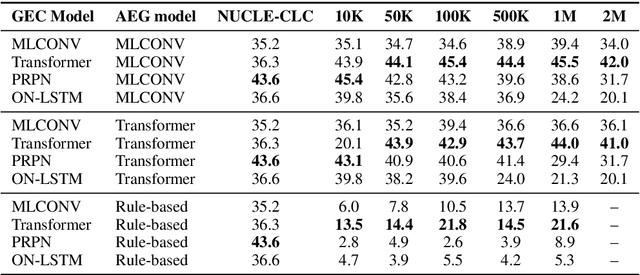

In recent years, sequence-to-sequence models have been very effective for end-to-end grammatical error correction (GEC). As creating human-annotated parallel corpus for GEC is expensive and time-consuming, there has been work on artificial corpus generation with the aim of creating sentences that contain realistic grammatical errors from grammatically correct sentences. In this paper, we investigate the impact of using recent neural models for generating errors to help neural models to correct errors. We conduct a battery of experiments on the effect of data size, models, and comparison with a rule-based approach.
This Email Could Save Your Life: Introducing the Task of Email Subject Line Generation
Jun 08, 2019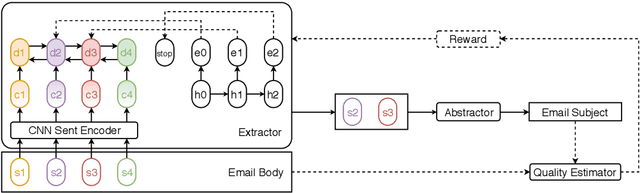

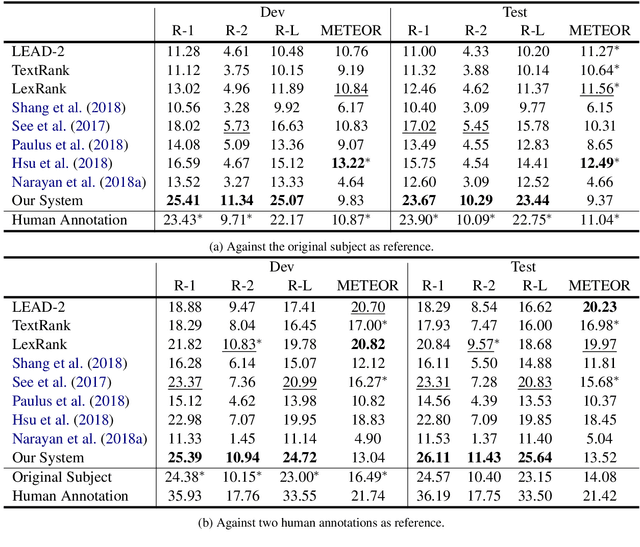
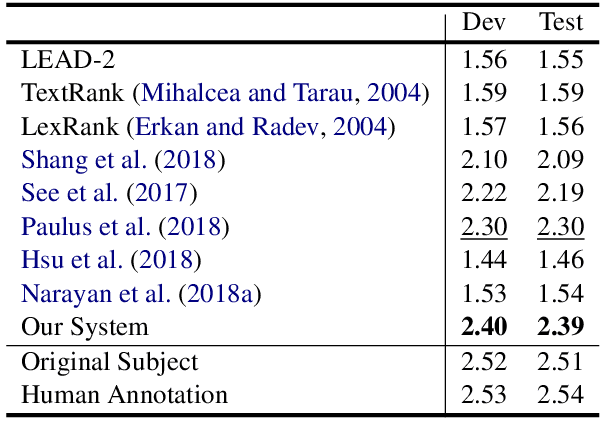
Given the overwhelming number of emails, an effective subject line becomes essential to better inform the recipient of the email's content. In this paper, we propose and study the task of email subject line generation: automatically generating an email subject line from the email body. We create the first dataset for this task and find that email subject line generation favor extremely abstractive summary which differentiates it from news headline generation or news single document summarization. We then develop a novel deep learning method and compare it to several baselines as well as recent state-of-the-art text summarization systems. We also investigate the efficacy of several automatic metrics based on correlations with human judgments and propose a new automatic evaluation metric. Our system outperforms competitive baselines given both automatic and human evaluations. To our knowledge, this is the first work to tackle the problem of effective email subject line generation.
Dialogue Act Classification with Context-Aware Self-Attention
May 06, 2019
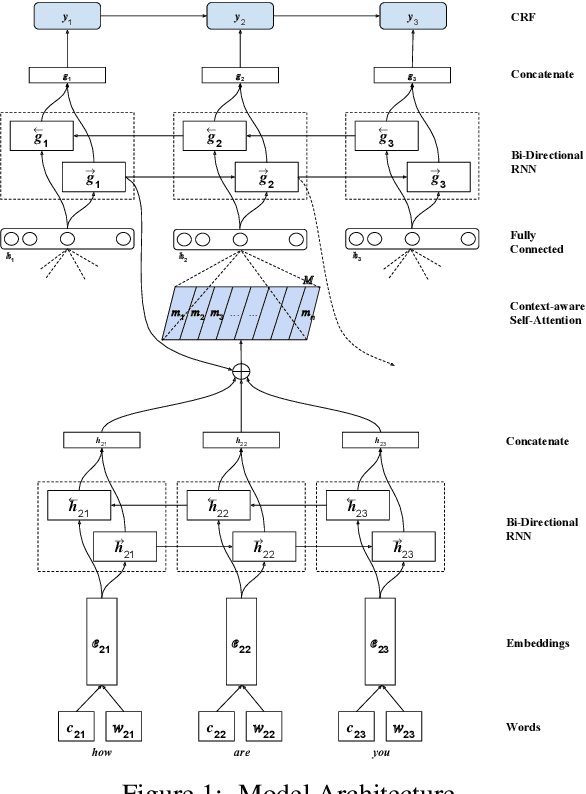

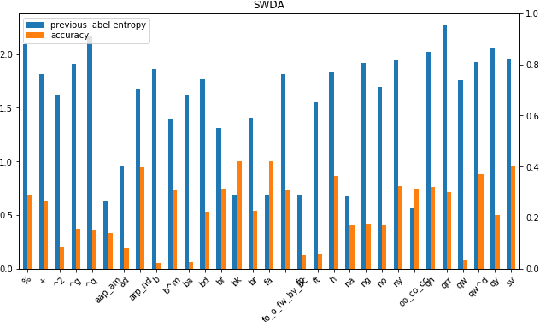
Recent work in Dialogue Act classification has treated the task as a sequence labeling problem using hierarchical deep neural networks. We build on this prior work by leveraging the effectiveness of a context-aware self-attention mechanism coupled with a hierarchical recurrent neural network. We conduct extensive evaluations on standard Dialogue Act classification datasets and show significant improvement over state-of-the-art results on the Switchboard Dialogue Act (SwDA) Corpus. We also investigate the impact of different utterance-level representation learning methods and show that our method is effective at capturing utterance-level semantic text representations while maintaining high accuracy.
How do you correct run-on sentences it's not as easy as it seems
Sep 21, 2018

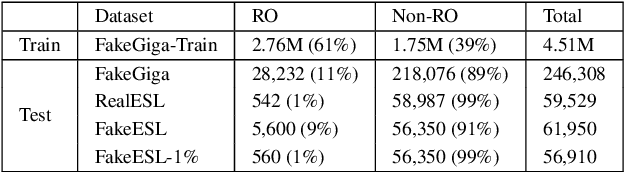
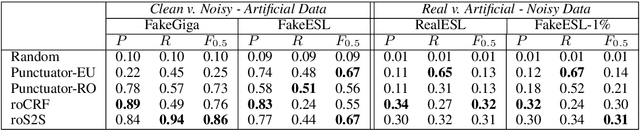
Run-on sentences are common grammatical mistakes but little research has tackled this problem to date. This work introduces two machine learning models to correct run-on sentences that outperform leading methods for related tasks, punctuation restoration and whole-sentence grammatical error correction. Due to the limited annotated data for this error, we experiment with artificially generating training data from clean newswire text. Our findings suggest artificial training data is viable for this task. We discuss implications for correcting run-ons and other types of mistakes that have low coverage in error-annotated corpora.
Discourse Coherence in the Wild: A Dataset, Evaluation and Methods
May 14, 2018
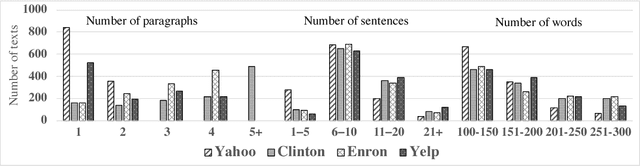
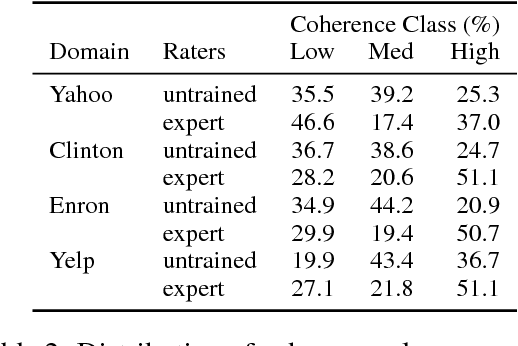
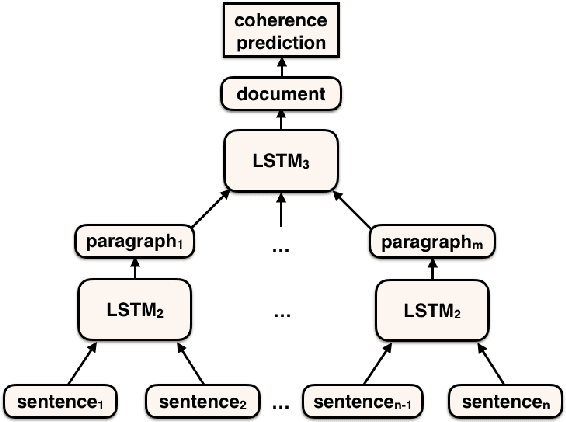
To date there has been very little work on assessing discourse coherence methods on real-world data. To address this, we present a new corpus of real-world texts (GCDC) as well as the first large-scale evaluation of leading discourse coherence algorithms. We show that neural models, including two that we introduce here (SentAvg and ParSeq), tend to perform best. We analyze these performance differences and discuss patterns we observed in low coherence texts in four domains.
Dear Sir or Madam, May I introduce the GYAFC Dataset: Corpus, Benchmarks and Metrics for Formality Style Transfer
Apr 16, 2018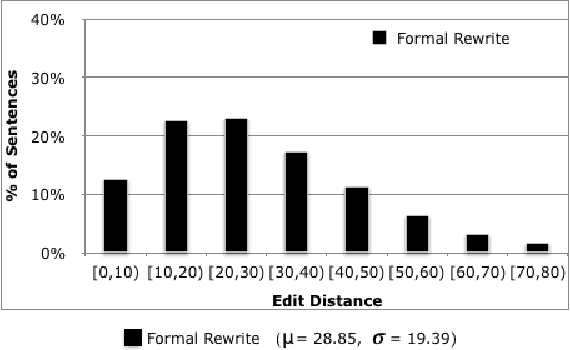
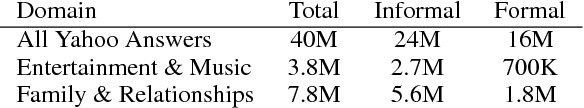
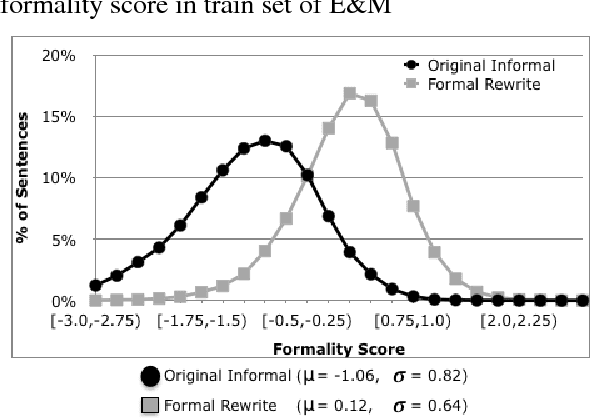

Style transfer is the task of automatically transforming a piece of text in one particular style into another. A major barrier to progress in this field has been a lack of training and evaluation datasets, as well as benchmarks and automatic metrics. In this work, we create the largest corpus for a particular stylistic transfer (formality) and show that techniques from the machine translation community can serve as strong baselines for future work. We also discuss challenges of using automatic metrics.