 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealthBench: Evaluating Large Language Models Towards Improved Human Health
May 13, 2025



We present HealthBench, an open-source benchmark measuring the performance and safety of large language models in healthcare. HealthBench consists of 5,000 multi-turn conversations between a model and an individual user or healthcare professional. Responses are evaluated using conversation-specific rubrics created by 262 physicians. Unlike previous multiple-choice or short-answer benchmarks, HealthBench enables realistic, open-ended evaluation through 48,562 unique rubric criteria spanning several health contexts (e.g., emergencies, transforming clinical data, global health) and behavioral dimensions (e.g., accuracy, instruction following, communication). HealthBench performance over the last two years reflects steady initial progress (compare GPT-3.5 Turbo's 16% to GPT-4o's 32%) and more rapid recent improvements (o3 scores 60%). Smaller models have especially improved: GPT-4.1 nano outperforms GPT-4o and is 25 times cheaper. We additionally release two HealthBench variations: HealthBench Consensus, which includes 34 particularly important dimensions of model behavior validated via physician consensus, and HealthBench Hard, where the current top score is 32%. We hope that HealthBench grounds progress towards model development and applications that benefit human health.
Disentangling and Operationalizing AI Fairness at LinkedIn
May 30, 2023Operationalizing AI fairness at LinkedIn's scale is challenging not only because there are multiple mutually incompatible definitions of fairness but also because determining what is fair depends on the specifics and context of the product where AI is deployed. Moreover, AI practitioners need clarity on what fairness expectations need to be addressed at the AI level. In this paper, we present the evolving AI fairness framework used at LinkedIn to address these three challenges. The framework disentangles AI fairness by separating out equal treatment and equitable product expectations. Rather than imposing a trade-off between these two commonly opposing interpretations of fairness, the framework provides clear guidelines for operationalizing equal AI treatment complemented with a product equity strategy. This paper focuses on the equal AI treatment component of LinkedIn's AI fairness framework, shares the principles that support it, and illustrates their application through a case study. We hope this paper will encourage other big tech companies to join us in sharing their approach to operationalizing AI fairness at scale, so that together we can keep advancing this constantly evolving field.
Counterfactual Reasoning and Learning Systems
Jul 27, 2013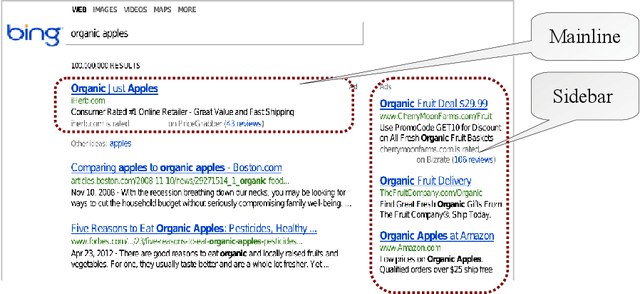
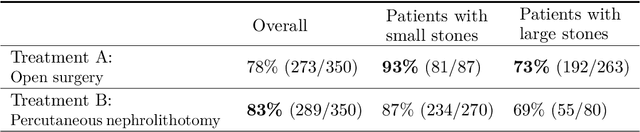

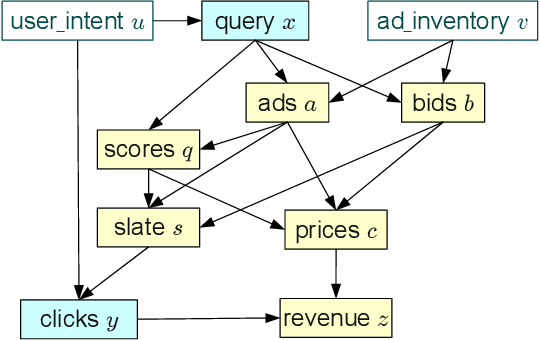
This work shows how to leverage causal inference to understand the behavior of complex learning systems interacting with their environment and predict the consequences of changes to the system. Such predictions allow both humans and algorithms to select changes that improve both the short-term and long-term performance of such systems. This work is illustrated by experiments carried out on the ad placement system associated with the Bing search engine.