 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Robust Reputation-based Group Ranking System and its Resistance to Bribery
Apr 17, 2020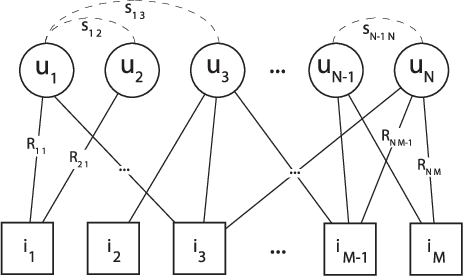
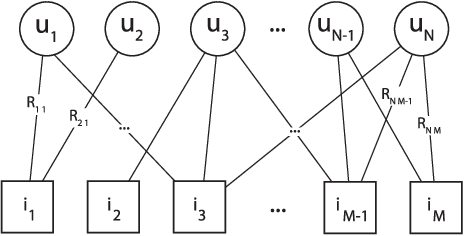
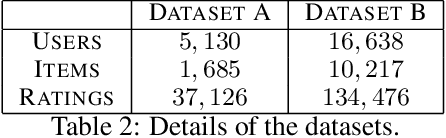
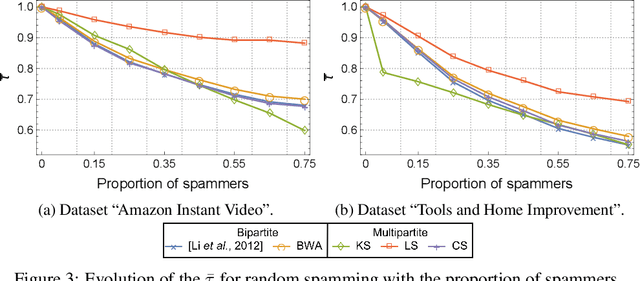
The spread of online reviews and opinions and its growing influence on people's behavior and decisions, boosted the interest to extract meaningful information from this data deluge. Hence, crowdsourced ratings of products and services gained a critical role in business and governments. Current state-of-the-art solutions rank the items with an average of the ratings expressed for an item, with a consequent lack of personalization for the users, and the exposure to attacks and spamming/spurious users. Using these ratings to group users with similar preferences might be useful to present users with items that reflect their preferences and overcome those vulnerabilities. In this paper, we propose a new reputation-based ranking system, utilizing multipartite rating subnetworks, which clusters users by their similarities using three measures, two of them based on Kolmogorov complexity. We also study its resistance to bribery and how to design optimal bribing strategies. Our system is novel in that it reflects the diversity of preferences by (possibly) assigning distinct rankings to the same item, for different groups of users. We prove the convergence and efficiency of the system. By testing it on synthetic and real data, we see that it copes better with spamming/spurious users, being more robust to attacks than state-of-the-art approaches. Also, by clustering users, the effect of bribery in the proposed multipartite ranking system is dimmed, comparing to the bipartite case.
Explain Graph Neural Networks to Understand Weighted Graph Features in Node Classification
Feb 02, 2020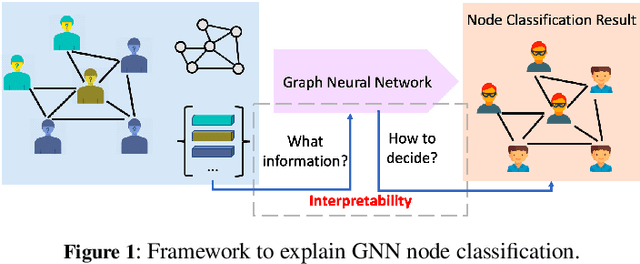
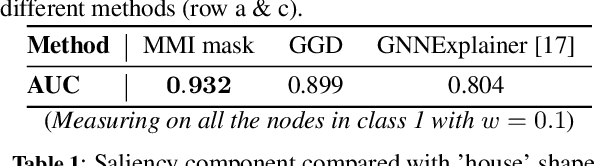
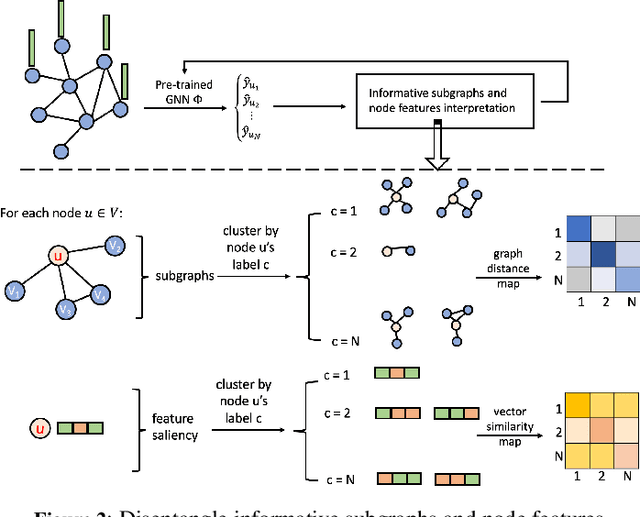

Real data collected from different applications that have additional topological structures and connection information are amenable to be represented as a weighted graph. Considering the node labeling problem, Graph Neural Networks (GNNs) is a powerful tool, which can mimic experts' decision on node labeling. GNNs combine node features, connection patterns, and graph structure by using a neural network to embed node information and pass it through edges in the graph. We want to identify the patterns in the input data used by the GNN model to make a decision and examine if the model works as we desire. However, due to the complex data representation and non-linear transformations, explaining decisions made by GNNs is challenging. In this work, we propose new graph features' explanation methods to identify the informative components and important node features. Besides, we propose a pipeline to identify the key factors used for node classification. We use four datasets (two synthetic and two real) to validate our methods. Our results demonstrate that our explanation approach can mimic data patterns used for node classification by human interpretation and disentangle different features in the graphs. Furthermore, our explanation methods can be used for understanding data, debugging GNN models, and examine model decisions.