 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Cost-Accuracy Trade-offs in Multimodal Search Relevance Judgements
Oct 25, 2024



Large Language Models (LLMs) have demonstrated potential as effective search relevance evaluators. However, there is a lack of comprehensive guidance on which models consistently perform optimally across various contexts or within specific use cases. In this paper, we assess several LLMs and Multimodal Language Models (MLLMs) in terms of their alignment with human judgments across multiple multimodal search scenarios. Our analysis investigates the trade-offs between cost and accuracy, highlighting that model performance varies significantly depending on the context. Interestingly, in smaller models, the inclusion of a visual component may hinder performance rather than enhance it. These findings highlight the complexities involved in selecting the most appropriate model for practical applications.
MKQA: A Linguistically Diverse Benchmark for Multilingual Open Domain Question Answering
Jul 30, 2020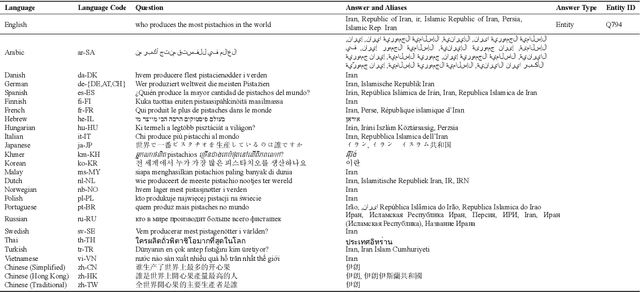
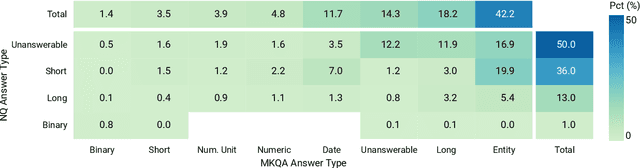
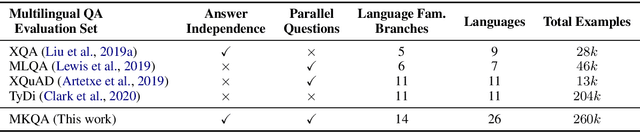
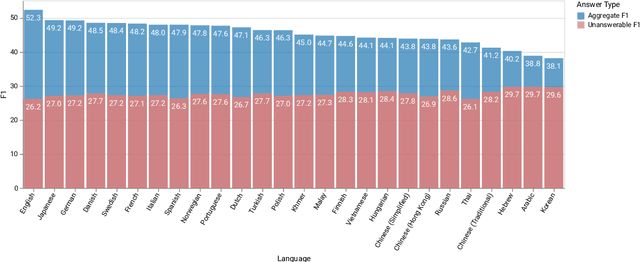
Progress in cross-lingual modeling depends on challenging, realistic, and diverse evaluation sets. We introduce Multilingual Knowledge Questions and Answers (MKQA), an open-domain question answering evaluation set comprising 10k question-answer pairs aligned across 26 typologically diverse languages (260k question-answer pairs in total). The goal of this dataset is to provide a challenging benchmark for question answering quality across a wide set of languages. Answers are based on a language-independent data representation, making results comparable across languages and independent of language-specific passages. With 26 languages, this dataset supplies the widest range of languages to-date for evaluating question answering. We benchmark state-of-the-art extractive question answering baselines, trained on Natural Questions, including Multilingual BERT, and XLM-RoBERTa, in zero shot and translation settings. Results indicate this dataset is challenging, especially in low-resource languages.
Splitting Compounds by Semantic Analogy
Sep 15, 2015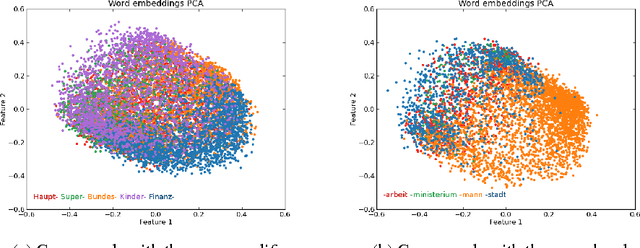


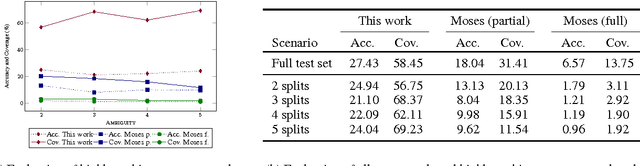
Compounding is a highly productive word-formation process in some languages that is often problematic for natural language processing applications. In this paper, we investigate whether distributional semantics in the form of word embeddings can enable a deeper, i.e., more knowledge-rich, processing of compounds than the standard string-based methods. We present an unsupervised approach that exploits regularities in the semantic vector space (based on analogies such as "bookshop is to shop as bookshelf is to shelf") to produce compound analyses of high quality. A subsequent compound splitting algorithm based on these analyses is highly effective, particularly for ambiguous compounds. German to English machine translation experiments show that this semantic analogy-based compound splitter leads to better translations than a commonly used frequency-based method.