 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Hidden Potential of CLIP in Generalizable Deepfake Detection
Mar 26, 2025



This paper tackles the challenge of detecting partially manipulated facial deepfakes, which involve subtle alterations to specific facial features while retaining the overall context, posing a greater detection difficulty than fully synthetic faces. We leverage the Contrastive Language-Image Pre-training (CLIP) model, specifically its ViT-L/14 visual encoder, to develop a generalizable detection method that performs robustly across diverse datasets and unknown forgery techniques with minimal modifications to the original model. The proposed approach utilizes parameter-efficient fine-tuning (PEFT) techniques, such as LN-tuning, to adjust a small subset of the model's parameters, preserving CLIP's pre-trained knowledge and reducing overfitting. A tailored preprocessing pipeline optimizes the method for facial images, while regularization strategies, including L2 normalization and metric learning on a hyperspherical manifold, enhance generalization. Trained on the FaceForensics++ dataset and evaluated in a cross-dataset fashion on Celeb-DF-v2, DFDC, FFIW, and others, the proposed method achieves competitive detection accuracy comparable to or outperforming much more complex state-of-the-art techniques. This work highlights the efficacy of CLIP's visual encoder in facial deepfake detection and establishes a simple, powerful baseline for future research, advancing the field of generalizable deepfake detection. The code is available at: https://github.com/yermandy/deepfake-detection
Human Pose-Constrained UV Map Estimation
Jan 15, 2025



UV map estimation is used in computer vision for detailed analysis of human posture or activity. Previous methods assign pixels to body model vertices by comparing pixel descriptors independently, without enforcing global coherence or plausibility in the UV map. We propose Pose-Constrained Continuous Surface Embeddings (PC-CSE), which integrates estimated 2D human pose into the pixel-to-vertex assignment process. The pose provides global anatomical constraints, ensuring that UV maps remain coherent while preserving local precision. Evaluation on DensePose COCO demonstrates consistent improvement, regardless of the chosen 2D human pose model. Whole-body poses offer better constraints by incorporating additional details about the hands and feet. Conditioning UV maps with human pose reduces invalid mappings and enhances anatomical plausibility. In addition, we highlight inconsistencies in the ground-truth annotations.
Three Things to Know about Deep Metric Learning
Dec 17, 2024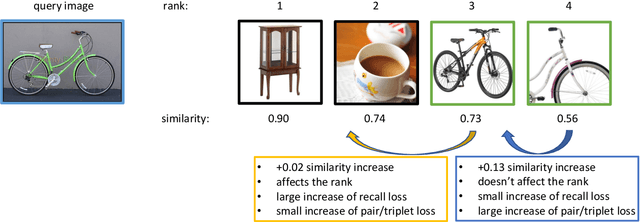
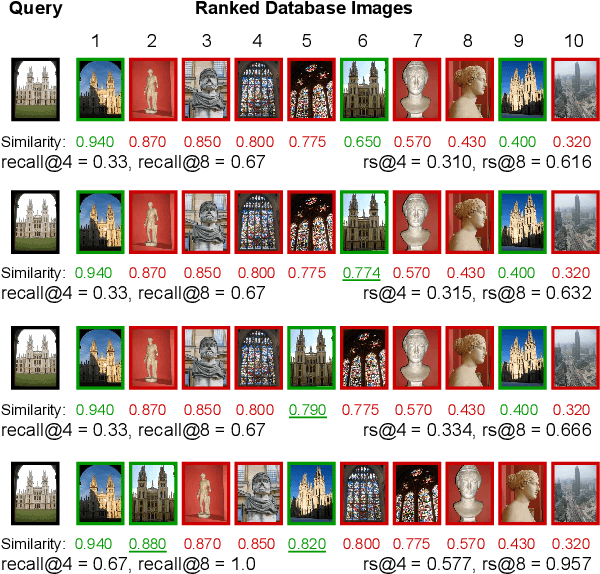

This paper addresses supervised deep metric learning for open-set image retrieval, focusing on three key aspects: the loss function, mixup regularization, and model initialization. In deep metric learning, optimizing the retrieval evaluation metric, recall@k, via gradient descent is desirable but challenging due to its non-differentiable nature. To overcome this, we propose a differentiable surrogate loss that is computed on large batches, nearly equivalent to the entire training set. This computationally intensive process is made feasible through an implementation that bypasses the GPU memory limitations. Additionally, we introduce an efficient mixup regularization technique that operates on pairwise scalar similarities, effectively increasing the batch size even further. The training process is further enhanced by initializing the vision encoder using foundational models, which are pre-trained on large-scale datasets. Through a systematic study of these components, we demonstrate that their synergy enables large models to nearly solve popular benchmarks.
ProbPose: A Probabilistic Approach to 2D Human Pose Estimation
Dec 03, 2024Current Human Pose Estimation methods have achieved significant improvements. However, state-of-the-art models ignore out-of-image keypoints and use uncalibrated heatmaps as keypoint location representations. To address these limitations, we propose ProbPose, which predicts for each keypoint: a calibrated probability of keypoint presence at each location in the activation window, the probability of being outside of it, and its predicted visibility. To address the lack of evaluation protocols for out-of-image keypoints, we introduce the CropCOCO dataset and the Extended OKS (Ex-OKS) metric, which extends OKS to out-of-image points. Tested on COCO, CropCOCO, and OCHuman, ProbPose shows significant gains in out-of-image keypoint localization while also improving in-image localization through data augmentation. Additionally, the model improves robustness along the edges of the bounding box and offers better flexibility in keypoint evaluation. The code and models are available on https://mirapurkrabek.github.io/ProbPose/ for research purposes.
Detection, Pose Estimation and Segmentation for Multiple Bodies: Closing the Virtuous Circle
Dec 02, 2024



Human pose estimation methods work well on separated people but struggle with multi-body scenarios. Recent work has addressed this problem by conditioning pose estimation with detected bounding boxes or bottom-up-estimated poses. Unfortunately, all of these approaches overlooked segmentation masks and their connection to estimated keypoints. We condition pose estimation model by segmentation masks instead of bounding boxes to improve instance separation. This improves top-down pose estimation in multi-body scenarios but does not fix detection errors. Consequently, we develop BBox-Mask-Pose (BMP), integrating detection, segmentation and pose estimation into self-improving feedback loop. We adapt detector and pose estimation model for conditioning by instance masks and use Segment Anything as pose-to-mask model to close the circle. With only small models, BMP is superior to top-down methods on OCHuman dataset and to detector-free methods on COCO dataset, combining the best from both approaches and matching state of art performance in both settings. Code is available on https://mirapurkrabek.github.io/BBox-Mask-Pose.
Flaws of ImageNet, Computer Vision's Favourite Dataset
Nov 26, 2024Since its release, ImageNet-1k dataset has become a gold standard for evaluating model performance. It has served as the foundation for numerous other datasets and training tasks in computer vision. As models have improved in accuracy, issues related to label correctness have become increasingly apparent. In this blog post, we analyze the issues in the ImageNet-1k dataset, including incorrect labels, overlapping or ambiguous class definitions, training-evaluation domain shifts, and image duplicates. The solutions for some problems are straightforward. For others, we hope to start a broader conversation about refining this influential dataset to better serve future research.
Segment to Recognize Robustly -- Enhancing Recognition by Image Decomposition
Nov 24, 2024



In image recognition, both foreground (FG) and background (BG) play an important role; however, standard deep image recognition often leads to unintended over-reliance on the BG, limiting model robustness in real-world deployment settings. Current solutions mainly suppress the BG, sacrificing BG information for improved generalization. We propose "Segment to Recognize Robustly" (S2R^2), a novel recognition approach which decouples the FG and BG modelling and combines them in a simple, robust, and interpretable manner. S2R^2 leverages recent advances in zero-shot segmentation to isolate the FG and the BG before or during recognition. By combining FG and BG, potentially also with a standard full-image classifier, S2R^2 achieves state-of-the-art results on in-domain data while maintaining robustness to BG shifts. The results confirm that segmentation before recognition is now possible.
MFTIQ: Multi-Flow Tracker with Independent Matching Quality Estimation
Nov 14, 2024



In this work, we present MFTIQ, a novel dense long-term tracking model that advances the Multi-Flow Tracker (MFT) framework to address challenges in point-level visual tracking in video sequences. MFTIQ builds upon the flow-chaining concepts of MFT, integrating an Independent Quality (IQ) module that separates correspondence quality estimation from optical flow computations. This decoupling significantly enhances the accuracy and flexibility of the tracking process, allowing MFTIQ to maintain reliable trajectory predictions even in scenarios of prolonged occlusions and complex dynamics. Designed to be "plug-and-play", MFTIQ can be employed with any off-the-shelf optical flow method without the need for fine-tuning or architectural modifications. Experimental validations on the TAP-Vid Davis dataset show that MFTIQ with RoMa optical flow not only surpasses MFT but also performs comparably to state-of-the-art trackers while having substantially faster processing speed. Code and models available at https://github.com/serycjon/MFTIQ .
FungiTastic: A multi-modal dataset and benchmark for image categorization
Aug 24, 2024



We introduce a new, highly challenging benchmark and a dataset -- FungiTastic -- based on data continuously collected over a twenty-year span. The dataset originates in fungal records labeled and curated by experts. It consists of about 350k multi-modal observations that include more than 650k photographs from 5k fine-grained categories and diverse accompanying information, e.g., acquisition metadata, satellite images, and body part segmentation. FungiTastic is the only benchmark that includes a test set with partially DNA-sequenced ground truth of unprecedented label reliability. The benchmark is designed to support (i) standard close-set classification, (ii) open-set classification, (iii) multi-modal classification, (iv) few-shot learning, (v) domain shift, and many more. We provide baseline methods tailored for almost all the use-cases. We provide a multitude of ready-to-use pre-trained models on HuggingFace and a framework for model training. A comprehensive documentation describing the dataset features and the baselines are available at https://bohemianvra.github.io/FungiTastic/ and https://www.kaggle.com/datasets/picekl/fungitastic.
Animal Identification with Independent Foreground and Background Modeling
Aug 23, 2024



We propose a method that robustly exploits background and foreground in visual identification of individual animals. Experiments show that their automatic separation, made easy with methods like Segment Anything, together with independent foreground and background-related modeling, improves results. The two predictions are combined in a principled way, thanks to novel Per-Instance Temperature Scaling that helps the classifier to deal with appearance ambiguities in training and to produce calibrated outputs in the inference phase. For identity prediction from the background, we propose novel spatial and temporal models. On two problems, the relative error w.r.t. the baseline was reduced by 22.3% and 8.8%, respectively. For cases where objects appear in new locations, an example of background drift, accuracy doubles.