 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntraShuffler: A Privacy Preserving Framework for Heterogeneous DP Federated Learning
Jun 01, 2026Heterogeneous Differential Privacy (HDP) in Federated Learning (FL) allows clients to select individual privacy budgets ($\varepsilon_i$) according to institutional policies and data sensitivity. In practice, many HDP-FL systems employ $\varepsilon$-aware server aggregation to improve model utility by re-weighting client updates according to their declared privacy budgets. However, gradient updates in FL retain structural patterns induced by non-independent and identically-distributed (non-IID) data, and these additional signals exposed by $\varepsilon$-aware aggregation create new opportunities for inference by an honest-but-curious server. In this work, we first show that a server equipped with gradient denoising and surrogate modeling can mount a \emph{Privacy Inference Attack} that infers distributional attributes of clients and links updates from the same client across training rounds, measured via surrogate inference accuracy and linkage success, under realistic knowledge constraints. The Shuffle-Model has been widely studied as a defense against such inference risks by anonymizing update sources, but it is fundamentally incompatible with HDP-FL $\varepsilon$-aware aggregation. To address this challenge, we propose \textbf{IntraShuffler}, a middleware defense framework designed for HDP-FL systems. IntraShuffler introduces a privacy-aware shuffling mechanism that groups clients into privacy-compatible buckets and performs parameter-level shuffling within each bucket to disrupt persistent gradient structure while preserving $\varepsilon$-aware aggregation. Experiments across four different datasets show that IntraShuffler reduces gradient recoverability by over 60% and decreases surrogate inference accuracy from 0.78 to 0.33 while maintaining comparable model utility across multiple FL aggregation rules.
Accuracy is Not Enough: Poisoning Interpretability in Federated Learning via Color Skew
Nov 18, 2025As machine learning models are increasingly deployed in safety-critical domains, visual explanation techniques have become essential tools for supporting transparency. In this work, we reveal a new class of attacks that compromise model interpretability without affecting accuracy. Specifically, we show that small color perturbations applied by adversarial clients in a federated learning setting can shift a model's saliency maps away from semantically meaningful regions while keeping the prediction unchanged. The proposed saliency-aware attack framework, called Chromatic Perturbation Module, systematically crafts adversarial examples by altering the color contrast between foreground and background in a way that disrupts explanation fidelity. These perturbations accumulate across training rounds, poisoning the global model's internal feature attributions in a stealthy and persistent manner. Our findings challenge a common assumption in model auditing that correct predictions imply faithful explanations and demonstrate that interpretability itself can be an attack surface. We evaluate this vulnerability across multiple datasets and show that standard training pipelines are insufficient to detect or mitigate explanation degradation, especially in the federated learning setting, where subtle color perturbations are harder to discern. Our attack reduces peak activation overlap in Grad-CAM explanations by up to 35% while preserving classification accuracy above 96% on all evaluated datasets.
Smart Driver Monitoring Robotic System to Enhance Road Safety : A Comprehensive Review
Jan 28, 2024The future of transportation is being shaped by technology, and one revolutionary step in improving road safety is the incorporation of robotic systems into driver monitoring infrastructure. This literature review explores the current landscape of driver monitoring systems, ranging from traditional physiological parameter monitoring to advanced technologies such as facial recognition to steering analysis. Exploring the challenges faced by existing systems, the review then investigates the integration of robots as intelligent entities within this framework. These robotic systems, equipped with artificial intelligence and sophisticated sensors, not only monitor but actively engage with the driver, addressing cognitive and emotional states in real-time. The synthesis of existing research reveals a dynamic interplay between human and machine, offering promising avenues for innovation in adaptive, personalized, and ethically responsible human-robot interactions for driver monitoring. This review establishes a groundwork for comprehending the intricacies and potential avenues within this dynamic field. It encourages further investigation and advancement at the intersection of human-robot interaction and automotive safety, introducing a novel direction. This involves various sections detailing technological enhancements that can be integrated to propose an innovative and improved driver monitoring system.
Towards Adversarial-Resilient Deep Neural Networks for False Data Injection Attack Detection in Power Grids
Feb 17, 2021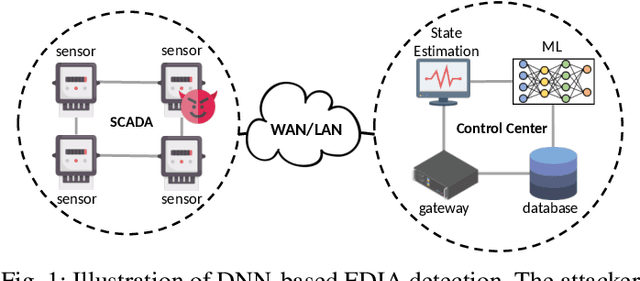
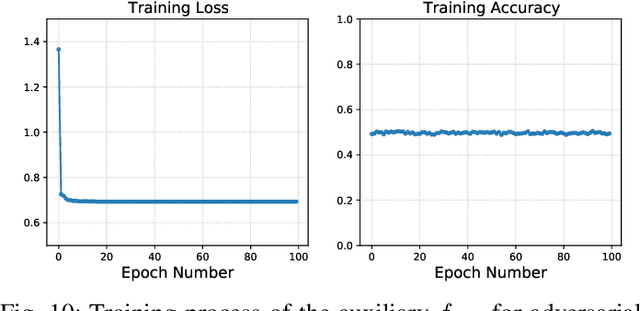
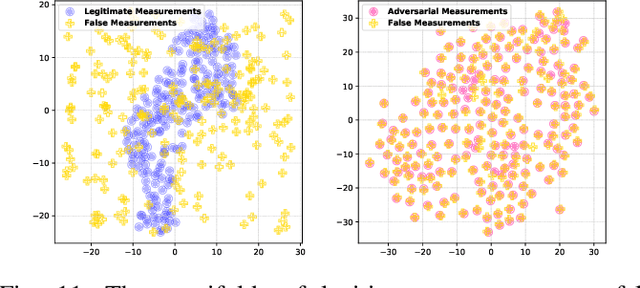
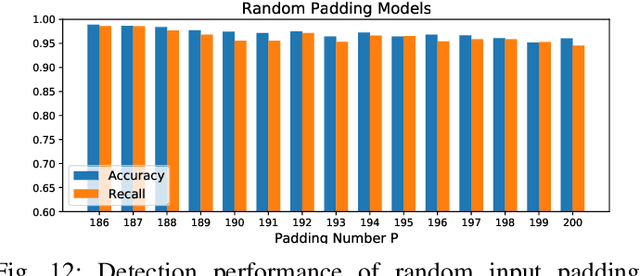
False data injection attack (FDIA) is a critical security issue in power system state estimation. In recent years, machine learning (ML) techniques, especially deep neural networks (DNNs), have been proposed in the literature for FDIA detection. However, they have not considered the risk of adversarial attacks, which were shown to be threatening to DNN's reliability in different ML applications. In this paper, we evaluate the vulnerability of DNNs used for FDIA detection through adversarial attacks and study the defensive approaches. We analyze several representative adversarial defense mechanisms and demonstrate that they have intrinsic limitations in FDIA detection. We then design an adversarial-resilient DNN detection framework for FDIA by introducing random input padding in both the training and inference phases. Extensive simulations based on an IEEE standard power system show that our framework greatly reduces the effectiveness of adversarial attacks while having little impact on the detection performance of the DNNs.
Exploiting Vulnerabilities of Deep Learning-based Energy Theft Detection in AMI through Adversarial Attacks
Oct 16, 2020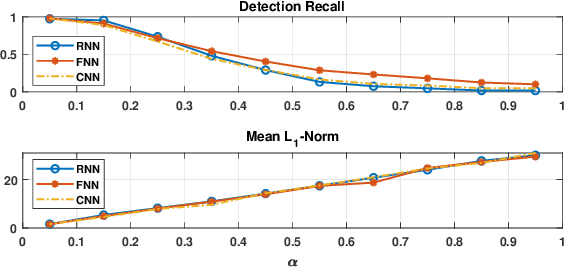
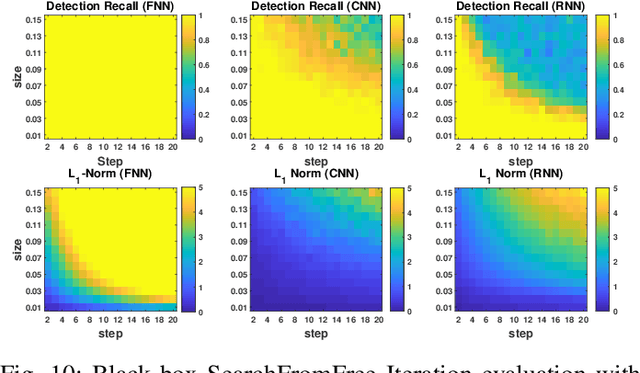
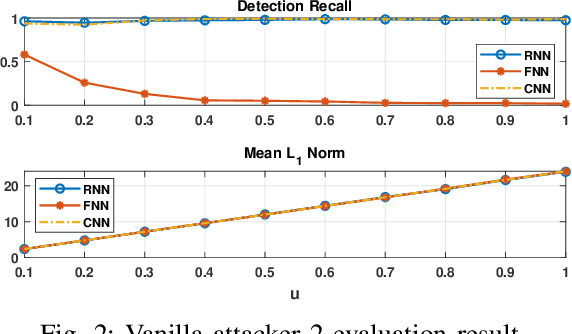
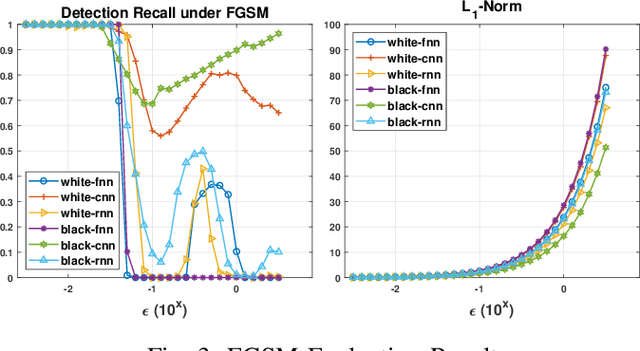
Effective detection of energy theft can prevent revenue losses of utility companies and is also important for smart grid security. In recent years, enabled by the massive fine-grained smart meter data, deep learning (DL) approaches are becoming popular in the literature to detect energy theft in the advanced metering infrastructure (AMI). However, as neural networks are shown to be vulnerable to adversarial examples, the security of the DL models is of concern. In this work, we study the vulnerabilities of DL-based energy theft detection through adversarial attacks, including single-step attacks and iterative attacks. From the attacker's point of view, we design the \textit{SearchFromFree} framework that consists of 1) a randomly adversarial measurement initialization approach to maximize the stolen profit and 2) a step-size searching scheme to increase the performance of black-box iterative attacks. The evaluation based on three types of neural networks shows that the adversarial attacker can report extremely low consumption measurements to the utility without being detected by the DL models. We finally discuss the potential defense mechanisms against adversarial attacks in energy theft detection.
SearchFromFree: Adversarial Measurements for Machine Learning-based Energy Theft Detection
Jun 02, 2020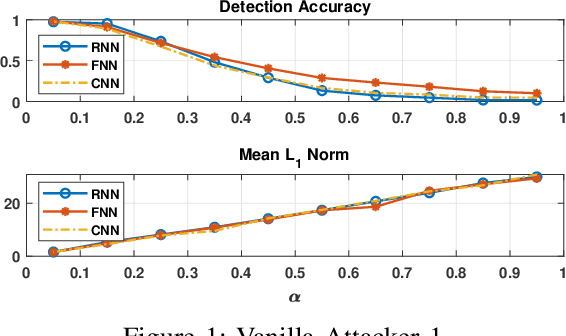
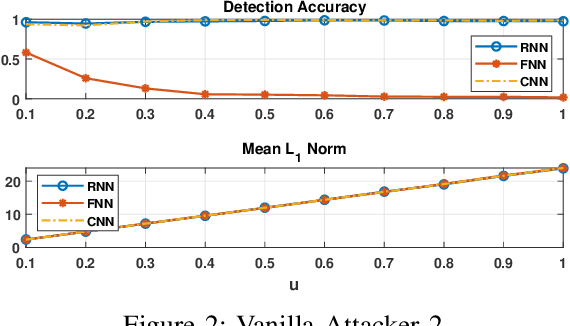
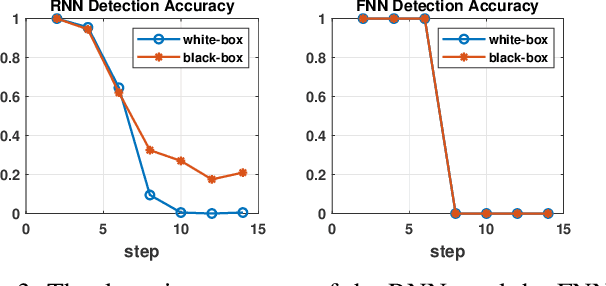
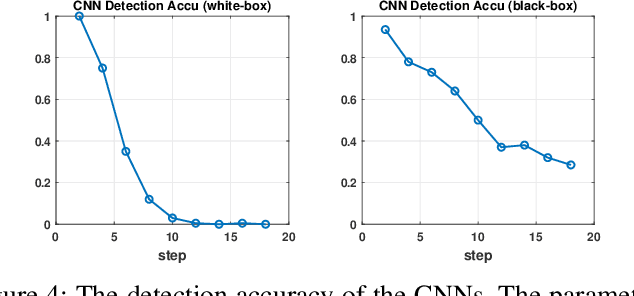
Energy theft causes large economic losses to utility companies around the world. In recent years, energy theft detection approaches based on machine learning (ML) techniques, especially neural networks, are becoming popular in the research community and shown to achieve state-of-the-art detection performance. However, in this work, we demonstrate that the well-trained ML models for energy theft detection are highly vulnerable to adversarial attacks. In particular, we design an adversarial measurement generation approach that enables the attacker to report extremely low power consumption measurements to utilities while bypassing the ML energy theft detection. We evaluate our approach with three kinds of neural networks based on a real-world smart meter dataset. The evaluation results demonstrate that our approach is able to significantly decrease the ML models' detection accuracy, even for black-box attackers.
ConAML: Constrained Adversarial Machine Learning for Cyber-Physical Systems
Mar 12, 2020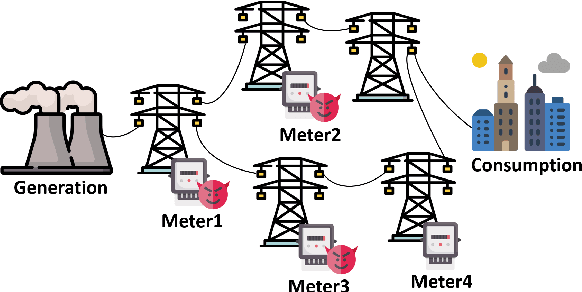
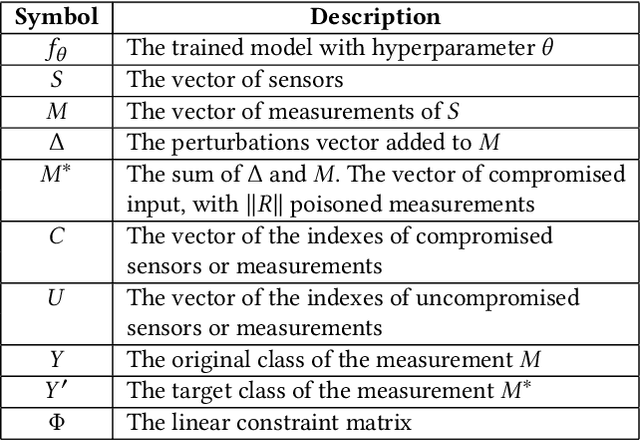
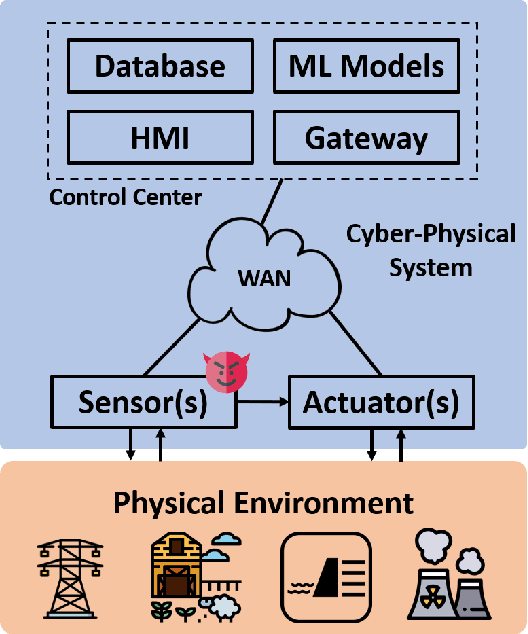

Recent research demonstrated that the superficially well-trained machine learning (ML) models are highly vulnerable to adversarial examples. As ML techniques are rapidly employed in cyber-physical systems (CPSs), the security of these applications is of concern. However, current studies on adversarial machine learning (AML) mainly focus on computer vision and related fields. The risks the adversarial examples can bring to the CPS applications have not been well investigated. In particular, due to the distributed property of data sources and the inherent physical constraints imposed by CPSs, the widely-used threat models in previous research and the state-of-the-art AML algorithms are no longer practical when applied to CPS applications. We study the vulnerabilities of ML applied in CPSs by proposing Constrained Adversarial Machine Learning (ConAML), which generates adversarial examples used as ML model input that meet the intrinsic constraints of the physical systems. We first summarize the difference between AML in CPSs and AML in existing cyber systems and propose a general threat model for ConAML. We then design a best-effort search algorithm to iteratively generate adversarial examples with linear physical constraints. As proofs of concept, we evaluate the vulnerabilities of ML models used in the electric power grid and water treatment systems. The results show that our ConAML algorithms can effectively generate adversarial examples which significantly decrease the performance of the ML models even under practical physical constraints.