 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapted End-to-End Coreference Resolution System for Anaphoric Identities in Dialogues
Sep 01, 2021

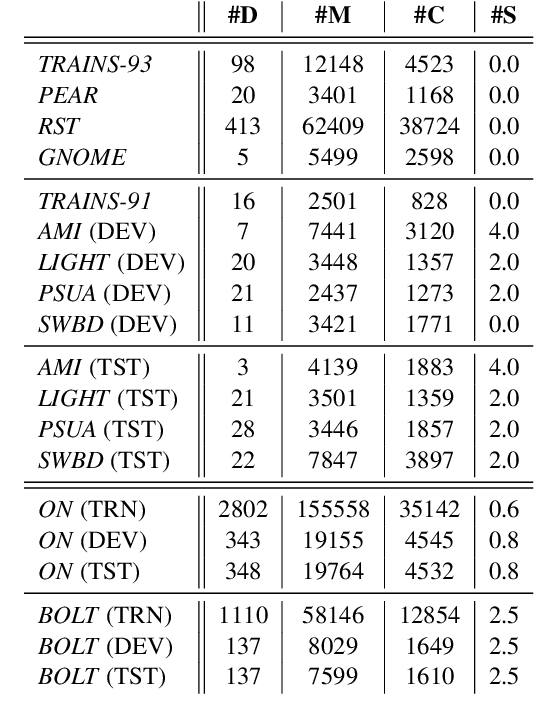
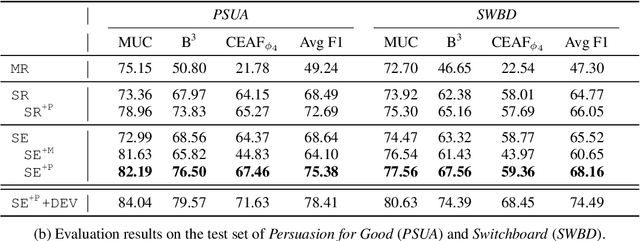
We present an effective system adapted from the end-to-end neural coreference resolution model, targeting on the task of anaphora resolution in dialogues. Three aspects are specifically addressed in our approach, including the support of singletons, encoding speakers and turns throughout dialogue interactions, and knowledge transfer utilizing existing resources. Despite the simplicity of our adaptation strategies, they are shown to bring significant impact to the final performance, with up to 27 F1 improvement over the baseline. Our final system ranks the 1st place on the leaderboard of the anaphora resolution track in the CRAC 2021 shared task, and achieves the best evaluation results on all four datasets.
Levi Graph AMR Parser using Heterogeneous Attention
Jul 09, 2021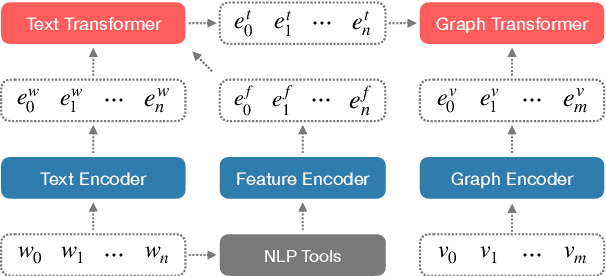
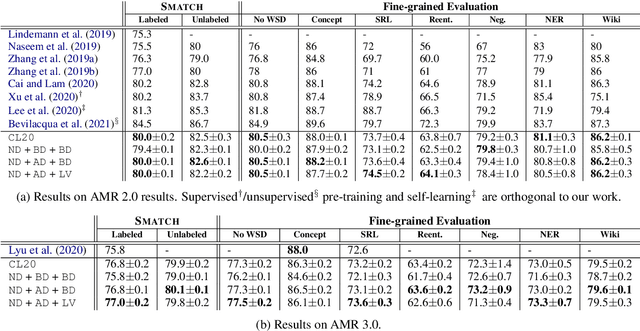
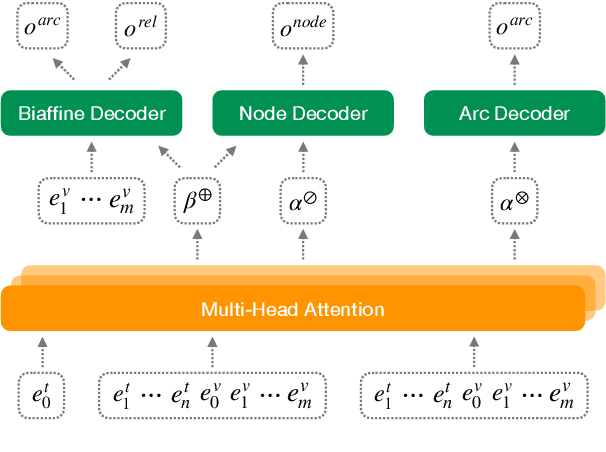
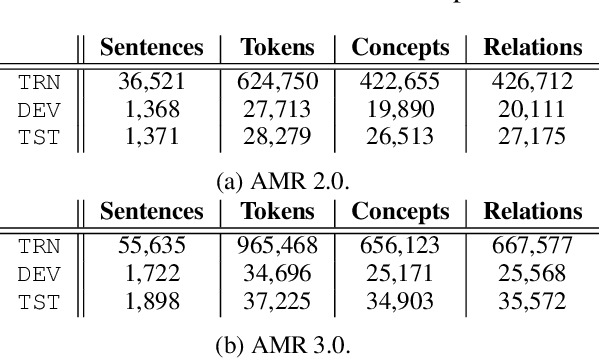
Coupled with biaffine decoders, transformers have been effectively adapted to text-to-graph transduction and achieved state-of-the-art performance on AMR parsing. Many prior works, however, rely on the biaffine decoder for either or both arc and label predictions although most features used by the decoder may be learned by the transformer already. This paper presents a novel approach to AMR parsing by combining heterogeneous data (tokens, concepts, labels) as one input to a transformer to learn attention, and use only attention matrices from the transformer to predict all elements in AMR graphs (concepts, arcs, labels). Although our models use significantly fewer parameters than the previous state-of-the-art graph parser, they show similar or better accuracy on AMR 2.0 and 3.0.
View Distillation with Unlabeled Data for Extracting Adverse Drug Effects from User-Generated Data
May 24, 2021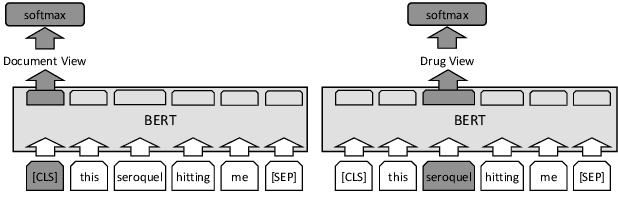
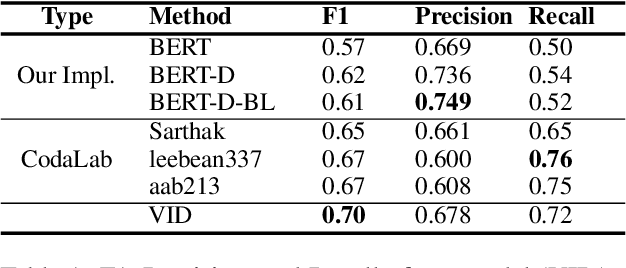
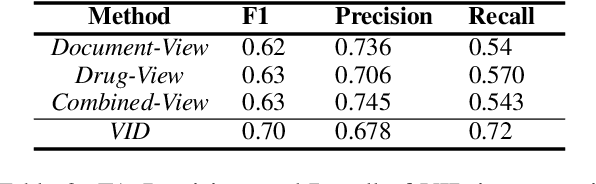
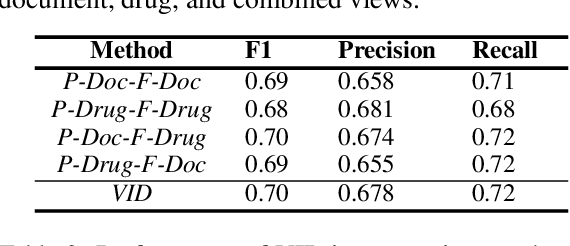
We present an algorithm based on multi-layer transformers for identifying Adverse Drug Reactions (ADR) in social media data. Our model relies on the properties of the problem and the characteristics of contextual word embeddings to extract two views from documents. Then a classifier is trained on each view to label a set of unlabeled documents to be used as an initializer for a new classifier in the other view. Finally, the initialized classifier in each view is further trained using the initial training examples. We evaluated our model in the largest publicly available ADR dataset. The experiments testify that our model significantly outperforms the transformer-based models pretrained on domain-specific data.
Evaluation of Unsupervised Entity and Event Salience Estimation
Apr 14, 2021
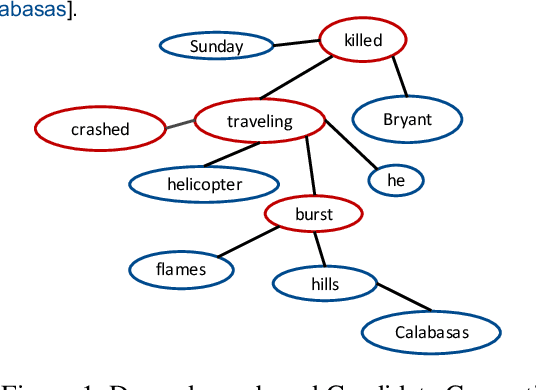
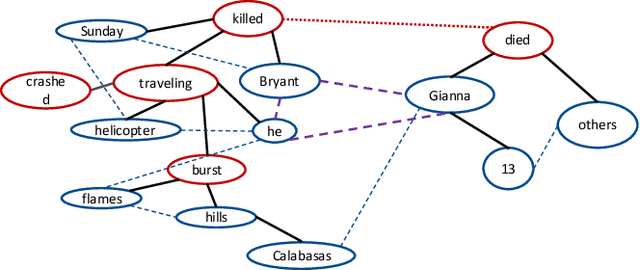
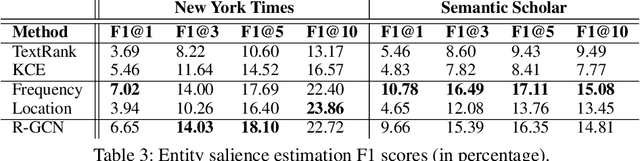
Salience Estimation aims to predict term importance in documents. Due to few existing human-annotated datasets and the subjective notion of salience, previous studies typically generate pseudo-ground truth for evaluation. However, our investigation reveals that the evaluation protocol proposed by prior work is difficult to replicate, thus leading to few follow-up studies existing. Moreover, the evaluation process is problematic: the entity linking tool used for entity matching is very noisy, while the ignorance of event argument for event evaluation leads to boosted performance. In this work, we propose a light yet practical entity and event salience estimation evaluation protocol, which incorporates the more reliable syntactic dependency parser. Furthermore, we conduct a comprehensive analysis among popular entity and event definition standards, and present our own definition for the Salience Estimation task to reduce noise during the pseudo-ground truth generation process. Furthermore, we construct dependency-based heterogeneous graphs to capture the interactions of entities and events. The empirical results show that both baseline methods and the novel GNN method utilizing the heterogeneous graph consistently outperform the previous SOTA model in all proposed metrics.
Competence-Level Prediction and Resume & Job Description Matching Using Context-Aware Transformer Models
Nov 05, 2020
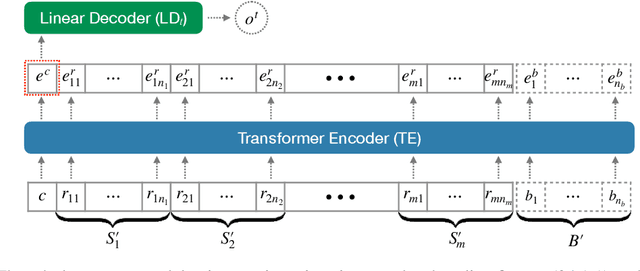
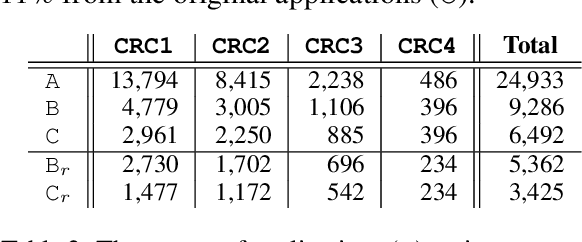
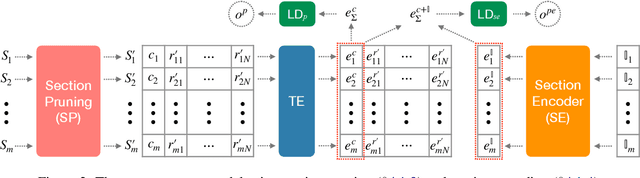
This paper presents a comprehensive study on resume classification to reduce the time and labor needed to screen an overwhelming number of applications significantly, while improving the selection of suitable candidates. A total of 6,492 resumes are extracted from 24,933 job applications for 252 positions designated into four levels of experience for Clinical Research Coordinators (CRC). Each resume is manually annotated to its most appropriate CRC position by experts through several rounds of triple annotation to establish guidelines. As a result, a high Kappa score of 61% is achieved for inter-annotator agreement. Given this dataset, novel transformer-based classification models are developed for two tasks: the first task takes a resume and classifies it to a CRC level (T1), and the second task takes both a resume and a job description to apply and predicts if the application is suited to the job T2. Our best models using section encoding and multi-head attention decoding give results of 73.3% to T1 and 79.2% to T2. Our analysis shows that the prediction errors are mostly made among adjacent CRC levels, which are hard for even experts to distinguish, implying the practical value of our models in real HR platforms.
Revealing the Myth of Higher-Order Inference in Coreference Resolution
Sep 28, 2020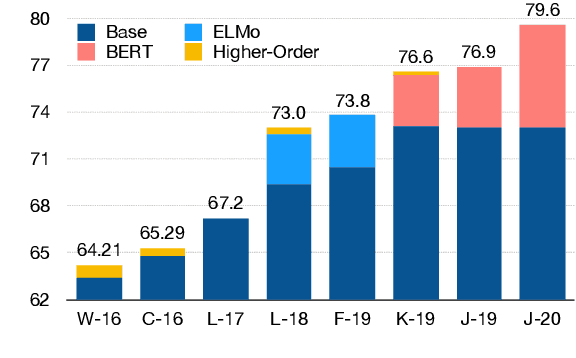
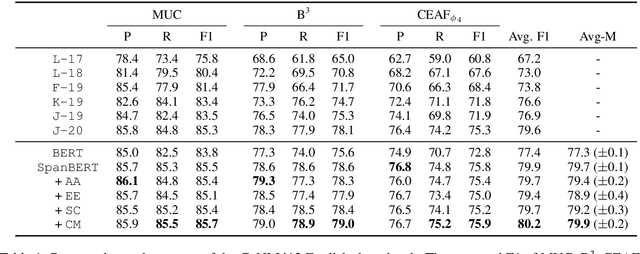

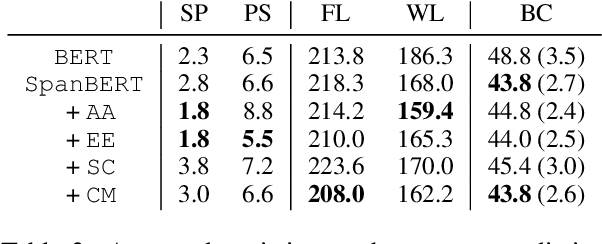
This paper analyzes the impact of higher-order inference (HOI) on the task of coreference resolution. HOI has been adapted by almost all recent coreference resolution models without taking much investigation on its true effectiveness over representation learning. To make a comprehensive analysis, we implement an end-to-end coreference system as well as four HOI approaches, attended antecedent, entity equalization, span clustering, and cluster merging, where the latter two are our original methods. We find that given a high-performing encoder such as SpanBERT, the impact of HOI is negative to marginal, providing a new perspective of HOI to this task. Our best model using cluster merging shows the Avg-F1 of 80.2 on the CoNLL 2012 shared task dataset in English.
Emora: An Inquisitive Social Chatbot Who Cares For You
Sep 10, 2020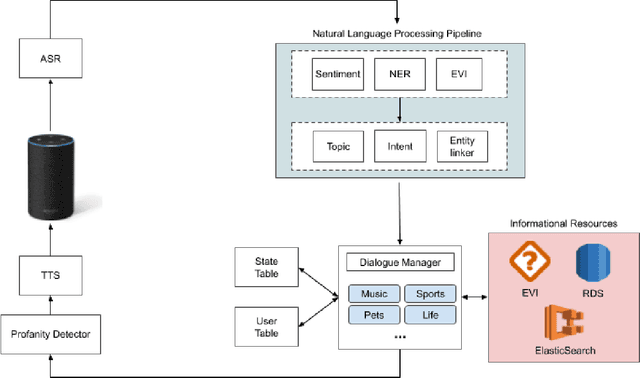
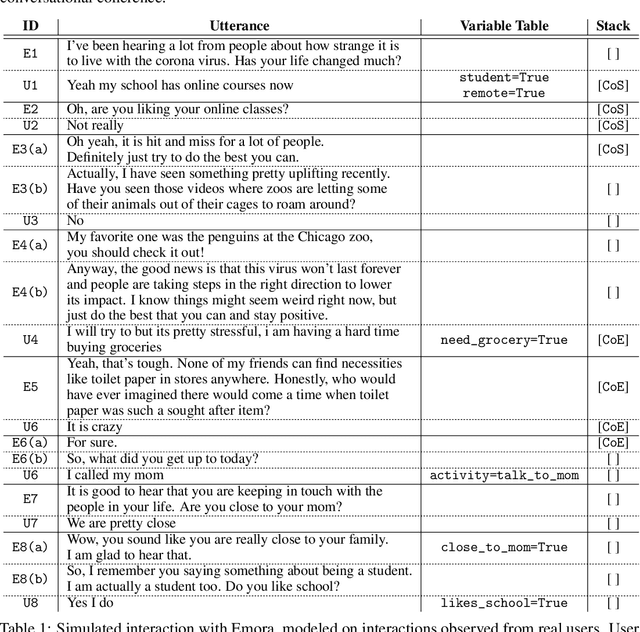
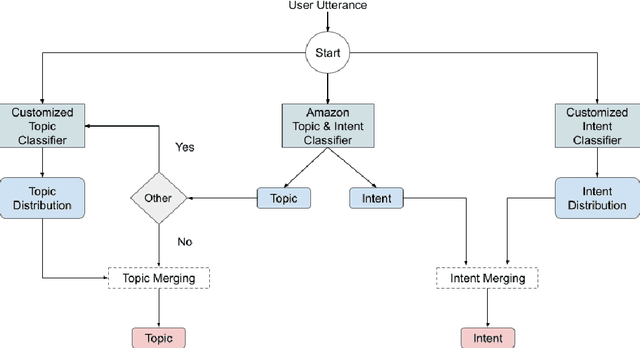
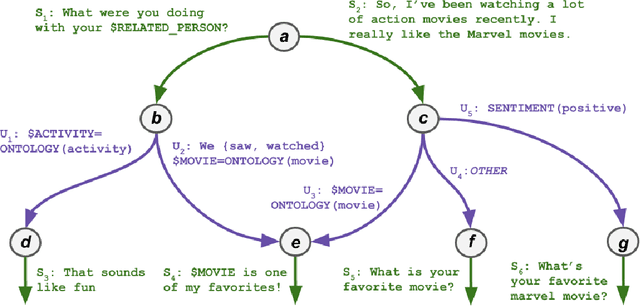
Inspired by studies on the overwhelming presence of experience-sharing in human-human conversations, Emora, the social chatbot developed by Emory University, aims to bring such experience-focused interaction to the current field of conversational AI. The traditional approach of information-sharing topic handlers is balanced with a focus on opinion-oriented exchanges that Emora delivers, and new conversational abilities are developed that support dialogues that consist of a collaborative understanding and learning process of the partner's life experiences. We present a curated dialogue system that leverages highly expressive natural language templates, powerful intent classification, and ontology resources to provide an engaging and interesting conversational experience to every user.
XD at SemEval-2020 Task 12: Ensemble Approach to Offensive Language Identification in Social Media Using Transformer Encoders
Jul 21, 2020
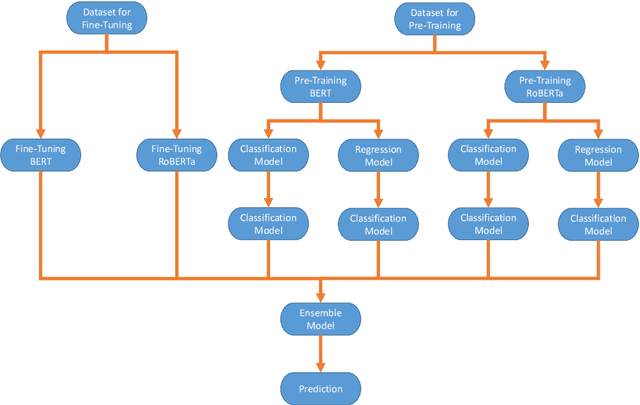
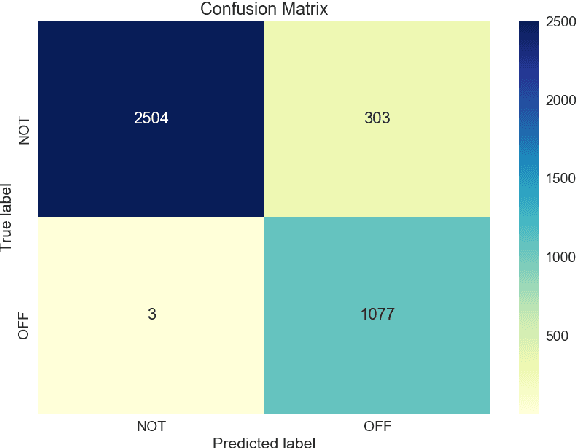
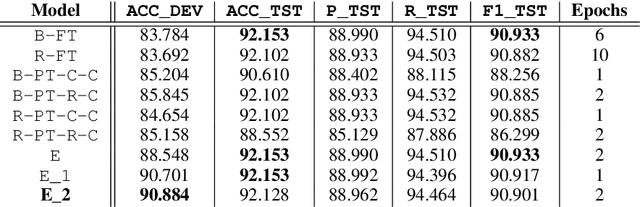
This paper presents six document classification models using the latest transformer encoders and a high-performing ensemble model for a task of offensive language identification in social media. For the individual models, deep transformer layers are applied to perform multi-head attentions. For the ensemble model, the utterance representations taken from those individual models are concatenated and fed into a linear decoder to make the final decisions. Our ensemble model outperforms the individual models and shows up to 8.6% improvement over the individual models on the development set. On the test set, it achieves macro-F1 of 90.9% and becomes one of the high performing systems among 85 participants in the sub-task A of this shared task. Our analysis shows that although the ensemble model significantly improves the accuracy on the development set, the improvement is not as evident on the test set.
Emora STDM: A Versatile Framework for Innovative Dialogue System Development
Jun 11, 2020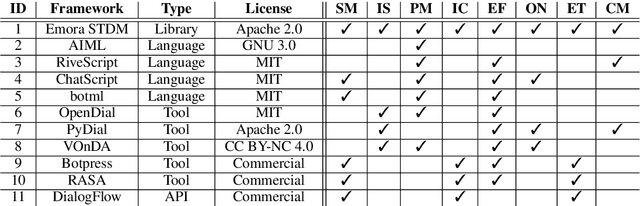
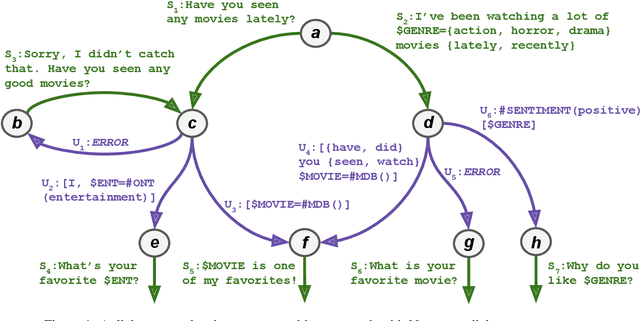
This demo paper presents Emora STDM (State Transition Dialogue Manager), a dialogue system development framework that provides novel workflows for rapid prototyping of chat-based dialogue managers as well as collaborative development of complex interactions. Our framework caters to a wide range of expertise levels by supporting interoperability between two popular approaches, state machine and information state, to dialogue management. Our Natural Language Expression package allows seamless integration of pattern matching, custom NLP modules, and database querying, that makes the workflows much more efficient. As a user study, we adopt this framework to an interdisciplinary undergraduate course where students with both technical and non-technical backgrounds are able to develop creative dialogue managers in a short period of time.
Towards Unified Dialogue System Evaluation: A Comprehensive Analysis of Current Evaluation Protocols
Jun 10, 2020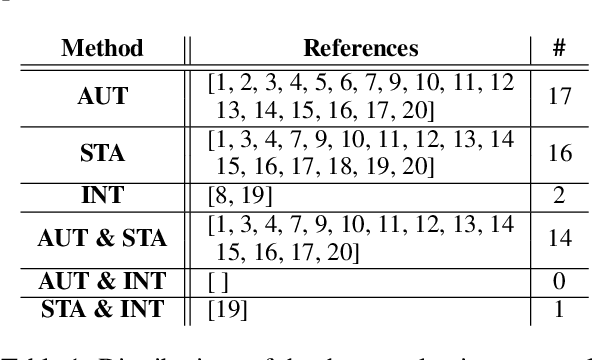
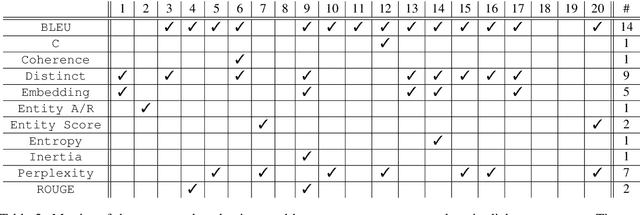
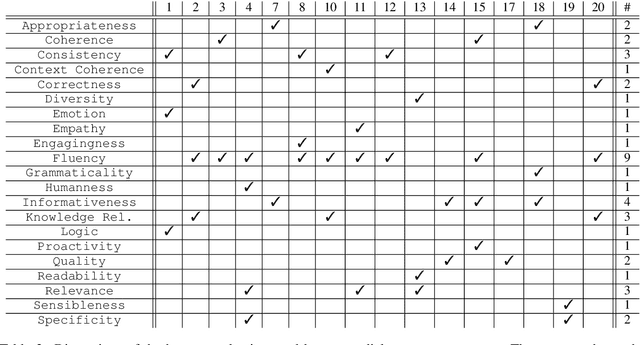
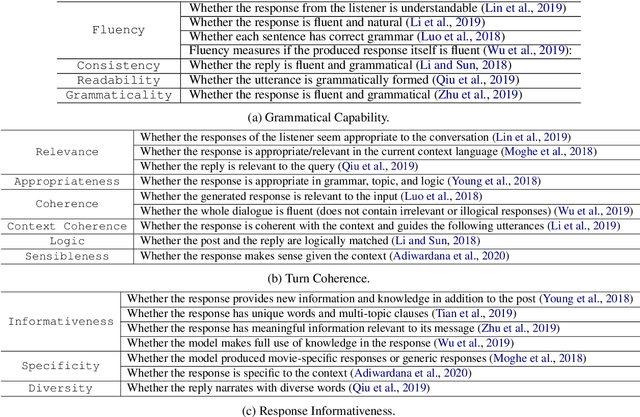
As conversational AI-based dialogue management has increasingly become a trending topic, the need for a standardized and reliable evaluation procedure grows even more pressing. The current state of affairs suggests various evaluation protocols to assess chat-oriented dialogue management systems, rendering it difficult to conduct fair comparative studies across different approaches and gain an insightful understanding of their values. To foster this research, a more robust evaluation protocol must be set in place. This paper presents a comprehensive synthesis of both automated and human evaluation methods on dialogue systems, identifying their shortcomings while accumulating evidence towards the most effective evaluation dimensions. A total of 20 papers from the last two years are surveyed to analyze three types of evaluation protocols: automated, static, and interactive. Finally, the evaluation dimensions used in these papers are compared against our expert evaluation on the system-user dialogue data collected from the Alexa Prize 2020.