 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Asymptotic Analysis of Online Local Private Learning with SGD
Jul 09, 2025



Differentially Private Stochastic Gradient Descent (DP-SGD) has been widely used for solving optimization problems with privacy guarantees in machine learning and statistics. Despite this, a systematic non-asymptotic convergence analysis for DP-SGD, particularly in the context of online problems and local differential privacy (LDP) models, remains largely elusive. Existing non-asymptotic analyses have focused on non-private optimization methods, and hence are not applicable to privacy-preserving optimization problems. This work initiates the analysis to bridge this gap and opens the door to non-asymptotic convergence analysis of private optimization problems. A general framework is investigated for the online LDP model in stochastic optimization problems. We assume that sensitive information from individuals is collected sequentially and aim to estimate, in real-time, a static parameter that pertains to the population of interest. Most importantly, we conduct a comprehensive non-asymptotic convergence analysis of the proposed estimators in finite-sample situations, which gives their users practical guidelines regarding the effect of various hyperparameters, such as step size, parameter dimensions, and privacy budgets, on convergence rates. Our proposed estimators are validated in the theoretical and practical realms by rigorous mathematical derivations and carefully constructed numerical experiments.
Online federated learning framework for classification
Mar 19, 2025



In this paper, we develop a novel online federated learning framework for classification, designed to handle streaming data from multiple clients while ensuring data privacy and computational efficiency. Our method leverages the generalized distance-weighted discriminant technique, making it robust to both homogeneous and heterogeneous data distributions across clients. In particular, we develop a new optimization algorithm based on the Majorization-Minimization principle, integrated with a renewable estimation procedure, enabling efficient model updates without full retraining. We provide a theoretical guarantee for the convergence of our estimator, proving its consistency and asymptotic normality under standard regularity conditions. In addition, we establish that our method achieves Bayesian risk consistency, ensuring its reliability for classification tasks in federated environments. We further incorporate differential privacy mechanisms to enhance data security, protecting client information while maintaining model performance. Extensive numerical experiments on both simulated and real-world datasets demonstrate that our approach delivers high classification accuracy, significant computational efficiency gains, and substantial savings in data storage requirements compared to existing methods.
Sampling-guided Heterogeneous Graph Neural Network with Temporal Smoothing for Scalable Longitudinal Data Imputation
Nov 07, 2024



In this paper, we propose a novel framework, the Sampling-guided Heterogeneous Graph Neural Network (SHT-GNN), to effectively tackle the challenge of missing data imputation in longitudinal studies. Unlike traditional methods, which often require extensive preprocessing to handle irregular or inconsistent missing data, our approach accommodates arbitrary missing data patterns while maintaining computational efficiency. SHT-GNN models both observations and covariates as distinct node types, connecting observation nodes at successive time points through subject-specific longitudinal subnetworks, while covariate-observation interactions are represented by attributed edges within bipartite graphs. By leveraging subject-wise mini-batch sampling and a multi-layer temporal smoothing mechanism, SHT-GNN efficiently scales to large datasets, while effectively learning node representations and imputing missing data. Extensive experiments on both synthetic and real-world datasets, including the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset, demonstrate that SHT-GNN significantly outperforms existing imputation methods, even with high missing data rates. The empirical results highlight SHT-GNN's robust imputation capabilities and superior performance, particularly in the context of complex, large-scale longitudinal data.
Word Embeddings via Causal Inference: Gender Bias Reducing and Semantic Information Preserving
Dec 09, 2021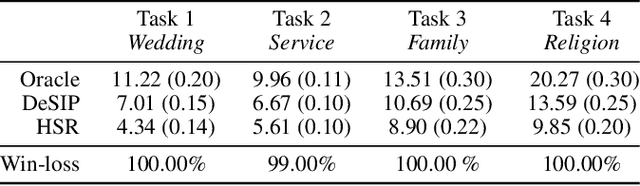
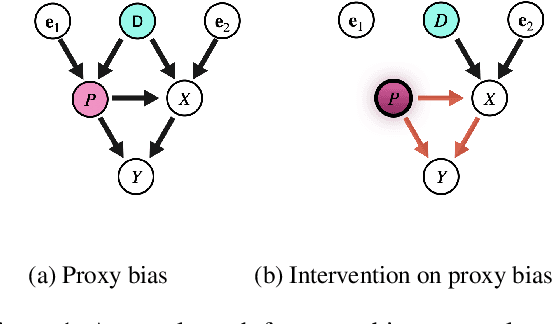
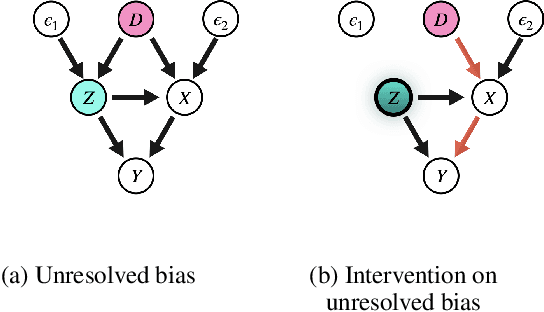
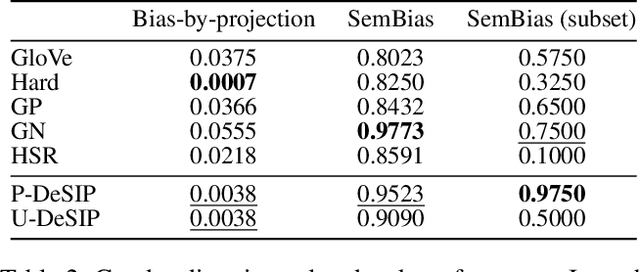
With widening deployments of natural language processing (NLP) in daily life, inherited social biases from NLP models have become more severe and problematic. Previous studies have shown that word embeddings trained on human-generated corpora have strong gender biases that can produce discriminative results in downstream tasks. Previous debiasing methods focus mainly on modeling bias and only implicitly consider semantic information while completely overlooking the complex underlying causal structure among bias and semantic components. To address these issues, we propose a novel methodology that leverages a causal inference framework to effectively remove gender bias. The proposed method allows us to construct and analyze the complex causal mechanisms facilitating gender information flow while retaining oracle semantic information within word embeddings. Our comprehensive experiments show that the proposed method achieves state-of-the-art results in gender-debiasing tasks. In addition, our methods yield better performance in word similarity evaluation and various extrinsic downstream NLP tasks.