 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear Sample-Optimal Reduction-based Policy Learning for Average Reward MDP
Dec 01, 2022
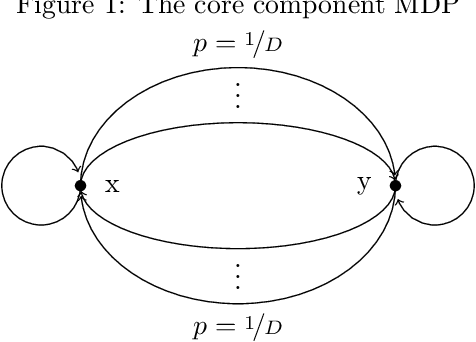
This work considers the sample complexity of obtaining an $\varepsilon$-optimal policy in an average reward Markov Decision Process (AMDP), given access to a generative model (simulator). When the ground-truth MDP is weakly communicating, we prove an upper bound of $\widetilde O(H \varepsilon^{-3} \ln \frac{1}{\delta})$ samples per state-action pair, where $H := sp(h^*)$ is the span of bias of any optimal policy, $\varepsilon$ is the accuracy and $\delta$ is the failure probability. This bound improves the best-known mixing-time-based approaches in [Jin & Sidford 2021], which assume the mixing-time of every deterministic policy is bounded. The core of our analysis is a proper reduction bound from AMDP problems to discounted MDP (DMDP) problems, which may be of independent interests since it allows the application of DMDP algorithms for AMDP in other settings. We complement our upper bound by proving a minimax lower bound of $\Omega(|\mathcal S| |\mathcal A| H \varepsilon^{-2} \ln \frac{1}{\delta})$ total samples, showing that a linear dependent on $H$ is necessary and that our upper bound matches the lower bound in all parameters of $(|\mathcal S|, |\mathcal A|, H, \ln \frac{1}{\delta})$ up to some logarithmic factors.