 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSato: Contextual Semantic Type Detection in Tables
Nov 14, 2019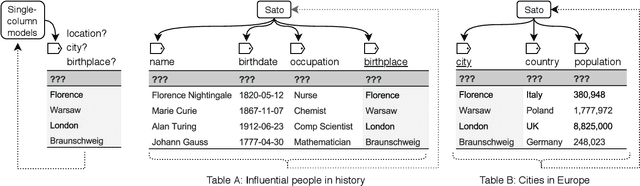

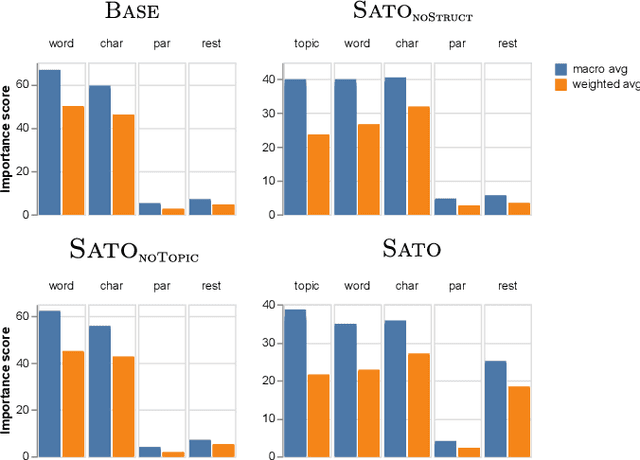
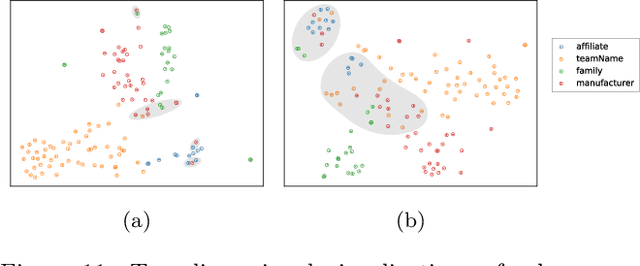
Detecting the semantic types of data columns in relational tables is important for various data preparation and information retrieval tasks such as data cleaning, schema matching, data discovery, and semantic search. However, existing detection approaches either perform poorly with dirty data, support only a limited number of semantic types, fail to incorporate the table context of columns or rely on large sample sizes in the training data. We introduce Sato, a hybrid machine learning model to automatically detect the semantic types of columns in tables, exploiting the signals from the context as well as the column values. Sato combines a deep learning model trained on a large-scale table corpus with topic modeling and structured prediction to achieve support-weighted and macro average F1 scores of 0.901 and 0.973, respectively, exceeding the state-of-the-art performance by a significant margin. We extensively analyze the overall and per-type performance of Sato, discussing how individual modeling components, as well as feature categories, contribute to its performance.
Voyageur: An Experiential Travel Search Engine
Mar 04, 2019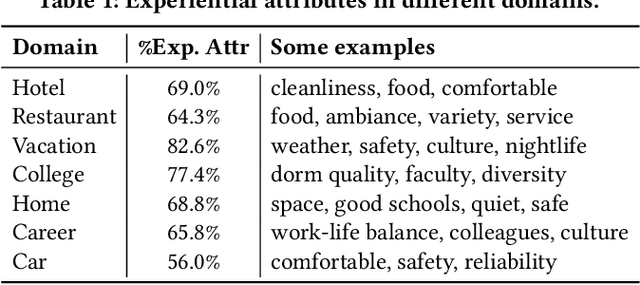
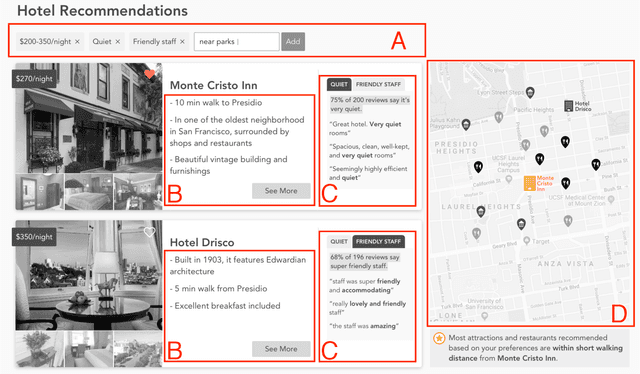
We describe Voyageur, which is an application of experiential search to the domain of travel. Unlike traditional search engines for online services, experiential search focuses on the experiential aspects of the service under consideration. In particular, Voyageur needs to handle queries for subjective aspects of the service (e.g., quiet hotel, friendly staff) and combine these with objective attributes, such as price and location. Voyageur also highlights interesting facts and tips about the services the user is considering to provide them with further insights into their choices.
TextBugger: Generating Adversarial Text Against Real-world Applications
Dec 13, 2018
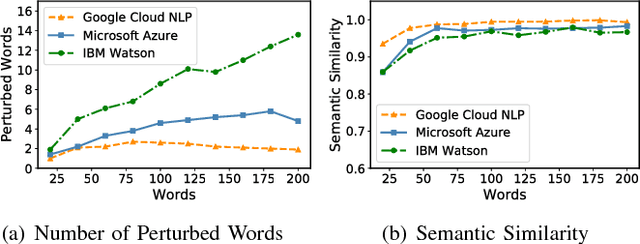
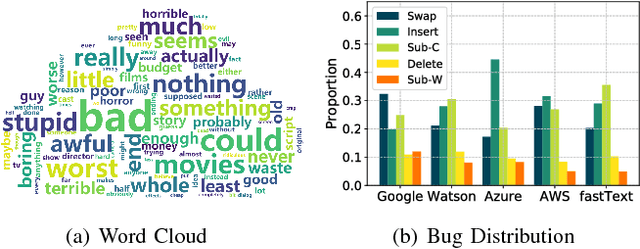
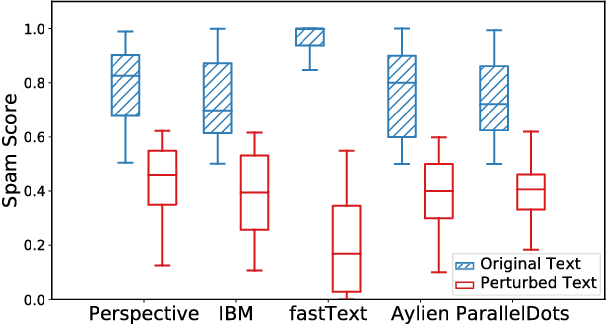
Deep Learning-based Text Understanding (DLTU) is the backbone technique behind various applications, including question answering, machine translation, and text classification. Despite its tremendous popularity, the security vulnerabilities of DLTU are still largely unknown, which is highly concerning given its increasing use in security-sensitive applications such as sentiment analysis and toxic content detection. In this paper, we show that DLTU is inherently vulnerable to adversarial text attacks, in which maliciously crafted texts trigger target DLTU systems and services to misbehave. Specifically, we present TextBugger, a general attack framework for generating adversarial texts. In contrast to prior works, TextBugger differs in significant ways: (i) effective -- it outperforms state-of-the-art attacks in terms of attack success rate; (ii) evasive -- it preserves the utility of benign text, with 94.9\% of the adversarial text correctly recognized by human readers; and (iii) efficient -- it generates adversarial text with computational complexity sub-linear to the text length. We empirically evaluate TextBugger on a set of real-world DLTU systems and services used for sentiment analysis and toxic content detection, demonstrating its effectiveness, evasiveness, and efficiency. For instance, TextBugger achieves 100\% success rate on the IMDB dataset based on Amazon AWS Comprehend within 4.61 seconds and preserves 97\% semantic similarity. We further discuss possible defense mechanisms to mitigate such attack and the adversary's potential countermeasures, which leads to promising directions for further research.
Norm-Ranging LSH for Maximum Inner Product Search
Oct 22, 2018


Neyshabur and Srebro proposed Simple-LSH, which is the state-of-the-art hashing method for maximum inner product search (MIPS) with performance guarantee. We found that the performance of Simple-LSH, in both theory and practice, suffers from long tails in the 2-norm distribution of real datasets. We propose Norm-ranging LSH, which addresses the excessive normalization problem caused by long tails in Simple-LSH by partitioning a dataset into multiple sub-datasets and building a hash index for each sub-dataset independently. We prove that Norm-ranging LSH has lower query time complexity than Simple-LSH. We also show that the idea of partitioning the dataset can improve other hashing based methods for MIPS. To support efficient query processing on the hash indexes of the sub-datasets, a novel similarity metric is formulated. Experiments show that Norm-ranging LSH achieves an order of magnitude speedup over Simple-LSH for the same recall, thus significantly benefiting applications that involve MIPS.