 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColosseum V2: Benchmarking Generalization for Vision Language Action Models
May 26, 2026Vision-Language-Action (VLA) models demonstrate promising generalization in robotic manipulation, driven by advances in large-scale vision and language pre-training. This progress can be misleading. Despite the zero-shot perception and language capabilities of VLAs, their overall task performance often degrades under distribution shifts, revealing gaps in how these systems translate high-level understanding into robust behavior. To systematically study this gap, we introduce Colosseum V2, a large-scale simulation benchmark for evaluating VLA generalization in robot learning across diverse conditions. The benchmark comprises 28 tasks spanning 13 task categories and two robot morphologies, covering a wide range of manipulation primitives and long-horizon behaviors. Built on the ManiSkill simulator, Colosseum V2 enables fast, GPU-parallelized evaluation and supports both in-domain and out-of-domain testing at scale. We evaluate state-of-the-art methods, including Action Chunking Transformers (ACT) and Pi0.5, and reveal limitations in both base performance and generalization. We demonstrate strong correlations between simulation and real-world metrics that support the ecological validity of the benchmark. By standardizing tasks, metrics, and evaluation protocols within a unified benchmark, Colosseum V2 enables reproducible and fair comparisons, reduced evaluation overhead, and accelerated progress toward general-purpose robot policies.
Rethinking the Knowledge Distillation From the Perspective of Model Calibration
Nov 03, 2021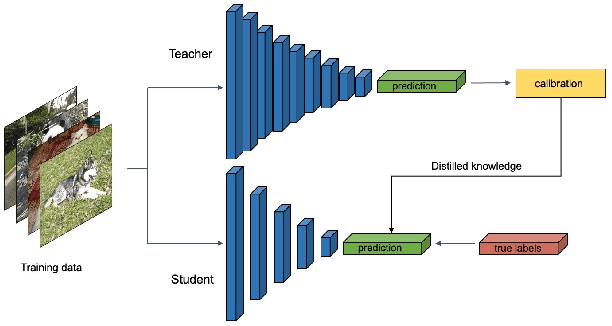
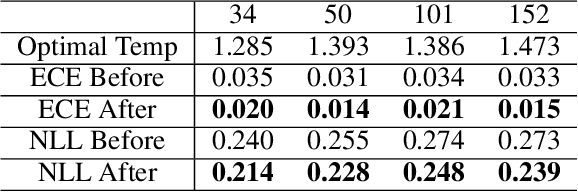
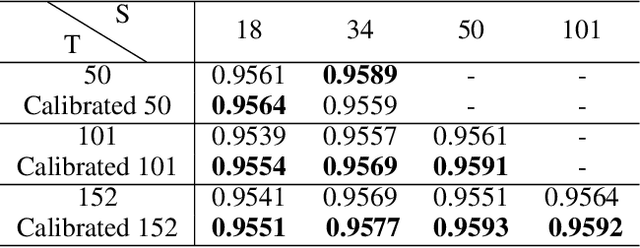
Recent years have witnessed dramatically improvements in the knowledge distillation, which can generate a compact student model for better efficiency while retaining the model effectiveness of the teacher model. Previous studies find that: more accurate teachers do not necessary make for better teachers due to the mismatch of abilities. In this paper, we aim to analysis the phenomenon from the perspective of model calibration. We found that the larger teacher model may be too over-confident, thus the student model cannot effectively imitate. While, after the simple model calibration of the teacher model, the size of the teacher model has a positive correlation with the performance of the student model.